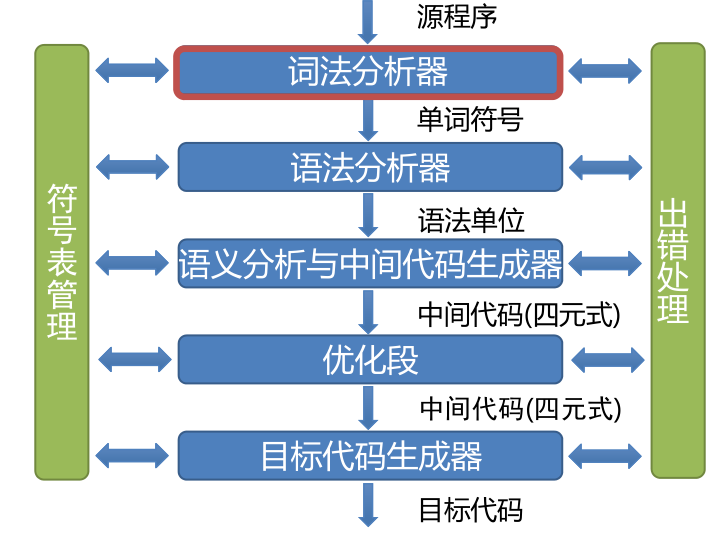
編譯程式總框
詞法分析器的設計
詞法分析的任務:
從左至右逐個字符地對源程式進行掃描,產生一個個單詞符號,
詞法分析器(Lexical Analyzer):掃描器(Scanner),執行詞法分析的程式
功能:輸入源程式、輸出單詞符號
單詞符號的種類:
-
基本字:如 begin,repeat,for,…
-
識別符號:用來表示各種名字,如變數名、陣列名和程序名
-
常數:各種型別的常數
-
運算子:+,-,*,/,…
-
界符:逗號、分號、括號和空白
-
輸出的單詞符號的表示形式
- (單詞種別,單詞自身的值)
-
單詞種別通常用整數編碼表示
- 若一個種別只有一個單詞符號,則種別編碼就代表該單詞符號,假定基本字、運算子和界符都是一符一種,
- 若一個種別有多個單詞符號,則對于每個單詞符號,給出種別編碼和自身的值,
- 識別符號單列一種;識別符號自身的值表示成按機器位元組劃分的內部碼
- 常數按型別分種;常數的值則表示成標準的二進制形式
詞法分析作為一個獨立的階段: 結構簡潔、清晰和條理化,有利于集中考慮詞法分析一些枝節問題,但不一定不作為單獨的一遍,將其處理為一個子程式
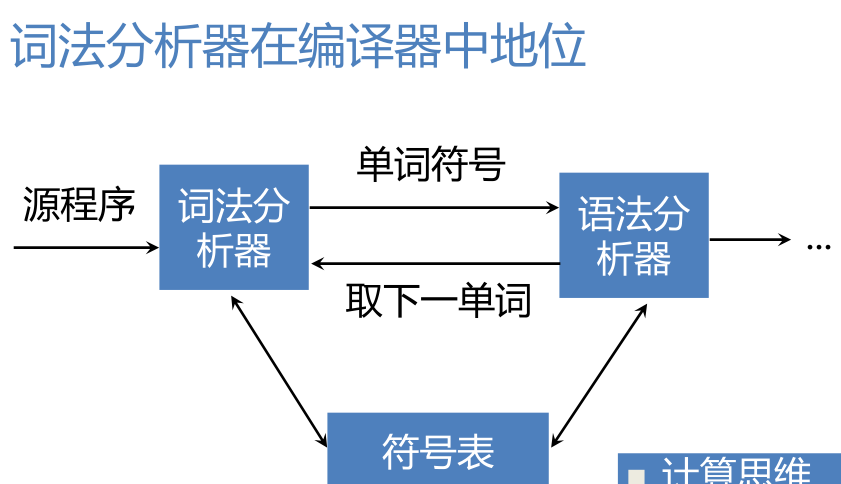
詞法分析器的結構
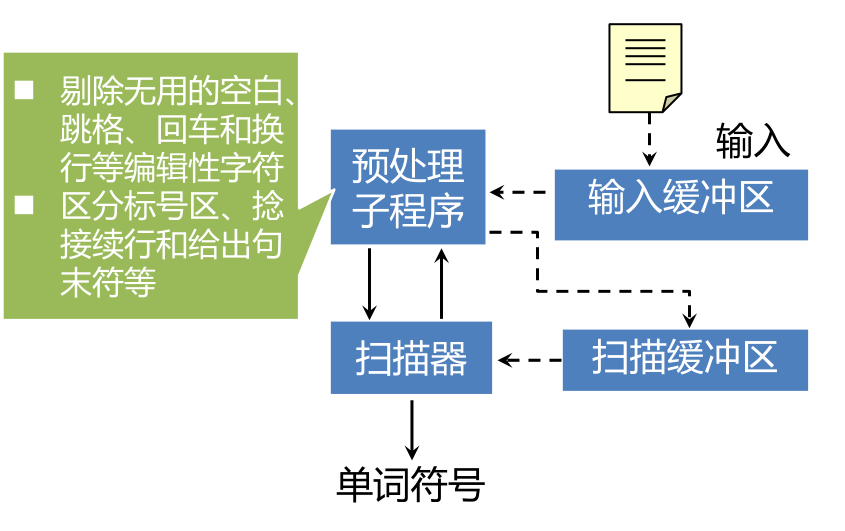
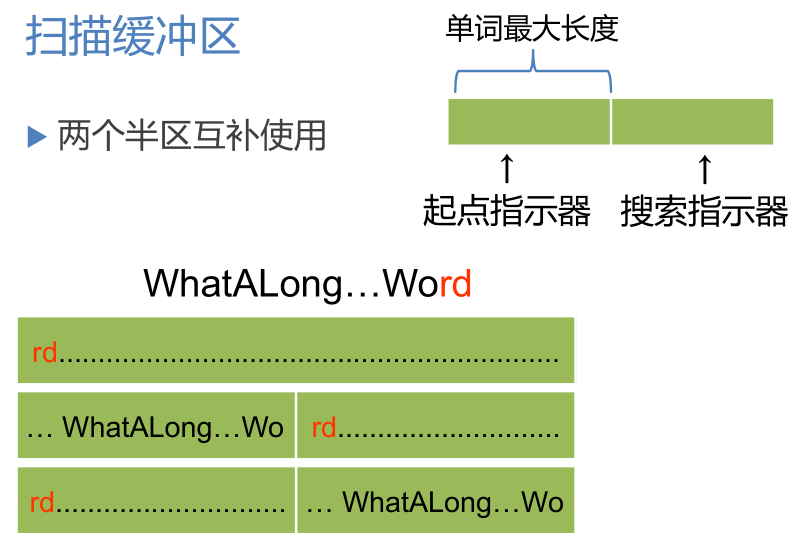
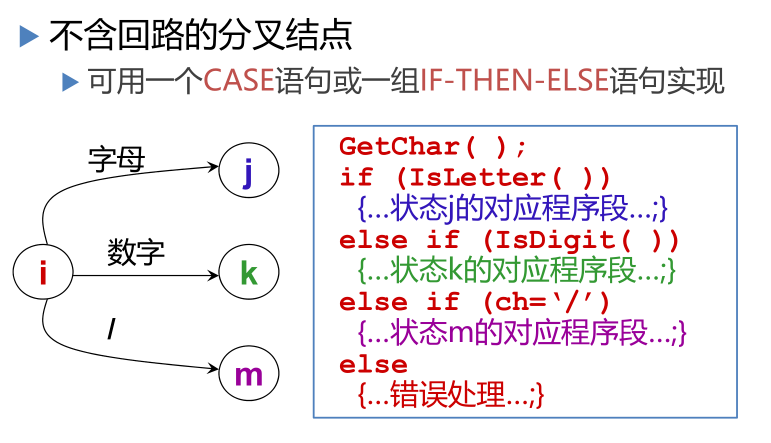
單詞符號的識別:超前搜索
識別符號識別:字母開頭的字母數字串,后跟界符或算符
常數識別:識別出算術常數并將其轉變為二進制內碼表示
算符和界符的識別:把多字符組成的算符和界符拼合成一個單詞符號
幾點限制——不必使用超前搜索
- 所有基本字都是保留字;用戶不能用它們作自己的識別符號
- 基本字作為特殊的識別符號來處理,使用保留字表
- 如果基本字、識別符號和常數(或標號)之間沒有確定的運算子或界符作間隔,則必須使用一個空白符作間隔
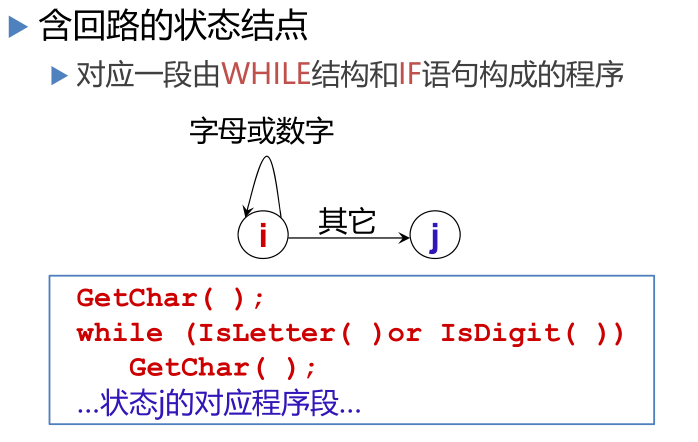
狀態轉換圖
狀態轉換圖是一張有限方向圖,結點代表狀態,用圓圈表示,狀態之間用箭弧連結,箭弧上的標記(字符)代表射出結狀態下可能出現的輸入字符或字符類,一張轉換圖只包含有限個狀態,其中有一個為初態,至少要有一個終態,狀態轉換圖可用于識別(或接受)一定的字串若存在一條從初態到某一終態的道路,且這條路上所有弧上的標記符連接成的字等于α,則稱α被該狀態轉換圖所識別(接受)
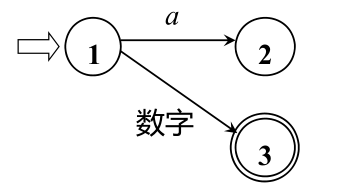
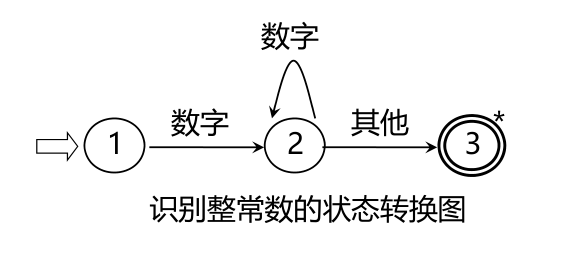
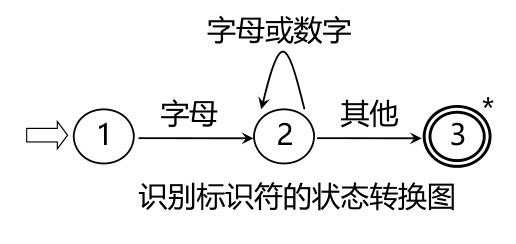
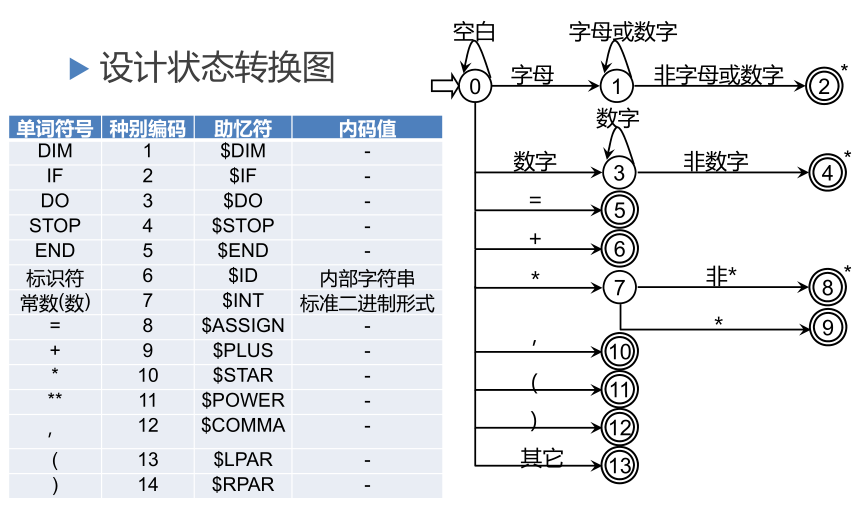
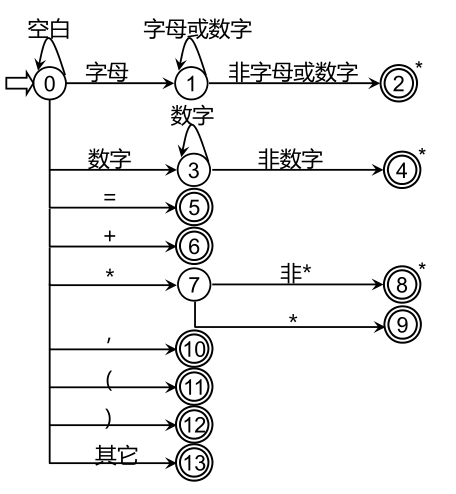
狀態轉換圖的實作

全域變數與程序
- ch 字符變數,存放最新讀入的源程式字符
- strToken 字符陣列,存放構成單詞符號的字串
- GetChar 子程式程序,把下一個字符讀入到 ch 中
- GetBC 子程式程序,跳過空白符,直至 ch 中讀入一非空白符
- Concat 子程式,把ch中的字符連接到 strToken
- IsLetter和 IsDisgital 布爾函式,判斷ch中字符是否為字母和數字
- Reserve 整型函式,對于 strToken 中的字串查找保留字表,若它是保留字則給出它的編碼,否則回送0
- Retract 子程式,把搜索指標回呼一個字符位置
- InsertId 整型函式,將strToken中的識別符號插入符號表,回傳符號表指標
- InsertConst 整型函式程序,將strToken中的常數插入常數表,回傳常數表指標
詞法分析器的實作

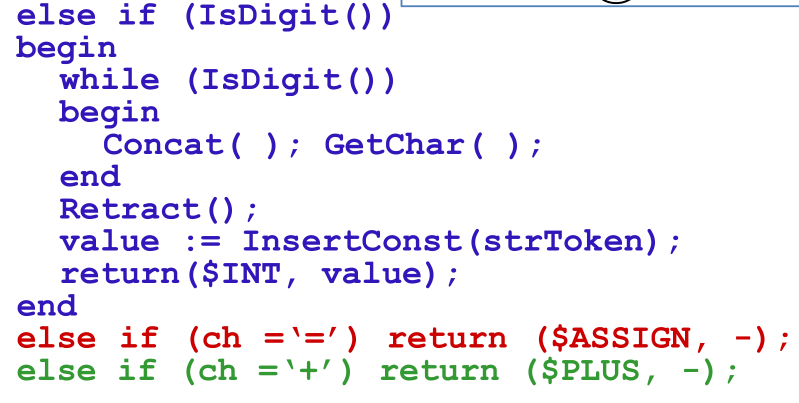

將狀態圖的代碼一般
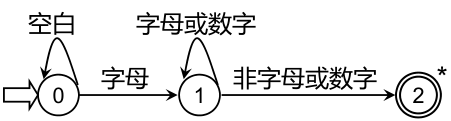
變數curState用于保存現有的狀態,用二維陣串列示狀態圖:stateTrans[state][ch]

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/86856.html
標籤:其他
上一篇:編譯原理的基本概念
下一篇:HTTPS原理及流程