原文 | https://mp.weixin.qq.com/s/NV3ThVwhM5dTIDQAWITSQQ
概率(probabilty)和統計(statistics)是兩個相近的概念,其實研究的問題剛好相反,
概率是使用一個已知引數的模型去預測這個模型所產生的結果,并研究結果的相關數字特征,比如期望、方差等,假設現在已知一個射擊運動員的得分服從均值為8.2,方差為1.5的正態分布,就可以對這名運動員下一次射擊的得分情況有個大致的預估,
統計與概率正好相反,是先有一堆資料,然后利用這些資料推測出模型和模型的引數,現在來了一名陌生的運動員,我們對他一無所知,不過他宣稱自己是一名優秀的職業運動員,在進行了一系列射擊測驗后,教練組收集到了一批這名運動員的成績,通過觀察資料,認為他的成績符合正態分布(也就是確定了模型),之后再進一步通過資料推測模型引數的具體值,對于正態分布來說,引數是均值和方差,
這樣看來,我們碰到的大多數問題都是統計問題,雖然概率是隨機事件的客觀規律,但遺憾的是,這個規律總是作為未知量出現的,作為補償,我們擁有一系列資料樣本,雖然這些樣本可能遠小于整體,但仍然可以以點帶面,根據這些樣本對整體引數進行估計,得出關于整體概率分布的近似值,這個根據樣本對總體引數進行估計的程序就是引數估計,根據引數性質不同,可分為點估計和區間估計,
點估計就是用樣本統計量的某一具體數值直接推斷未知的總體引數,得到的是一個具體的引數值,我們之前講過的矩估計、最大似然估計、貝葉斯估計都是點估計,
我們以矩估計為例,重新看看怎樣由樣本估計總體,
總體數量和樣本數量
我們經常用n表示總體的數量,究竟什么才算總體呢?
總體總是給人以“多”的概念,但事實并非如此,不同問題的“總體”數量可能相差很遠,比如一個啤酒廠一年生產的罐裝啤酒是1000萬,一個班級的學生數是60人,無論是1000萬還是60,都是總體,用n表示總體的數量,
既然是用樣本估計總體,當然少不了抽樣,關于抽樣可參考:?資料分析(4)——閑話抽樣 | 看似公平的隨機抽樣是否真的公平?, 用m表示樣本的數量,
估計總體的均值
醫生的判斷很大程度依賴于血液檢測的結果,從抽血結束到取得報告單需要一段時間,這段時間并不確定,也許運氣較好,十幾分鐘就拿到了,也可能等上一小時,現在得到了一組樣本,X = {x1, x2, ……, xm},其中每個資料代表了一名患者取得報告單前的等待時間,我們的目標是根據這組樣本對整體的平均等待時間做一個估計,
計算方式很簡單,只需要計算樣本的均值就可以了:
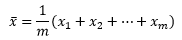
我們認為樣本的分布與整體的分布相似,這個均值是根據目前已知的資料對總體的最佳近似描述,這種用樣本均值估計總體均值的方法稱為矩估計,估計的結果是總體均值的點估計量,
下面的代碼展現了整體分布和抽樣分布的關系:
import numpy as np import matplotlib.pyplot as plt from scipy import stats fig = plt.figure(figsize=(10, 5)) plt.subplots_adjust(hspace=0.5) # 調整子圖之間的上下邊距 mu, sigma_square = 30, 5 # 均值和方差 sigma = sigma_square ** 0.5 # 標準差 xs = np.arange(15, 45, 0.5) ys = stats.norm.pdf(xs, mu, sigma) ax = fig.add_subplot(2, 2, 1) ax.plot(xs, ys, label='密度曲線') ax.vlines(mu, 0, 0.2, linestyles='--', colors='r', label='均值') ax.legend(loc='upper right') ax.set_xlabel('X') ax.set_ylabel('pdf') ax.set_title('X~N($\mu$, $\sigma^2$), $\mu$={0}, $\sigma^2$={1}'.format(mu, sigma_square)) for i in [1, 2, 3]: m = 10 ** i # 樣本數量 np.random.seed(m) X = stats.norm.rvs(loc=mu, scale=sigma, size=m) # 生成m個符合正態分布的隨機變數 X = np.trunc(X) # 對資料取整 mu_x = X.mean() # 樣本均值 ax = fig.add_subplot(2, 2, i + 1) ax.hist(X, bins=40) ax.set_xlabel('X') ax.set_ylabel('頻度') ax.set_title('m={0},樣本均值={1}'.format(m, mu_x)) plt.rcParams['font.sans-serif'] = ['SimHei'] # 用來正常顯示中文標簽 # plt.rcParams['axes.unicode_minus'] = False # 解決中文下的坐標軸負號顯示問題 plt.show()
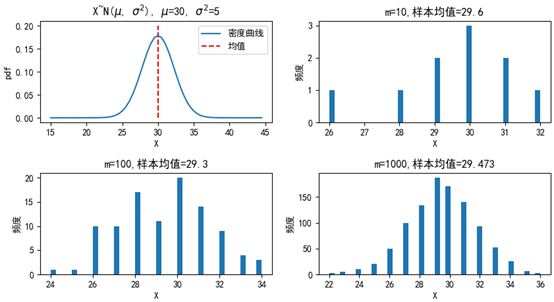
可以看到,抽取的樣本越多,樣本的分布越接近整體的分布,這里有問題的是均值的符號,在各種資料中一會是μ,一會是戴帽子的μ,一會是x拔,到呼叫哪個?

過去我們一直說某些問題符合X~N(μ, σ2)的分布,這里μ是總體均值;在最大似然估計中得出的結果用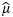 表示,說明這是通過樣本對整體均值的一個點估計量,
表示,說明這是通過樣本對整體均值的一個點估計量,
估計總體的方差
假設我們已經預先計算出了均值的點估計量,是否可以像計算總體方差一樣計算樣本方差呢?
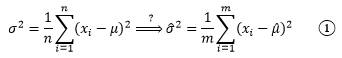
從上面的整體分布圖可以看到,大部分資料集中在均值附近,極端值出現的概率很低,這意味著對于抽樣來說,樣本數越小,抽到極端數值的可能性就越小,方差刻畫了資料相對于期望值的波動程度,由于樣本的極端值出現的概率很低,因此樣本的波動很可能低于總體的波動,方差較整體方差更小,為了應對這種情況,我們經常看到的是另一個計算樣本方差的公式:
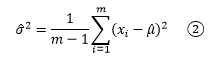
a/(m - 1)肯定大于a/m,這使得②的結果稍大于①,m的值越小,①和②的差別越明顯,隨著樣本數量的增加,取得極端值的機會也變大,①和②的差別也會越來越小,將樣本的方差作為總體方差的點估計量,通常用s2表示,
值得一提的是,如果我們有m個樣本,在計算這些樣本的實際方差時,直接用①;如果是用這些樣本估計總體的方差,應該使用②,

估計總體的比例
很多人會在30分鐘之內取得報告單,同樣也有很多人要等更久,我們可以計算出樣本中成功人數(30分鐘之內拿到報告的人數)的比例,并用這個比例作為總體概率的點估計量:

到目前為止,點估計仍然很簡單,所以經常有人吐槽:概率這么簡單的玩意有啥值得研究的?
樣本出現的概率
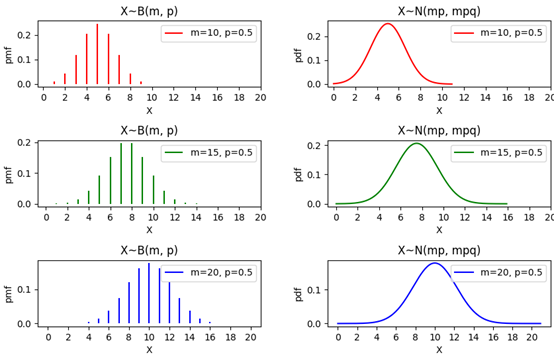
經過多年的統計分析,醫院已經明確告知,每個患者都有50%的概率會在30分鐘內拿到報告單,我們用p=50%表示總體中所有在30分鐘之內拿到報告的人數的占比,如果把一個患者在30分鐘之內拿到報告看作成功,用隨機變數X表示m個樣本中的成功數量,那么X符合引數為m和p的二項分布,X~B(m, p),即成功次數符合試驗次數和成功率的二項分布,保持試驗次數m不變,二項分布近似于均值為mp、方差為mpq的正態分布(q = 1 - p),
下面的代碼畫出了二項分布和其近似的正態分布:
import numpy as np import matplotlib.pyplot as plt from scipy import stats fig = plt.figure(figsize=(10, 6)) plt.subplots_adjust(hspace=0.8, wspace=0.3) # 調整子圖之間的邊距 p = 0.5 # 每次試驗成功的概率 q = 1 - p # 每次試驗失敗的概率 m_list = [10, 15, 20] # 試驗次數 c_list = ['r', 'g', 'b'] # 曲線顏色 m_max = max(m_list) # 二項分布 X~B(m,p) for i, m in enumerate(m_list): ax = fig.add_subplot(3, 2, i * 2 + 1) xs = np.arange(0, m + 1, 1) # 隨機變數的取值 ys = stats.binom.pmf(xs, m, p) # 二項分布 X~B(m,p) ax.vlines(xs, 0, ys, colors=c_list[i], label='m={}, p={}'.format(m, p)) ax.set_xticks(list(range(0, m_max + 1, 2))) # 重置x軸坐標 ax.set_xlabel('X') ax.set_ylabel('pmf') ax.set_title('X~B(m, p)') ax.legend(loc='upper right') # 保持二項分布試驗的次數m不變,二項分布近似于均值為mp、方差為mp(1-p)的正態分布: for i, m in enumerate(m_list): ax = fig.add_subplot(3, 2, i * 2 + 2) xs = np.arange(0, m + 1, 0.1) # 隨機變數的取值 mu, sigma = m * p, (m * p * q) ** 0.5 ys = stats.norm.pdf(xs, mu, sigma) ax.plot(xs, ys, c=c_list[i], label='m={}, p={}'.format(m, p)) ax.set_xticks(list(range(0, m_max + 1, 2))) # 重置x軸坐標 ax.set_xlabel('X') ax.set_ylabel('pdf') ax.set_title('X~N(mp, mpq)') ax.legend(loc='upper right') plt.show()
某天來了20名患者,其中有12人在30分鐘之內拿到了報告單(12個成功),根據二項分布,這種情況出現的概率是:
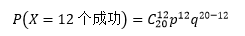
100天過去,每天都有20名患者接受驗血,xi人在30分鐘內拿到了報告,每天的樣本都對應一個概率:
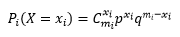
上式中所有mi的數量都是20,之所以用mi表示,是為了強調雖然每天的樣本數量一致,但樣本本身是不同的,如果將這些概率也看成隨機變數,那么這些變數也必然會符合某一個分布,只要弄清這個分布,就能回答產生某個樣本的概率,既然可以通過樣本知道樣本中成功數量的占比,那么這個分布也就等同于“樣本中成功數量的占比”的概率,比如第10天的樣本中成功數量的占比是p10=45%,我們的目標是了解p10產生的概率有多大,即P(p10)=?換句話說,我們希望知道所有Pi(X=xi)構成的分布,
我們用ps表示某個特定樣本中成功數量的占比,借助期望和方差來窺探ps的分布,一個明顯的關系是,如果總體中有50%的人可以在30分鐘內拿到報告,那么我們也同樣期望在樣本中看到這個比例,這也是我們能夠用樣本估計總體的基礎,用隨機變數X表示樣本中成功的數量,ps = X/m:
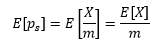
我們已經知道X~B(m, p),這里m是樣本數量,p是每個樣本成功的概率,是預先給出的,二項分布的期望是E[x] = mp,方差是Var(X)=mpq,q = 1 – p,因此:
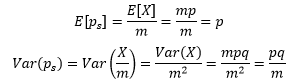
E[ps]告訴我們,樣本中成功數量的占比與整體中成功數量的占比一致;Var(ps)告訴我們,m越大,ps的方差越小,樣本中成功數量的占比越近總體中成功數量的占比,用ps來估計p越可靠,既然二項分布X~B(m, p)可以由X~N(mp, mpq)來近似,那么ps =X/m也可以由ps~N(p, pq/m)來近似,對于本例來說,p=0.25,pq/m=0.0125:
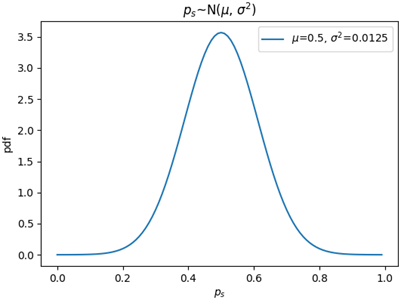
值得注意的是,比例的分布刻畫的是樣本成功數占比(即X/m)的變化情況,而二項分布刻畫的是特定數量的樣本中成功數(即X)的變化情況,比例的取值范圍是[0, 1],因此在描述ps的分布時,隨機變數的有效取值范圍是[0, 1],當m固定時,每個成功數占比都代表一個特定的樣本,我們可以借用ps的分布計算從總體中抽樣出某個固定數量樣本的概率,
連續性修正
對于二項分布來說,保持試驗次數n不變,二項分布近似于均值為np、方差為npq的正態分布,這里特別強調了“近似于”,是因為二項分布的隨機變數是離散型的,而正態分布的隨機變數是連續型,但是這又有什么關系呢?
這里先要了解一下離散型分布函式和連續型分布函式的特點,對于連續型分布來說,其分布函式是用密度函式的積分表示的:
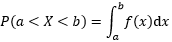
對于積分來說,a~b的區間與是否包含a點或b點沒什么關系,對于連續型隨機變數的累積概率來說:
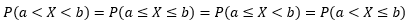
但是上式對于離散型隨機變數并不成立,下面是一個離散型分布函式,縱坐標的c.d.f是累積分布函式(cumulative distribution function)的縮寫:
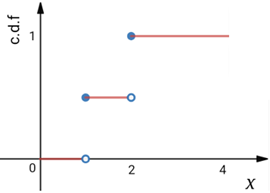
上圖向我們展示了P(X < 1) = 0,P(X ≤ 1) = 0.5,這意味著對于離散型隨機變數來說,經常有P(x ≤ a) ≠ P(x < a)的情況(并不總是不等,這要看a的取值,對于上圖來說,P(X < 1.5) = P(X ≤ 1.5)),而連續型隨機變數總是有P(x≤a) = P(x<a),
μ=50,σ2=25的正態分布X~N(μ, σ2)可以用來近似n=100,p=0.5的二項分布X~B(n, p),下圖是二者的分布函式(注意這里的曲線是分布函式,而不是密度函式):
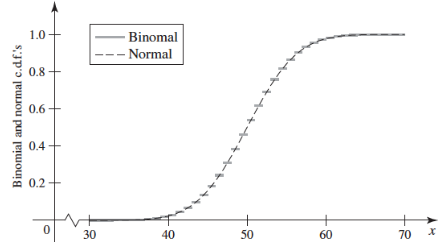
可以看出,由于二項分布的離散型隨機變數只能取到整數,因此它的分布函式是階梯狀的,而正態分布的曲線穿過了每個階梯的中心點,將階梯分成了兩部分,左半部分離散分布大于連續分布,右半部分則相反:
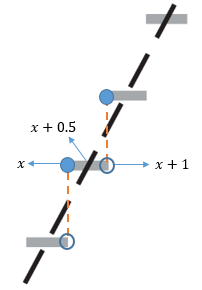
分別用FB(x)=PB(X≤x)和Fn(x)=Pn(X≤x)表示二項分布和正態分布的分布函式,對于整數x來說,在[x, x+0.5)區間內,FB(x) > Fn(x);在(x+0.5, x+1)區間內,FB(x) < Fn(x);只有在中心點,才有FB(x) = Fn(x),
現在問題來了,用正態分布去做近似的時候,如果直接用FN(x)去近似PB(X<x),那么結果會偏大;如果用FN(x)去近似PB(X≤x),則結果會偏小:
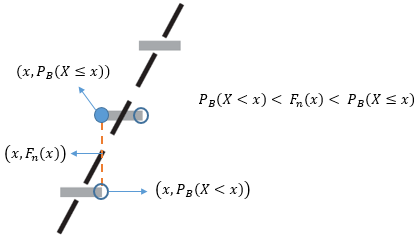
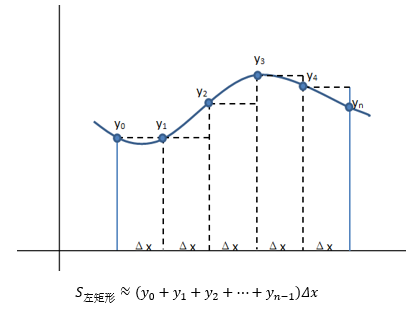
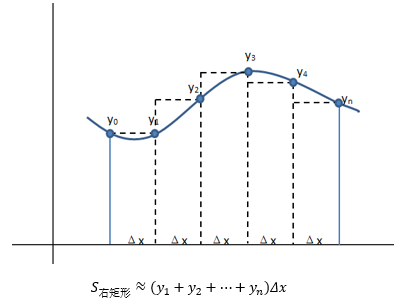
時大時小并不是個好主意,我們想要的是一個一致的近似,要么總是大,要么總是小,一個辦法是對于X的正態連續性修正為±0.5,即用FN(x+0.5)去近似PB(X < x)和PB(X ≤ x),得到的結果不會偏小;或用FN(x-0.5)去近似PB(X < x)和PB(X ≤ x),得到的結果不會偏大,這有點類似于用黎曼和計算積分時選用左矩形公式還是右矩形公式:
回顧上一節的內容,我們計算出了樣本占比ps的正態分布近似,ps的連續性修正為:
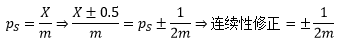
借助連續性修正可以求得:
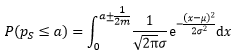
出處:微信公眾號 "我是8位的"
本文以學習、研究和分享為主,如需轉載,請聯系本人,標明作者和出處,非商業用途!
掃描二維碼關注作者公眾號“我是8位的”

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/88169.html
標籤:其他
下一篇:BIM人才三角