簡介
一致性哈希演算法在1997年由麻省理工學院的Karger等人在解決分布式Cache中提出的,設計目標是為了解決因特網中的熱點(Hot spot)問題,初衷和CARP十分類似,一致性哈希修正了CARP使用的簡單哈希演算法帶來的問題,使得DHT可以在P2P環境中真正得到應用,
現在一致性hash演算法在分布式系統中也得到了廣泛應用,研究過memcached快取資料庫的人都知道,memcached服務器端本身不提供分布式cache的一致性,而是由客戶端來提供,具體在計算一致性hash時采用如下步驟:
-
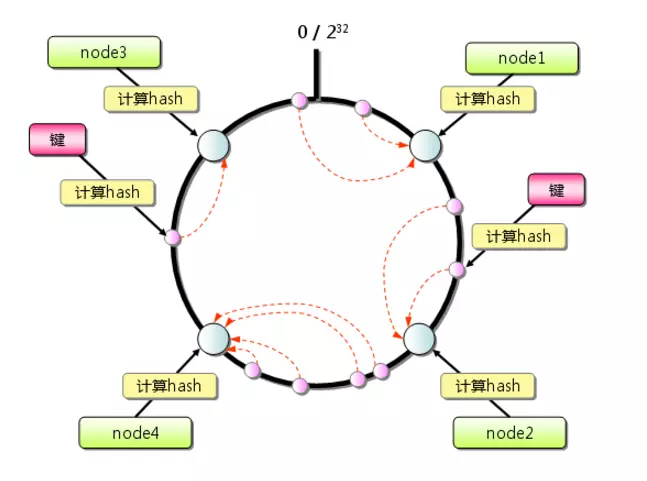
首先求出memcached服務器(節點)的哈希值,并將其配置到0~2^32的圓(continuum)上,
-
采用同樣的方法求出存盤資料的鍵的哈希值,并映射到相同的圓上,
-
從資料映射到的位置開始順時針查找,將資料保存到找到的第一個服務器上,如果超過2^32仍然找不到服務器,就會保存到第一臺memcached服務器上,
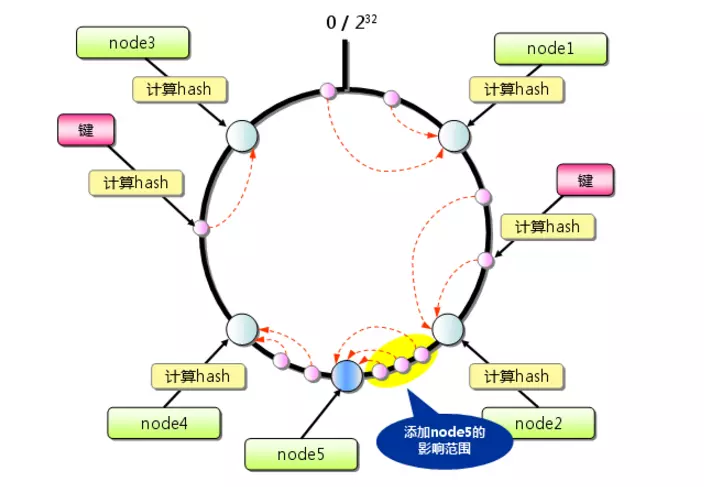
從上圖的狀態中添加一臺memcached服務器,余數分布式演算法由于保存鍵的服務器會發生巨大變化而影響快取的命中率,但Consistent Hashing中,只有在圓(continuum)上增加服務器的地點逆時針方向的第一臺服務器上的鍵會受到影響,如下圖所示:
一致性Hash性質
考慮到分布式系統每個節點都有可能失效,并且新的節點很可能動態的增加進來,如何保證當系統的節點數目發生變化時仍然能夠對外提供良好的服務,這是值得考慮的,
尤其是在設計分布式快取系統時,如果某臺服務器失效,對于整個系統來說如果不采用合適的演算法來保證一致性,那么快取于系統中的所有資料都可能會失效(即由于系統節點數目變少,客戶端在請求某一物件時需要重新計算其hash值(通常與系統中的節點數目有關),由于hash值已經改變,所以很可能找不到保存該物件的服務器節點),因此一致性hash就顯得至關重要,
良好的分布式cahce系統中的一致性hash演算法應該滿足以下幾個方面:
- 平衡性(Balance)
平衡性是指哈希的結果能夠盡可能分布到所有的緩沖中去,這樣可以使得所有的緩沖空間都得到利用,很多哈希演算法都能夠滿足這一條件,
- 單調性(Monotonicity)
單調性是指如果已經有一些內容通過哈希分派到了相應的緩沖中,又有新的緩沖區加入到系統中,那么哈希的結果應能夠保證原有已分配的內容可以被映射到新的緩沖區中去,而不會被映射到舊的緩沖集合中的其他緩沖區,
簡單的哈希演算法往往不能滿足單調性的要求,如最簡單的線性哈希
x = (ax + b) mod (P),在上式中,P表示全部緩沖的大小,不難看出,當緩沖大小發生變化時(從P1到P2),原來所有的哈希結果均會發生變化,從而不滿足單調性的要求,哈希結果的變化意味著當緩沖空間發生變化時,所有的映射關系需要在系統內全部更新,而在P2P系統內,緩沖的變化等價于Peer加入或退出系統,這一情況在P2P系統中會頻繁發生,因此會帶來極大計算和傳輸負荷,單調性就是要求哈希演算法能夠應對這種情況,
- 分散性(Spread)
在分布式環境中,終端有可能看不到所有的緩沖,而是只能看到其中的一部分,
當終端希望通過哈希程序將內容映射到緩沖上時,由于不同終端所見的緩沖范圍有可能不同,從而導致哈希的結果不一致,最終的結果是相同的內容被不同的終端映射到不同的緩沖區中,這種情況顯然是應該避免的,因為它導致相同內容被存盤到不同緩沖中去,降低了系統存盤的效率,
分散性的定義就是上述情況發生的嚴重程度,好的哈希演算法應能夠盡量避免不一致的情況發生,也就是盡量降低分散性,
- 負載(Load)
負載問題實際上是從另一個角度看待分散性問題,
既然不同的終端可能將相同的內容映射到不同的緩沖區中,那么對于一個特定的緩沖區而言,也可能被不同的用戶映射為不同的內容,
與分散性一樣,這種情況也是應當避免的,因此好的哈希演算法應能夠盡量降低緩沖的負荷,
- 平滑性(Smoothness)
平滑性是指快取服務器的數目平滑改變和快取物件的平滑改變是一致的,
原理
基本概念
一致性哈希演算法(Consistent Hashing)最早在論文《Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web》中被提出,
簡單來說,一致性哈希將整個哈希值空間組織成一個虛擬的圓環,如假設某哈希函式H的值空間為0-2^32-1(即哈希值是一個32位無符號整形),整個哈希空間環如下:
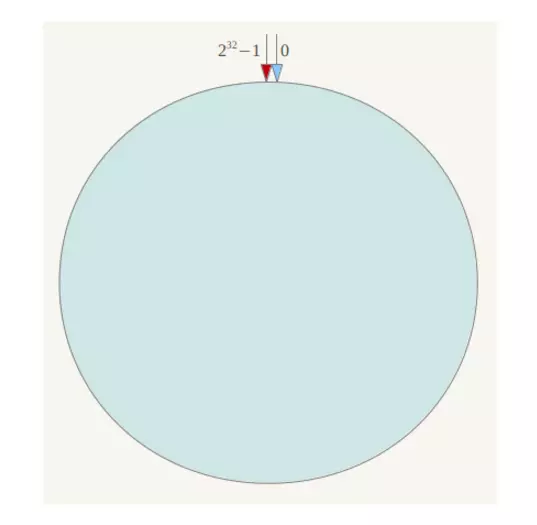
整個空間按順時針方向組織,0和2^32-1在零點中方向重合,
下一步將各個服務器使用Hash進行一個哈希,具體可以選擇服務器的ip或主機名作為關鍵字進行哈希,這樣每臺機器就能確定其在哈希環上的位置,這里假設將上文中四臺服務器使用ip地址哈希后在環空間的位置如下:

接下來使用如下演算法定位資料訪問到相應服務器:將資料key使用相同的函式Hash計算出哈希值,并確定此資料在環上的位置,從此位置沿環順時針“行走”,第一臺遇到的服務器就是其應該定位到的服務器,
例如我們有Object A、Object B、Object C、Object D四個資料物件,經過哈希計算后,在環空間上的位置如下:
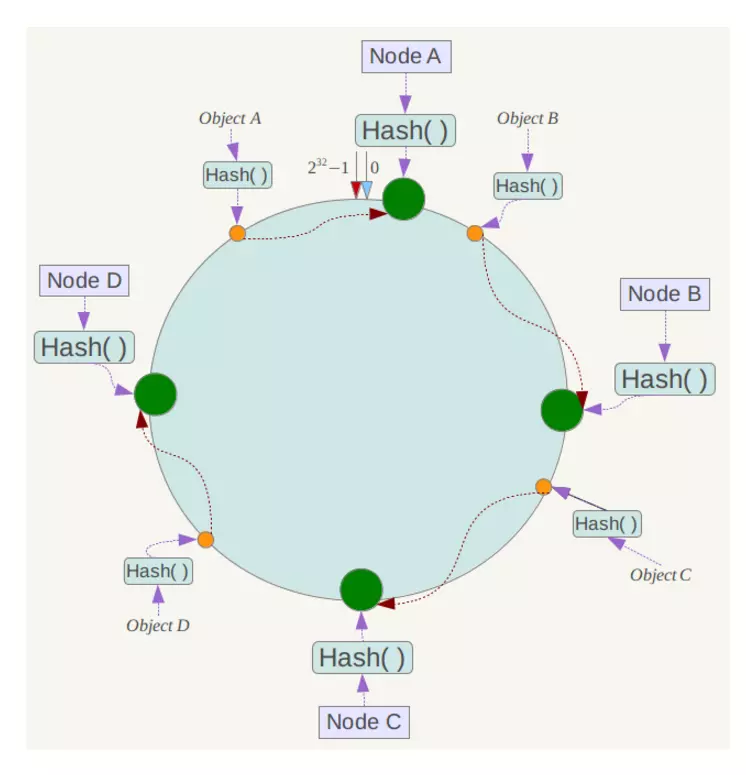
根據一致性哈希演算法,資料A會被定為到Node A上,B被定為到Node B上,C被定為到Node C上,D被定為到Node D上,
容錯性
現假設Node C不幸宕機,可以看到此時物件A、B、D不會受到影響,只有C物件被重定位到Node D,
一般的,在一致性哈希演算法中,如果一臺服務器不可用,則受影響的資料僅僅是此服務器到其環空間中前一臺服務器(即沿著逆時針方向行走遇到的第一臺服務器)之間資料,其它不會受到影響,
可擴展性
如果在系統中增加一臺服務器Node X,如下圖所示:

此時物件Object A、B、D不受影響,只有物件C需要重定位到新的Node X ,
一般的,在一致性哈希演算法中,如果增加一臺服務器,則受影響的資料僅僅是新服務器到其環空間中前一臺服務器(即沿著逆時針方向行走遇到的第一臺服務器)之間資料,其它資料也不會受到影響,
綜上所述,一致性哈希演算法對于節點的增減都只需重定位環空間中的一小部分資料,具有較好的容錯性和可擴展性,
資料傾斜問題
另外,一致性哈希演算法在服務節點太少時,容易因為節點分部不均勻而造成資料傾斜問題,例如系統中只有兩臺服務器,其環分布如下:

此時必然造成大量資料集中到Node A上,而只有極少量會定位到Node B上,
為了解決這種資料傾斜問題,一致性哈希演算法引入了虛擬節點機制,即對每一個服務節點計算多個哈希,每個計算結果位置都放置一個此服務節點,稱為虛擬節點,
具體做法可以在服務器ip或主機名的后面增加編號來實作,例如上面的情況,可以為每臺服務器計算三個虛擬節點,于是可以分別計算 “Node A#1”、“Node A#2”、“Node A#3”、“Node B#1”、“Node B#2”、“Node B#3”的哈希值,于是形成六個虛擬節點:

同時資料定位演算法不變,只是多了一步虛擬節點到實際節點的映射,例如定位到“Node A#1”、“Node A#2”、“Node A#3”三個虛擬節點的資料均定位到Node A上,這樣就解決了服務節點少時資料傾斜的問題,
在實際應用中,通常將虛擬節點數設定為32甚至更大,因此即使很少的服務節點也能做到相對均勻的資料分布,
代碼測驗
一致性Hash模擬類:
package com.example.demo.hash;
import java.util.*;
/**
* 一致性Hash
*
* @author gaochen
* @date 2019/5/29
*/
public class ConsistentHash<T> {
/**
* 節點的復制因子,實際節點個數 * numberOfReplicas
*/
private final int numberOfReplicas;
/**
* 虛擬節點個數,存盤虛擬節點的hash值到真實節點的映射
*/
private final SortedMap<Integer, T> circle = new TreeMap<>();
public ConsistentHash(int numberOfReplicas, Collection<T> nodes) {
this.numberOfReplicas = numberOfReplicas;
for (T node : nodes) {
add(node);
}
}
/**
* 模擬添加一個節點
* <p>
* 對于一個實際機器節點 node, 對應 numberOfReplicas 個虛擬節點
* 不同的虛擬節點(i不同)有不同的hash值,但都對應同一個實際機器node
* 虛擬node一般是均衡分布在環上的,資料存盤在順時針方向的虛擬node上
* </P>
*
* @param node 哈希環節點
*/
public void add(T node) {
for (int i = 0; i < numberOfReplicas; i++) {
String nodestr = node.toString() + i;
int hashcode = nodestr.hashCode();
System.out.println("hashcode:" + hashcode);
circle.put(hashcode, node);
}
}
/**
* 洗掉一個節點
*
* @param node 待洗掉節點
*/
public void remove(T node) {
for (int i = 0; i < numberOfReplicas; i++) {
circle.remove((node.toString() + i).hashCode());
}
}
/**
* 獲得一個最近的順時針節點,根據給定的key 取Hash
* 然后再取得順時針方向上最近的一個虛擬節點對應的實際節點
* 再從實際節點中取得 資料
*
* @param key 模擬快取Key
*/
public T get(Object key) {
if (circle.isEmpty()) {
return null;
}
// node 用String來表示,獲得node在哈希環中的hashCode
int hash = key.hashCode();
System.out.println("hashcode----->:" + hash);
//資料映射在兩臺虛擬機器所在環之間,就需要按順時針方向尋找機器
if (!circle.containsKey(hash)) {
SortedMap<Integer, T> tailMap = circle.tailMap(hash);
hash = tailMap.isEmpty() ? circle.firstKey() : tailMap.firstKey();
}
return circle.get(hash);
}
/**
* 獲取當前哈希環節點數
*
* @return 哈希環節點數
*/
public long getSize() {
return circle.size();
}
/**
* 查看表示整個哈希環中各個虛擬節點位置
*/
public void showBalance() {
//獲得TreeMap中所有的Key
Set<Integer> sets = circle.keySet();
//將獲得的Key集合排序
SortedSet<Integer> sortedSets = new TreeSet<Integer>(sets);
for (Integer hashCode : sortedSets) {
System.out.println(hashCode);
}
System.out.println("----each location 's distance are follows: ----");
//查看相鄰兩個hashCode的差值
Iterator<Integer> it = sortedSets.iterator();
Iterator<Integer> it2 = sortedSets.iterator();
if (it2.hasNext()) {
it2.next();
}
long keyPre, keyAfter;
while (it.hasNext() && it2.hasNext()) {
keyPre = it.next();
keyAfter = it2.next();
System.out.println(keyAfter - keyPre);
}
}
}
測驗代碼:
package com.example.demo.hash;
import org.junit.Before;
import org.junit.Test;
import java.util.Arrays;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
/**
* TODO
*
* @author gaochen
* @date 2019/5/29
*/
public class ConsistentHashTest {
private static ConsistentHash<String> consistentHash;
@Before
public void initHash() {
Set<String> nodes = new HashSet<>();
consistentHash = new ConsistentHash<>(2, nodes);
}
@Test
public void testBalance() {
// 分配三個節點
consistentHash.add("A1");
consistentHash.add("C1");
consistentHash.add("D1");
System.out.println("hash circle size: " + consistentHash.getSize());
System.out.println("location of each node are follows: ");
// consistentHash.showBalance();
// hash值在當前哈希環內
final String key1 = "A31";
// hash值超出了當前哈希環
final String key2 = "Apple";
final List<String> keys = Arrays.asList(key1, key2);
// 模擬節點分配
showAllocate(keys);
// 模擬增加節點, A31被分配到更近的B1節點
consistentHash.add("B1");
System.out.println("增加節點B1");
showAllocate(keys);
System.out.println("-------------------------------------");
// 模擬洗掉節點, A31被分配到更近的C1節點
consistentHash.remove("B1");
System.out.println("洗掉節點B1");
showAllocate(keys);
}
/**
* 模擬快取分配
*
* @param keys 快取鍵
*/
private void showAllocate(List<String> keys) {
keys.forEach(key -> {
String node = consistentHash.get(key);
// A31被分配到更近的C1節點
System.out.println(String.format("key %s is allocated to node %s", key, node));
});
}
}
控制臺輸出:
hashcode:64032
hashcode:64033
hashcode:65954
hashcode:65955
hashcode:66915
hashcode:66916
hash circle size: 6
location of each node are follows:
hashcode----->:64095
key A31 is allocated to node C1
hashcode----->:63476538
key Apple is allocated to node A1
hashcode:64993
hashcode:64994
增加節點B1
hashcode----->:64095
key A31 is allocated to node B1
hashcode----->:63476538
key Apple is allocated to node A1
-------------------------------------
洗掉節點B1
hashcode----->:64095
key A31 is allocated to node C1
hashcode----->:63476538
key Apple is allocated to node A1
可以看出,增加或洗掉節點,只會影響到節點與上一個節點之間的元素,所以一致性Hash演算法在容錯性和可擴展性上面較普通Hash是有巨大提升的,
參考資料
五分鐘看懂一致性哈希演算法
維基百科-散列函式
一致性哈希演算法及其在分布式系統中的應用
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/88177.html
標籤:其他
上一篇:Ubuntu禁用root賬號,開啟Ubuntu密鑰登錄
下一篇:運維筆記(部署篇)