求技術大神、Hadoop大牛:
使用Cloudera 5.2 安裝了 Hadoop 平臺,共15個節點,在同個私網,千兆帶寬,目前資料量約為80T左右,但最近使用 hdfs fsck / 檢測資料塊的完整情況時,發現副本的平均數量不夠3份,只有2.3而已。每天使用 hdfs fsck / 指令查看,平均的副本數量會略有增加,但進展非常慢,到現在有一個月了,還是停留在2.3的階段,每天的進展非常慢。但整個集群的檢查又是“健康”的,目前主要是副本數不夠,不知怎么破,如下圖
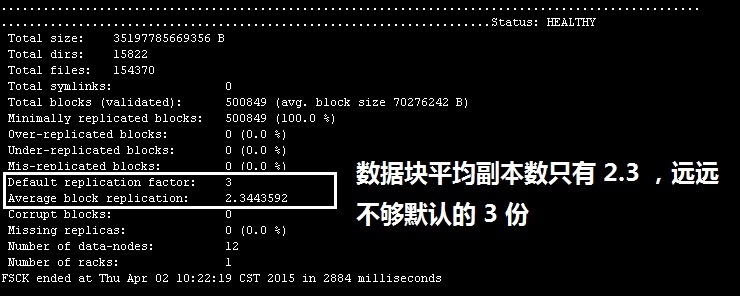
而調整了CDH的NameNode, Yarn, DataNode的資源配置,增大了記憶體、帶寬等相關的引數,似乎沒有起到什么作用。查看了CDH的首頁,IO并沒有明顯地提升,不像是在快速地拷貝復制資料塊。如果是資料量大的原因,那 IO 應該很高才是,很疑惑
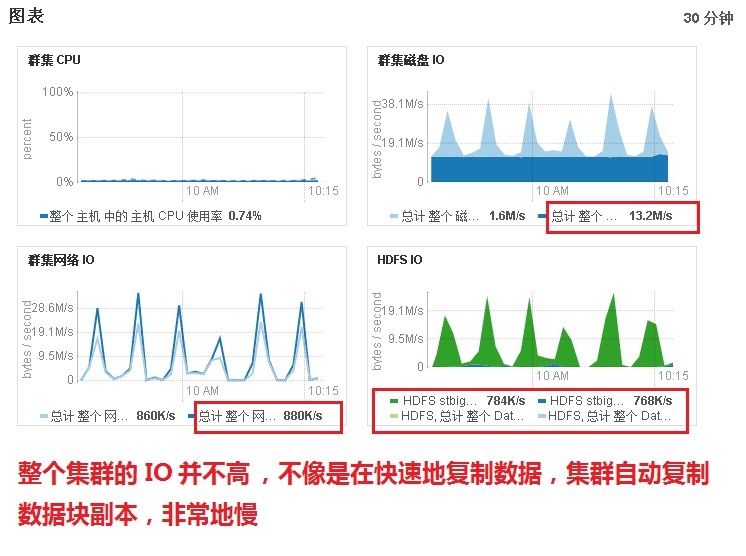
這個問題困擾了我們很久,一直找不出是什么原因和解決辦法,不知各位有沒有碰到過類似的情況,特來求救各路大神,還望指點迷津啊
uj5u.com熱心網友回復:
來支持了呢。轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/88604.html
標籤:虛擬化
上一篇:請教個問題,上傳照片到s3后,自動生成了2張壓縮后的照片,但是其中一張大小為0 bytes。怎么回事?
下一篇:達夢資料庫入門