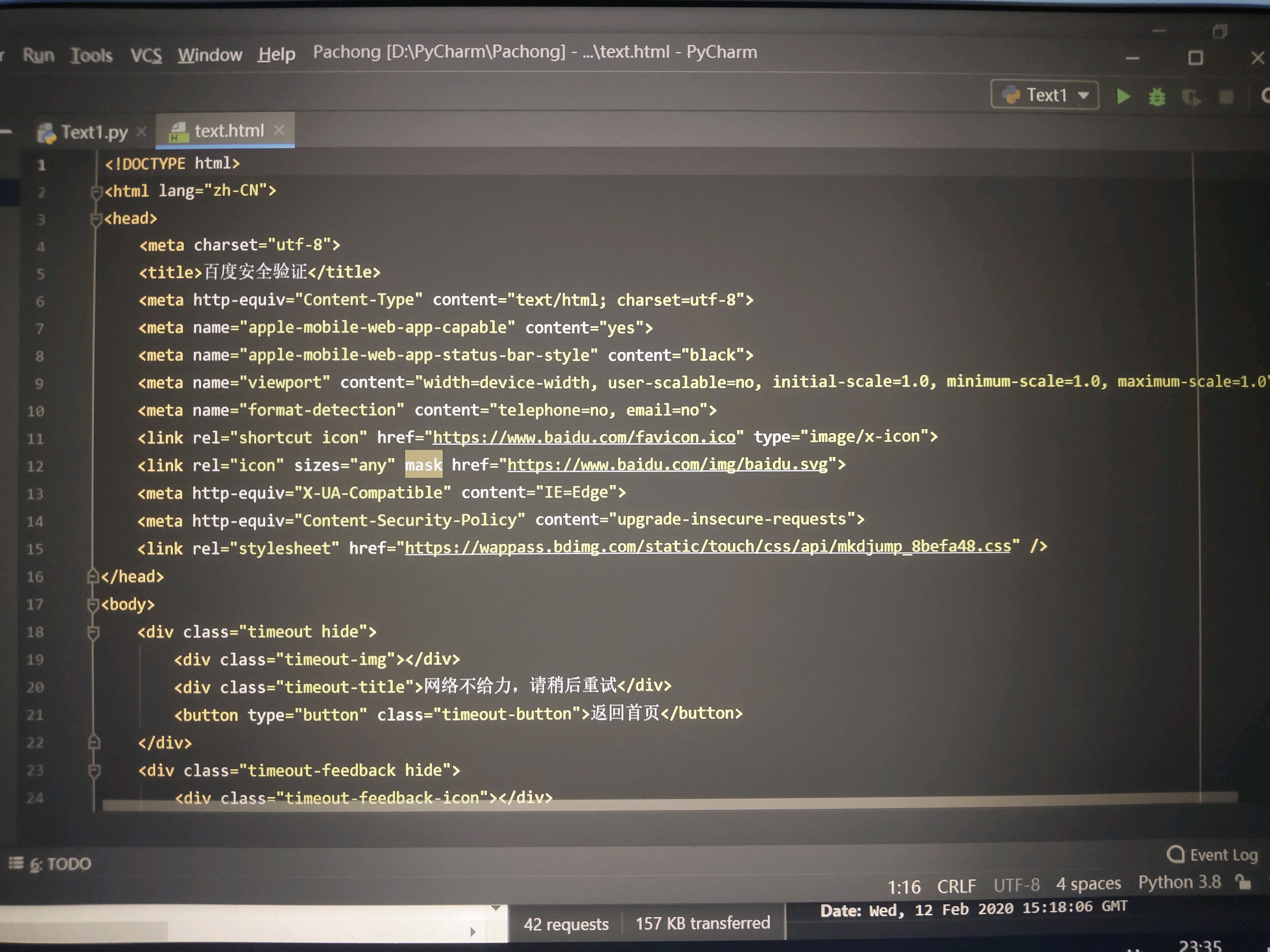
本人第一次接觸Python,聽說Python爬蟲很NB,所以在網上找了些教程,于是自己嘗試著抓取一個百度搜索的頁面,結果出現了問題:圖2為代碼,想抓取圖1的搜索頁面,運行代碼卻出現了圖3的結果,在瀏覽器打開顯示不出來。
 現向各位大佬求助
現向各位大佬求助

uj5u.com熱心網友回復:
有沒有人,救救孩子
uj5u.com熱心網友回復:
在瀏覽器打開顯示不出來??你別在IDE里打開它,在windows檔案夾下單獨打開text.html!
uj5u.com熱心網友回復:
試過了,用瀏覽器打開之后,標題那里顯示:百度驗證,內容是圖3的中文,并不是我想要抓取的圖1的頁面,而且網頁源代碼與抓取出來的結果不同
uj5u.com熱心網友回復:
1、你那個url怎么跟我的不一樣,https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=iso-8859-1&oq=python&rsv_pq=948b6158000061a3&rsv_t=a8ddjTD78Izh45wanY0qrrhO1Zr3t3f%2BvXqpqSl%2Fxe8g9B0MWtyccGYxohc&rqlang=cn&rsv_enter=0&rsv_dl=tb&inputT=6166&rsv_sug3=7&rsv_sug1=2&rsv_sug7=100&bs=python2、在requests.get里面加入timeout引數
3、實在不行就采用動態請求
4、我沒玩過爬百度,思路跟爬其他網站應該是一樣的
uj5u.com熱心網友回復:
那個url原本也是像你那樣一長串的,網上教程說刪去一些沒用的東西只保留一些關鍵的內容,結果也是一樣的。為了驗證是不是這個url的問題,我改回原來那個一長串的url,結果都是一樣的,沒什么差別,所以應該不會是這個url的問題。而且我這個問題的重點是,抓取出來的結果與網頁源代碼不同,這是怎么回事?網上的教程就是這樣做的,這里我想問一下,需不需要對瀏覽器或者pycharm做一些什么特殊的設定之類的?
uj5u.com熱心網友回復:
看樣子應該是你的url有問題,沒有抓取到真正的內容。可以在瀏覽器中打開network查看一下實際的請求地址
uj5u.com熱心網友回復:
沒理由的啊,我在這個Request url的response那里看到了網頁源代碼,但是卻沒有找到爬取出來的那個代碼

uj5u.com熱心網友回復:
https://www.baidu.com/s?ie=utf-8&mod=1&isbd=1&isid=a01231bc0025a875&ie=utf-8&f=8&rsv_bp=1&tn=baidu&wd=python&oq=python&rsv_pq=a01231bc0025a875&rsv_t=f885kk6eQgH8J2LI6Ksff42iPWBcc3eVvcQOC4S7UUfxPk4sTderPCQcEVk&rqlang=cn&rsv_enter=0&rsv_dl=tb&bs=python&rsv_sid=undefined&_ss=1&clist=&hsug=&f4s=1&csor=0&_cr1=23949用這個地址試試
uj5u.com熱心網友回復:
還是不行啊,跟原來的結果一樣
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/90863.html
下一篇:scratch如何創建云變數