文章目錄
- 1 線性代數與矩陣論
- 1.1 向量與向量空間
- 1.1.1 向量
- 1.1.2 向量空間
- 1.1.3 向量范數
- 1.1.4 常見的向量
- 1.2 矩陣
- 1.2.1 線性映射
- 1.2.2 矩陣操作
- 1.2.3 矩陣型別
- 1.2.4 特征值與特征矢量
- 1.2.5 矩陣分解
- 2 微積分
- 2.1 導數
- 2.1.1 導數法則
- 2.1.1.1 導數法則 加(減)法則
- 2.1.1.2 乘法法則
- 2.1.1.3 鏈式法則
- 2.2 機器學習常見函式的導數
- 2.2.1 向量函式及其導數
- 2.2.2 按位計算的向量函式及其導數
- 2.2.3 Logistic函式
- 2.2.4 softmax函式
- 3 數學優化
- 3.1 數學優化的型別
- 3.1.1 離散優化和連續優化
- 3.1.2 無約束優化和約束優化
- 3.1.3 線性優化和非線性優化
- 3.2 優化演算法
- 3.2.1 全域最優和區域最優
- 3.2.2 梯度下降法
- 3.2.3 拉格朗日乘數法與KKT條件
- 4 概率論與隨機程序
- 4.1 樣本空間
- 4.2 事件和概率
- 4.2.1 隨機變數
- 連續隨機變數
- 累積分布函式
- 4.2.2 隨機向量
- 離散隨機向量
- 連續隨機向量
- 4.2.3 邊際分布
- 4.2.4 條件概率分布
- 4.2.5 獨立與條件獨立
- 4.2.6 期望和方差
- 4.3 隨機程序
- 4.3.1 馬爾可夫程序
- 4.3.2 高斯程序
- 5 資訊論
- 5.1 熵
- 5.1.1 自資訊和熵
- 5.2 聯合熵和條件熵
- 5.2 互資訊
- 5.3 交叉熵和散度
- 5.3.1 交叉熵
- 5.3.2 KL散度
- 5.3.3 JS散度
- 5.3.4 Wasserstein距離
1 線性代數與矩陣論
線性代數主要包含向量、向量空間(或稱線性空間)以及向量的線性變換和有 限維的線性方程組,
1.1 向量與向量空間
1.1.1 向量
標量(Scalar)是一個實數,只有大小,沒有方向,而向量(Vector)是由 一組實陣列成的有序陣列,同時具有大小和方向,一個
n
n
n維向量
a
a
a是由
n
n
n個有序 實陣列成,表示為
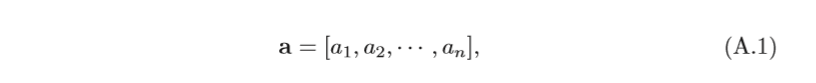
其中
a
i
a_i
ai?稱為向量
a
a
a的第
i
i
i個分量,或第i維,向量符號一般用黑體小寫字母
a
,
b
,
c
a,b,c
a,b,c, 或小寫希臘字母
α
,
β
,
γ
α,β,γ
α,β,γ 等來表示
1.1.2 向量空間
向量空間(Vector Space),也稱線性空間(Linear Space),是指由向量 組成的集合,并滿足以下兩個條件:
向量加法+ + +:向量空間 V V V中的兩個向量 a a a和 b b b,它們的和 a + b a+b a+b也屬于空 間 V V V;標量乘法·:向量空間V中的任一向量 a a a和任一標量 c c c,它們的乘積 c ? a c·a c?a也 屬于空間 V V V,
歐氏空間 一個常用的線性空間是歐氏空間(Euclidean Space),一個歐氏空間 表示通常為
R
n
R^n
Rn,其中
n
n
n為空間維度(Dimension),歐氏空間中向量的加法和 標量乘法定義為:
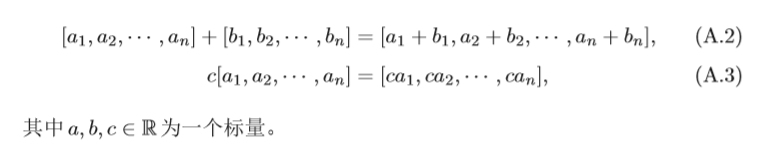
線性子空間 向量空間
V
V
V的線性子空間
U
U
U是
V
V
V的一個子集,并且滿足向量空間的條件(向量加法和標量乘法),
線性無關 線性空間V中的一組向量
v
1
,
v
2
,
?
?
?
,
v
n
{v1,v2,··· ,vn}
v1,v2,???,vn,如果對任意的一組標量
λ
1
,
λ
2
,
?
?
?
,
λ
n
λ1,λ2,··· ,λn
λ1,λ2,???,λn,滿足
λ
1
v
1
+
λ
2
v
2
+
?
?
?
+
λ
n
v
n
=
0
λ1v1 + λ2v2 +···+ λnvn = 0
λ1v1+λ2v2+???+λnvn=0,則必然
λ
1
=
λ
2
=
?
?
?
=
λ
n
=
0
λ1 = λ2 = ··· = λn =0
λ1=λ2=???=λn=0,那么
v
1
,
v
2
,
?
?
?
,
v
n
{v1,v2,··· ,vn}
v1,v2,???,vn是線性無關的,也稱為線性獨立的,
基向量 向量空間
V
V
V的基(Base)
B
=
e
1
,
e
2
,
?
?
?
,
e
n
B={e1,e2,··· ,en}
B=e1,e2,???,en是
V
V
V的有限子集,其元素之間線性無關,向量空間
V
V
V所有的向量都可以按唯一的方式表達為
B
B
B中向量的 線性組合,對任意
v
∈
V
v ∈V
v∈V,存在一組標量
(
λ
1
,
λ
2
,
?
?
?
,
λ
n
)
(λ1,λ2,··· ,λn)
(λ1,λ2,???,λn)使得
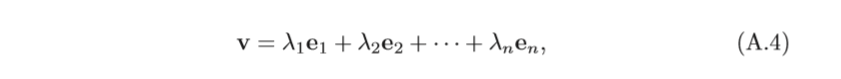
其中基B中的向量稱為基向量(Base Vector),如果基向量是有序的,則標量
(
λ
1
,
λ
2
,
?
?
?
,
λ
n
)
(λ1,λ2,··· ,λn)
(λ1,λ2,???,λn)稱為向量
v
v
v關于基
B
B
B的坐標(Coordinates),
n
n
n維空間V的一組標準基(Standard Basis)為

V
V
V中的任一向量
v
=
[
v
1
,
v
2
,
?
?
?
,
v
n
]
v=[v1,v2,··· ,vn]
v=[v1,v2,???,vn]可以唯一的表示為
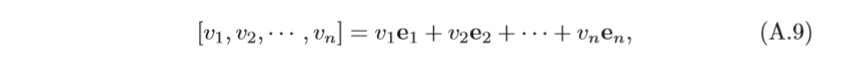
v
1
,
v
2
,
?
?
?
,
v
n
v1,v2,··· ,vn
v1,v2,???,vn也稱為向量v的笛卡爾坐標(Cartesian Coordinate),
向量空間中的每個向量可以看作是一個線性空間中的笛卡兒坐標,
內積 一個
n
n
n維線性空間中的兩個向量
a
a
a和
b
b
b,其內積為
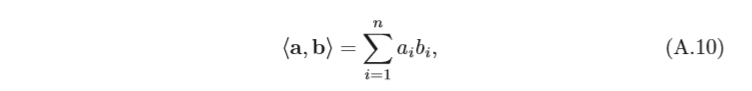
正交 如果向量空間中兩個向量的內積為
0
0
0,則它們正交(Orthogonal),如果 向量空間中一個向量
v
v
v與子空間
U
U
U中的每個向量都正交,那么向量
v
v
v和子空間
U
U
U正交,
1.1.3 向量范數
范數(Norm)是一個表示向量“長度”的函式,為向量空間內的所有向量賦予非零的正長度或大小,對于一個
n
n
n維向量
v
v
v,一個常見的范數函式為
l
p
lp
lp 范數
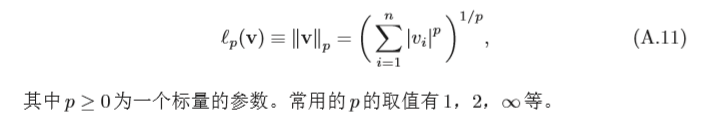
l
1
l1
l1 范數
l
1
l1
l1 范數為向量的各個元素的絕對值之和,
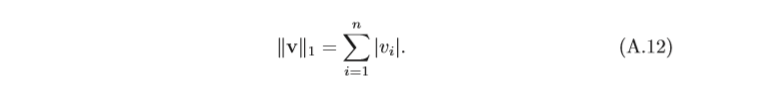
l
2
l2
l2 范數
l
2
l2
l2范數為:
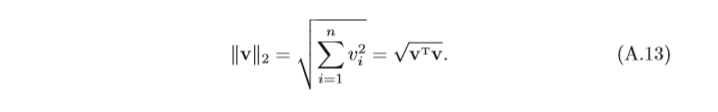
?
2
?2
?2 范數又稱為
E
u
c
l
i
d
e
a
n
Euclidean
Euclidean范數或者
F
r
o
b
e
n
i
u
s
Frobenius
Frobenius范數,從幾何角度,向量也可以表示為從原點出發的一個帶箭頭的有向線段,其
l
2
l2
l2范數為線段的長度,也常稱為向量的模,
l
∞
l∞
l∞范數
l
∞
l∞
l∞范數為向量的各個元素的最大絕對值,
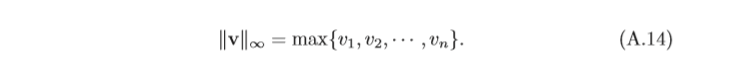
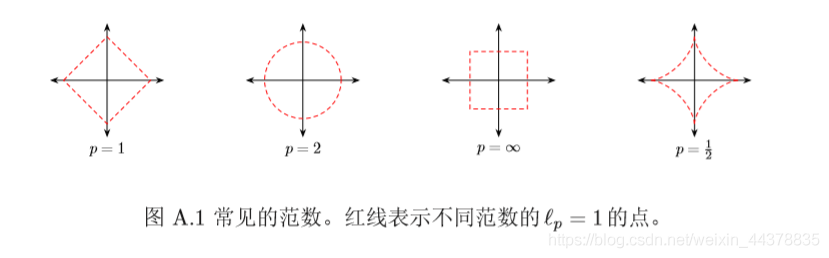
圖A.1給出了常見范數的示例,為二維向量[x,y]的范數,
1.1.4 常見的向量
全0向量指所有元素都為0的向量,用0表示,全0向量為笛卡爾坐標系中 的原點,
全1向量指所有值為1的向量,用1表示,
one-hot向量為有且只有一個元素為1,其余元素都為0的向量,one-hot向 量是在數字電路中的一種狀態編碼,指對任意給定的狀態,狀態暫存器中只有 l位為1,其余位都為0,
1.2 矩陣
1.2.1 線性映射
線性映射(Linear Mapping)是指從線性空間
V
V
V到線性空間
W
W
W的一個映射函式
f
:
V
→
W
f :V →W
f:V→W,并滿足:對于
V
V
V中任何兩個向量
u
u
u和
v
v
v以及任何標量
c
c
c,有
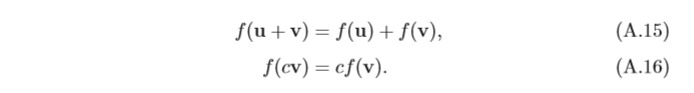
兩個有限維歐氏空間的映射函式
f
:
R
n
→
R
m
f : R^n →R^m
f:Rn→Rm 可以表示為
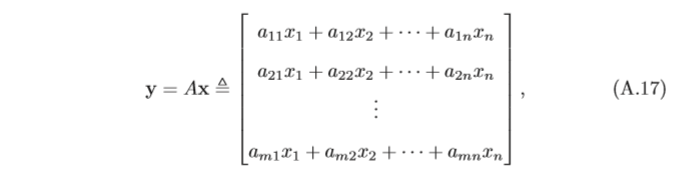
其中
A
A
A定義為
m
×
n
m×n
m×n的矩陣(Matrix),是一個由
m
m
m行
n
n
n列元素排列成的矩形陣 列,一個矩陣
A
A
A從左上角數起的第
i
i
i行第
j
j
j 列上的元素稱為第
I
,
j
I,j
I,j 項,通常記為
[
A
]
i
j
[A]ij
[A]ij 或
a
i
j
aij
aij,矩陣
A
A
A定義了一個從
R
n
R^n
Rn 到
R
m
R^m
Rm 的線性映射;向量
x
∈
R
n
x∈R^n
x∈Rn 和
y
∈
R
m
y∈R^m
y∈Rm 分別為兩個空間中的列向量,即大小為
n
×
1
n×1
n×1的矩陣,

1.2.2 矩陣操作
加 如果
A
A
A和
B
B
B都為
m
×
n
m×n
m×n的矩陣,則
A
A
A和
B
B
B的加也是
m
×
n
m×n
m×n的矩陣,其每個元素是
A
A
A和
B
B
B相應元素相加,
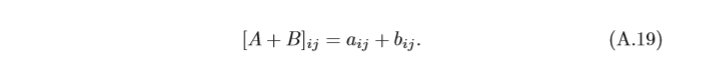
乘積 假設有兩個
A
A
A和
B
B
B 分別表示兩個線性映射
g
:
R
m
→
R
k
g : R^m → R^k
g:Rm→Rk 和
f
:
R
n
→
R
m
f : R^n → R^m
f:Rn→Rm, 則其復合線性映射
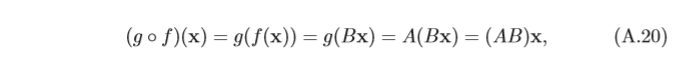
其中
A
B
AB
AB表示矩陣
A
A
A和
B
B
B的乘積,定義為
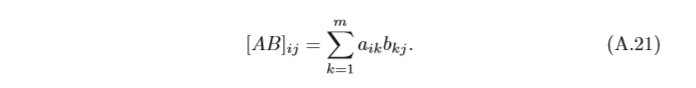
兩個矩陣的乘積僅當第一個矩陣的列數和第二個矩陣的行數相等時才能定義, 如
A
A
A是
k
×
m
k×m
k×m矩陣和
B
B
B是
m
×
n
m×n
m×n矩陣,則乘積
A
B
AB
AB是一個
k
×
n
k×n
k×n的矩陣,
矩陣的乘法滿足結合律和分配律:
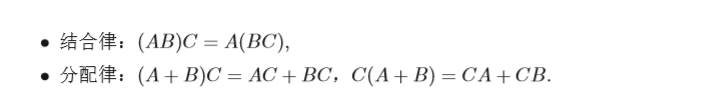
Hadamard積 A和B 的Hadamard積,也稱為逐點乘積,為A和B 中對應的 元素相乘,
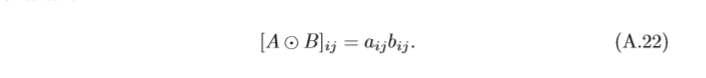
一個標量
c
c
c與矩陣
A
A
A乘積為
A
A
A的每個元素是
A
A
A的相應元素與
c
c
c的乘積
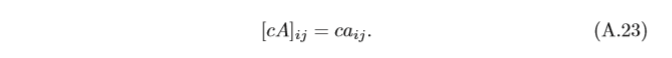
轉置
m
×
n
m×n
m×n矩陣
A
A
A的轉置(Transposition)是一個
n
×
m
n×m
n×m的矩陣,記為
A
T
,
A
T
A^T,A^T
AT,AT 的第
i
i
i行第
j
j
j列的元素是原矩陣
A
A
A的第
j
j
j行第
i
i
i列的元素,
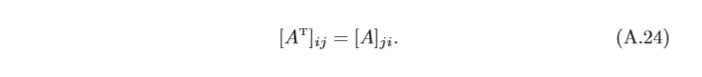
向量化 矩陣的向量化是將矩陣表示為一個列向量,這里,
v
e
c
vec
vec是向量化算子, 設
A
=
[
a
i
j
]
m
×
n
A =[a_{ij}]_{m×n}
A=[aij?]m×n?,則
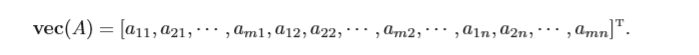
跡 方塊矩陣
A
A
A的對角線元素之和稱為它的跡(Trace),記為
t
r
(
A
)
tr(A)
tr(A),盡管矩陣 的乘法不滿足交換律,但它們的跡相同,即
t
r
(
A
B
)
=
t
r
(
B
A
)
tr(AB)= tr(BA)
tr(AB)=tr(BA),
行列式 方塊矩陣A的行列式是一個將其映射到標量的函式,記作
d
e
t
(
A
)
det(A)
det(A)或
∣
A
∣
|A|
∣A∣, 行列式可以看做是有向面積(二階行列式)或體積(三階行列式)的概念在歐氏空間中的推廣,在
n
n
n維歐氏空間中,行列式描述的是一個線性變換對“體積”所造成的影響,
一個
n
×
n
n×n
n×n的方塊矩陣
A
A
A的行列式定義為:
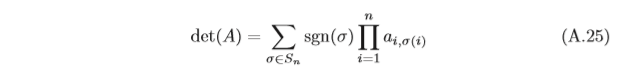
其中
S
n
S_n
Sn? 是
1
,
2
,
.
.
.
,
n
{1,2,...,n}
1,2,...,n的所有排列的集合,
σ
(
i
)
σ(i)
σ(i) 是其中一個排列,
σ
(
i
)
σ(i)
σ(i)是元素i在 排列σ中的位置,sgn(σ)表示排列σ的符號差,定義為

如:
σ
(
2431
)
=
1
+
2
+
1
(
2
比
1
大
,
4
比
3
和
1
大
,
3
比
1
大
)
\sigma(2431)=1+2+1(2比1大,4比3和1大,3比1大)
σ(2431)=1+2+1(2比1大,4比3和1大,3比1大)
其中逆序對的定義為:在排列σ中,如果有序數對
(
i
,
j
)
(i,j)
(i,j)滿足
1
≤
i
<
j
≤
n
1 ≤ i < j ≤ n
1≤i<j≤n但
σ
(
i
)
>
σ
(
j
)
σ(i) > σ(j)
σ(i)>σ(j),則其為
σ
σ
σ的一個逆序對,
秩 一個矩陣
A
A
A的列秩是
A
A
A的線性無關的列向量數量,行秩是
A
A
A的線性無關的 行向量數量,一個矩陣的列秩和行秩總是相等的,簡稱為秩(Rank),
一個
m
×
n
m×n
m×n的矩陣的秩最大為
m
i
n
(
m
,
n
)
min(m,n)
min(m,n),兩個矩陣的乘積
A
B
AB
AB的秩
r
a
n
k
(
A
B
)
≤
m
i
n
(
r
a
n
k
(
A
)
,
r
a
n
k
(
B
)
)
rank(AB)≤ min(rank(A),rank(B))
rank(AB)≤min(rank(A),rank(B)),
矩陣范數 矩陣的范數有很多種形式,


1.2.3 矩陣型別
對稱矩陣 對稱矩陣(Symmetric Matrix)指其轉置等于自己的矩陣,即滿足
A
=
A
T
A = A^T
A=AT,
對角矩陣 對角矩陣(Diagonal Matrix)是一個主對角線之外的元素皆為0的矩 陣,對角線上的元素可以為0或其他值,一個
n
×
n
n×n
n×n的對角矩陣
A
A
A滿足:
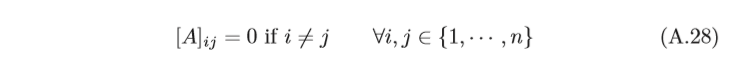
對角矩陣A也可以記為
d
i
a
g
(
a
)
diag(a)
diag(a),
a
a
a為一個
n
n
n維向量,并滿足
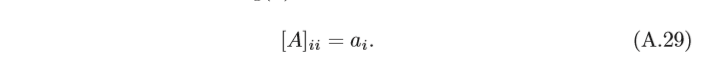
n
×
n
n×n
n×n的對角矩陣
A
=
d
i
a
g
(
a
)
A =diag(a)
A=diag(a)和
n
n
n維向量
b
b
b的乘積為一個
n
n
n維向量
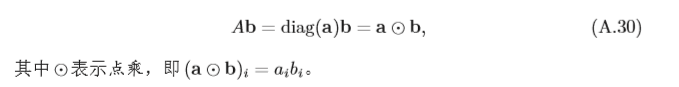
單位矩陣 單位矩陣(Identity Matrix)是一種特殊的的對角矩陣,其主對角線 元素為1,其余元素為0,
n
n
n階單位矩陣
I
n
I_n
In?,是一個
n
×
n
n×n
n×n的方塊矩陣,可以記 為
I
n
=
d
i
a
g
(
1
,
1
,
.
.
.
,
1
)
I_n=diag(1,1,...,1)
In?=diag(1,1,...,1),
一個
m
×
n
m×n
m×n的矩陣A和單位矩陣的乘積等于其本身,
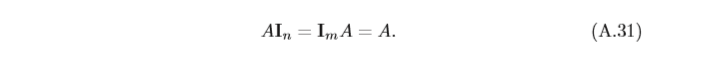
逆矩陣 對于一個
n
×
n
n×n
n×n的方塊矩陣
A
A
A,如果存在另一個方塊矩陣
B
B
B使得
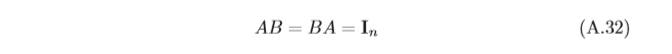
為單位陣,則稱
A
A
A是可逆的,矩陣
B
B
B稱為矩陣
A
A
A的逆矩陣(Inverse Matrix), 記為
A
?
1
A^{?1}
A?1,
一個方陣的行列式等于0當且僅當該方陣不可逆,
正定矩陣 對于一個
n
×
n
n × n
n×n 的對稱矩陣
A
A
A,如果對于所有的非零向量
x
∈
R
n
x ∈ R^n
x∈Rn 都滿足
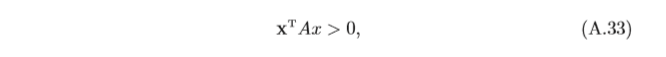
則
A
A
A為正定矩陣(Positive-De?nite Matrix),如果
x
T
A
x
≥
0
x^TAx ≥0
xTAx≥0,則
A
A
A是半正定矩陣(Positive-Semide?nite Matrix),
正交矩陣 正交矩陣(Orthogonal Matrix )A為一個方塊矩陣,其逆矩陣等于 其轉置矩陣,
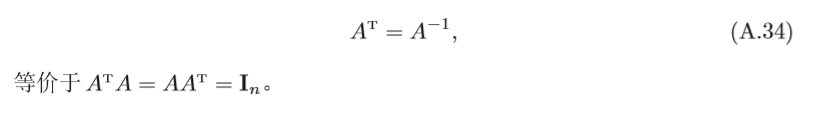
Gram矩陣 向量空間中一組向量
v
1
,
v
2
?
?
?
,
v
n
v1,v2··· ,vn
v1,v2???,vn 的
G
r
a
m
Gram
Gram矩陣(Gram Matrix)
G
G
G是內積的對稱矩陣,其元素
G
i
j
Gij
Gij 為
v
i
T
v
j
v^T_iv_j
viT?vj?
1.2.4 特征值與特征矢量
如果一個標量
λ
λ
λ和一個非零向量
v
v
v滿足
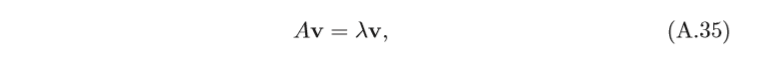
則
λ
λ
λ和
v
v
v分別稱為矩陣
A
A
A的特征值(Eigenvalue)和特征向量(Eigenvector),
1.2.5 矩陣分解
一個矩陣通常可以用一些比較“簡單”的矩陣來表示,稱為矩陣分解(Matrix Decomposition, Matrix Factorization),
奇異值分解 一個
m
×
n
m×n
m×n的矩陣
A
A
A的奇異值分解(Singular Value Decomposition, SVD)定義為
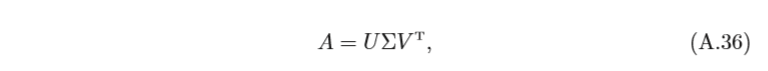
其中
U
U
U 和
V
V
V分別為
m
×
m
m×m
m×m和
n
×
n
n×n
n×n的正交矩陣,
Σ
Σ
Σ為
m
×
n
m×n
m×n的對角矩陣,其對 角線上的元素稱為奇異值(Singular Value),
特征分解 一個
n
×
n
n×n
n×n的方塊矩陣
A
A
A的特征分解(Eigendecomposition)定義為
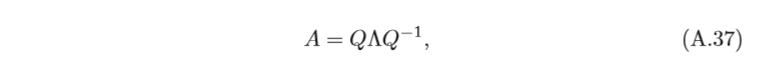
其中
Q
Q
Q為
n
×
n
n×n
n×n的方塊矩陣,其每一列都為
A
A
A的特征向量,為對角陣,其每一 個對角元素為
A
A
A的特征值,
如果A為對稱矩陣,則A可以被分解為
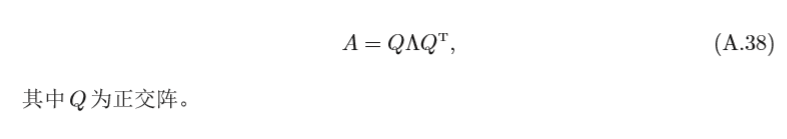

2 微積分
2.1 導數
導數(Derivative)是微積分學中重要的基礎概念,
對于定義域和值域都是實數域的函式
f
:
R
→
R
f : R→R
f:R→R,若
f
(
x
)
f(x)
f(x)在點
x
0
x_0
x0? 的某個鄰 域
?
x
?x
?x內,極限

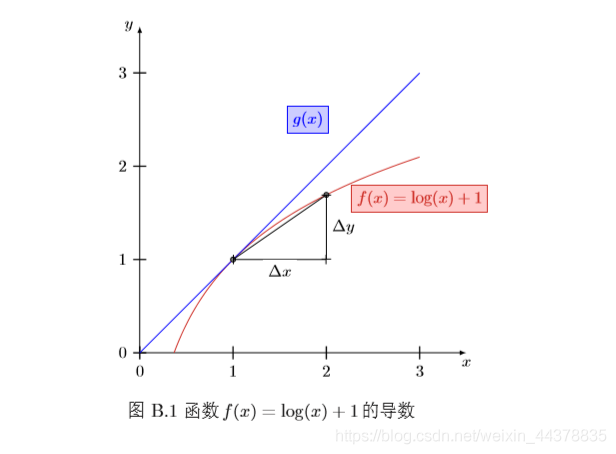
在幾何上,導數可以看做函式曲線上的切線斜率,圖B.1給出了一個函式導數的可視化示例,其中函式
g
(
x
)
g(x)
g(x)的斜率為函式
f
(
x
)
f(x)
f(x)在點
x
x
x的導數,
?
y
=
f
(
x
+
?
x
)
?
f
(
x
)
?y = f(x+ ?x)?f(x)
?y=f(x+?x)?f(x),
給定一個連續函式,計算其導數的程序稱為微分(Di?erentiation),微分的逆程序為積分(Integration),函式
f
(
x
)
f(x)
f(x)的積分可以寫為
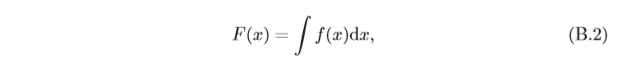
其中
F
(
x
)
F(x)
F(x)稱為
f
(
x
)
f(x)
f(x)的原函式,
若函式
f
(
x
)
f(x)
f(x)在其定義域包含的某區間內每一個點都可導,那么也可以說函 數f(x)在這個區間內可導,如果一個函式
f
(
x
)
f(x)
f(x)在定義域中的所有點都存在導 數,則
f
(
x
)
f(x)
f(x)為可微函式(Di?erentiable Function),可微函式一定連續,但連 續函式不一定可微,例如函式
∣
x
∣
|x|
∣x∣為連續函式,但在點
x
=
0
x =0
x=0處不可導,
表B.1給出了幾個常見函式的導數

高階導數 對一個函式的導數繼續求導,可以得到高階導數,函式
f
(
x
)
f(x)
f(x)的導數
f
′
(
x
)
f′(x)
f′(x)稱為一階導數,
f
′
(
x
)
f′(x)
f′(x)的導數稱為二階導數,記為
f
′
′
(
x
)
f′′(x)
f′′(x)或
d
2
f
(
x
)
d
x
2
\frac{d^2f(x)}{dx^2}
dx2d2f(x)?
偏導數 對于一個多變數函式
f
:
R
d
→
R
f : R^d →R
f:Rd→R,它的偏導數(Partial Derivative )是 關于其中一個變數
x
i
x_i
xi? 的導數,而保持其他變數固定,可以記為
f
′
x
i
(
x
)
f′ _{x_i}(x)
f′xi??(x),
?
x
i
f
(
x
)
?_{x_i}f(x)
?xi??f(x),
?
f
(
x
)
?
x
i
\frac{?f (x)}{?x_i}
?xi??f(x)? 或
?
?
x
i
f
(
x
)
\frac{?}{?x_i} f(x)
?xi???f(x),
對于一個
d
d
d維向量
x
∈
R
d
x∈R^d
x∈Rd,函式
f
(
x
)
=
f
(
x
1
,
?
?
?
,
x
d
)
∈
R
f(x)= f(x1,··· ,xd)∈R
f(x)=f(x1,???,xd)∈R,則
f
(
x
)
f(x)
f(x)關于
x
x
x 的偏導數為
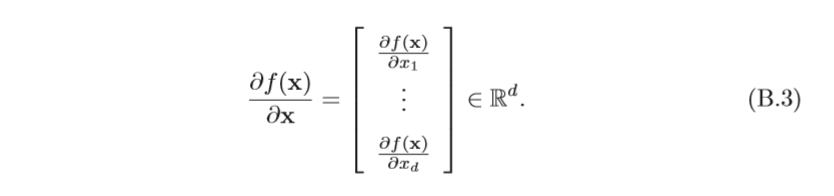
若函式
f
(
x
)
∈
R
k
f(x)∈R^k
f(x)∈Rk 的值也為一個向量,則
f
(
x
)
f(x)
f(x)關于
x
x
x的偏導數為
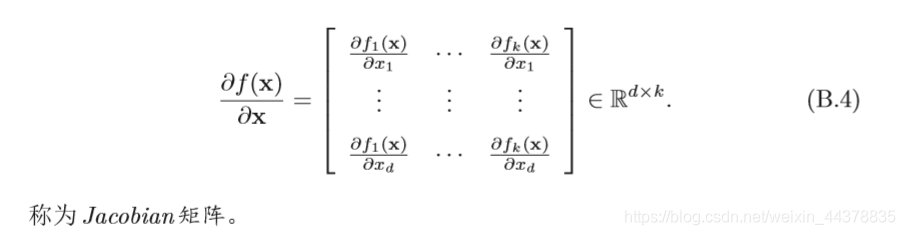
2.1.1 導數法則
一個復雜函式的導數的計算可以通過以下法則來簡化,
2.1.1.1 導數法則 加(減)法則
y
=
f
(
x
)
,
z
=
g
(
x
)
y=f(x),z=g(x)
y=f(x),z=g(x),則
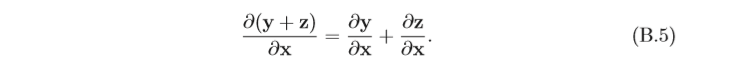
2.1.1.2 乘法法則
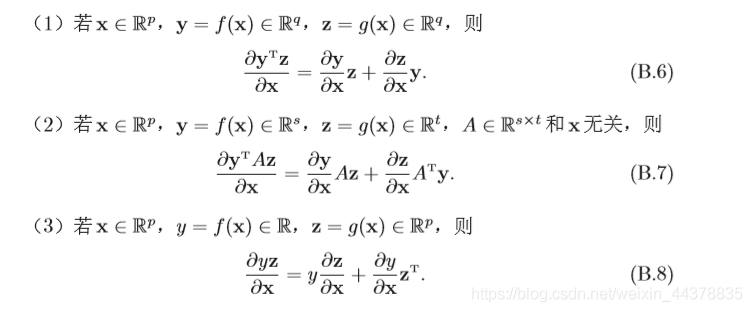
2.1.1.3 鏈式法則
鏈式法則(Chain Rule),是求復合函式導數的一個法則,是在微積分中計算導數的一種常用方法,
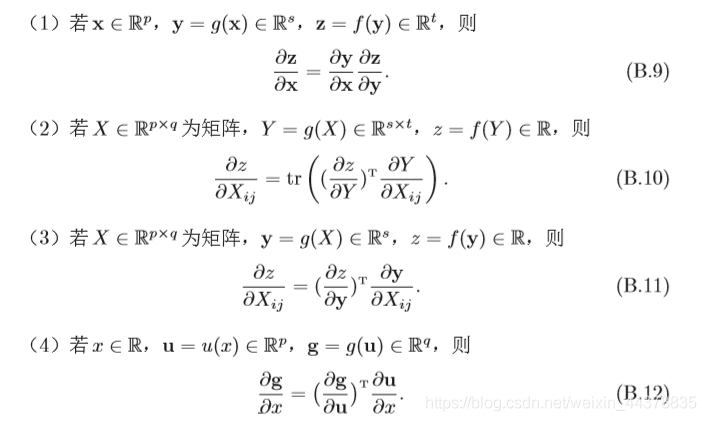
2.2 機器學習常見函式的導數
2.2.1 向量函式及其導數
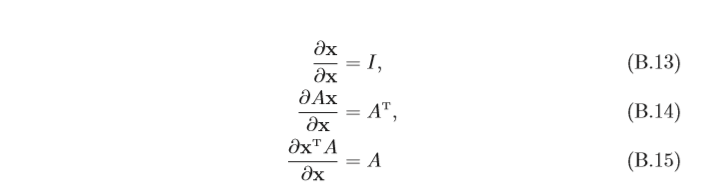
2.2.2 按位計算的向量函式及其導數
假設一個函式f(x)的輸入是標量
x
x
x,對于一組
K
K
K 個標量
x
1
,
?
?
?
,
x
K
x_1,··· ,x_K
x1?,???,xK?,我們 可以通過
f
(
x
)
f(x)
f(x)得到另外一組
K
K
K個標量
z
1
,
?
?
?
,
z
K
z_1,··· ,z_K
z1?,???,zK?,
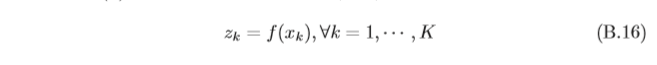
為了簡便起見,我們定義
x
=
[
x
1
,
?
?
?
,
x
K
]
T
,
z
=
[
z
1
,
?
?
?
,
z
K
]
T
x=[x_1,··· ,x_K]^T,z=[z_1,··· ,z_K]^T
x=[x1?,???,xK?]T,z=[z1?,???,zK?]T,
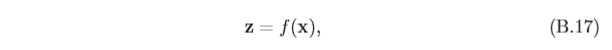
當
x
x
x為標量時,
f
(
x
)
f(x)
f(x)的導數記為
f
′
(
x
)
f′(x)
f′(x),當輸入為
K
K
K維向量
x
=
[
x
1
,
?
?
?
,
x
K
]
T
x=[x_1,··· ,x_K]^T
x=[x1?,???,xK?]T 時,其導數為一個對角矩陣,

2.2.3 Logistic函式
Logistic函式是一種常用的S形函式,是比利時數學家 Pierre Fran?ois Verhulst在1844-1845年研究種群數量的增長模型時提出命名的,最初作為一種生態學模型,
Logistic函式定義為:
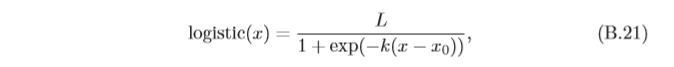
這里
e
x
p
(
?
)
exp(·)
exp(?)函式表示自然對數,
x
0
x_0
x0? 是中心點,
L
L
L是最大值,
k
k
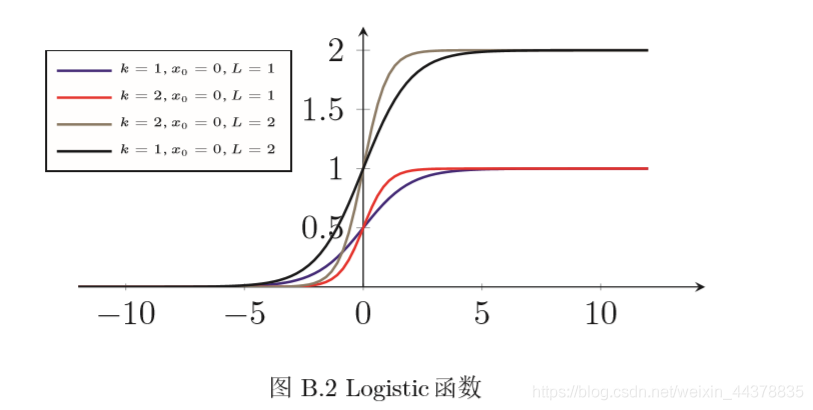
k是曲線的傾斜度, 圖B.2給出了幾種不同引數的logistic函式曲線,當
x
x
x趨向于
?
∞
?∞
?∞時,
l
o
g
i
s
t
i
c
(
x
)
logistic(x)
logistic(x) 接近于0;當
x
x
x趨向于
+
∞
+∞
+∞時,
l
o
g
i
s
t
i
c
(
x
)
logistic(x)
logistic(x)接近于
L
L
L,
當引數為
(
k
=
1
,
x
0
=
0
,
L
=
1
)
(k =1,x0 =0,L =1)
(k=1,x0=0,L=1)時,logistic函式稱為標準logistic函式,記 為
σ
(
x
)
σ(x)
σ(x),
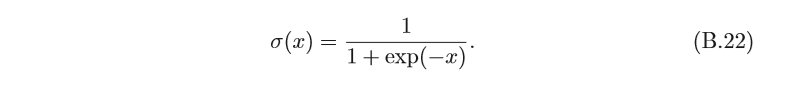
標準logistic函式在機器學習中使用得非常廣泛,經常用來將一個實數空間 的數映射到
(
0
,
1
)
(0,1)
(0,1)區間,
標準logistic函式的導數為
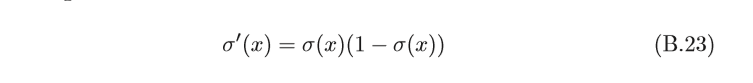
當輸入為
K
K
K 維向量
x
=
[
x
1
,
?
?
?
,
x
K
]
T
x=[x_1,··· ,x_K]^T
x=[x1?,???,xK?]T 時,其導數為
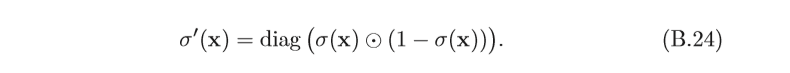
2.2.4 softmax函式
softmax函式是將多個標量映射為一個概率分布,
對于
K
K
K個標量
x
1
,
?
?
?
,
x
K
x_1,··· ,x_K
x1?,???,xK?,softmax函式定義為
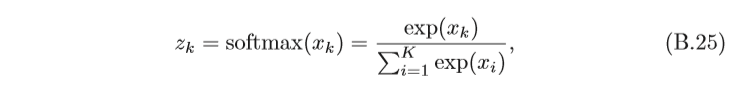
這樣,我們可以將
K
K
K 個變數
x
1
,
?
?
?
,
x
K
x_1,··· ,x_K
x1?,???,xK?轉換為一個分布:
z
1
,
?
?
?
,
z
K
z_1,··· ,z_K
z1?,???,zK?,滿足
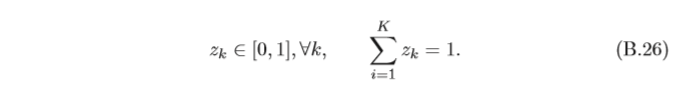
當softmax函式的輸入為
K
K
K 維向量
x
x
x時,

其導數為
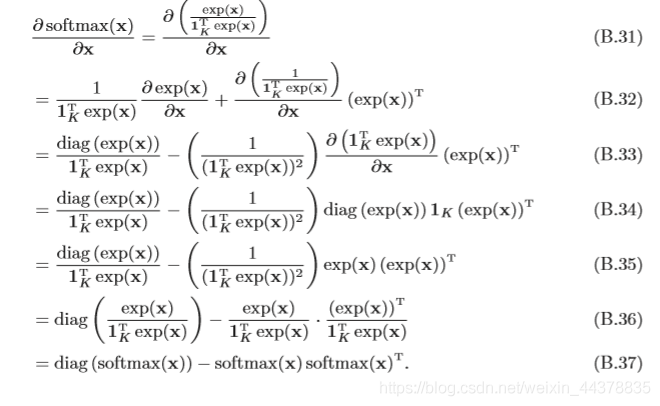
其中
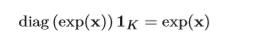
3 數學優化
數學優化(Mathematical Optimization)問題,也叫最優化問題,是指在一定 約束條件下,求解一個目標函式的最大值(或最小值)問題,
數學優化問題的定義為:給定一個目標函式(也叫代價函式)
f
:
A
→
R
f : A→ R
f:A→R, 尋找一個變數(也叫引數)
x
?
∈
D
x^? ∈D
x?∈D,使得對于所有
D
D
D中的
x
x
x,
f
(
x
?
)
≤
f
(
x
)
f(x^?)≤ f(x)
f(x?)≤f(x)(最 小化);或者
f
(
x
?
)
≥
f
(
x
)
f(x^?)≥ f(x)
f(x?)≥f(x)(最大化),其中
D
D
D為變數
x
x
x的約束集,也叫可行域;
D
D
D中的變數被稱為是可行解,
3.1 數學優化的型別
3.1.1 離散優化和連續優化
根據輸入變數x的值域是否為實數域,數學優化問題可以分為離散優化問 題和連續優化問題,
離散優化問題
離散優化(Discrete Optimization)問題是目標函式的輸入變數為離散變數,比如為整數或有限集合中的元素,離散優化問題主要有兩個分支:
- 組合優化(Combinatorial Optimization):其目標是從一個有限集合中找出使得目標函式最優的元素,在一般的組合優化問題中,集合中的元素之間存在一定的關聯,可以表示為圖結構,典型的組合優化問題有旅行商問題、最小生成樹問題、圖著色問題等,很多機器學習問題都是組 合優化問題,比如特征選擇、聚類問題、超引數優化問題以及結構化學習 (Structured Learning)中標簽預測問題等,
- 整數規劃(Integer Programming):輸入變數
x
∈
Z
d
x∈Z^d
x∈Zd為整數,一般常見的整數規劃問題為整數線性規劃(Integer Linear Programming,ILP), 整數線性規劃的一種最直接的求解方法是:
(1)去掉輸入必須為整數的限制,將原問題轉換為一般的線性規劃問題,這個線性規劃問題為原問題的 松弛問題;
(2)求得相應松弛問題的解;
(3)把松弛問題的解四舍五入到 最接近的整數,但是這種方法得到的解一般都不是最優的,因此原問題的 最優解不一定在松弛問題最優解的附近,另外,這種方法得到的解也不一 定滿足約束條件,
離散優化問題的求解一般都比較困難,優化演算法的復雜度都比較高,
連續優化問題
連續優化(Continuous Optimization)問題是目標函式的輸入變數為連續 變數
x
∈
R
d
x∈R^d
x∈Rd,即目標函式為實函式,本節后面的內容主要以連續優化為主,
3.1.2 無約束優化和約束優化
在連續優化問題中,根據是否有變數的約束條件,可以將優化問題分為無 約束優化問題和約束優化問題,
無約束優化問題(Unconstrained Optimization)的可行域為整個實數域
D
=
R
d
D= R^d
D=Rd,可以寫

約束優化問題(Constrained Optimization)中變數
x
x
x需要滿足一些等式或不等式的約束,約束優化問題通常使用拉格朗日乘數法來進行求解,
最優化問題一般可以表示 為求最小值問題,求
f
(
x
)
f(x)
f(x)最 大值等價于求
?
f
(
x
)
?f(x)
?f(x)的最小 值,
3.1.3 線性優化和非線性優化
如果在公式(C.1)中,目標函式和所有的約束函式都為線性函式,則該問題為線性規劃問題(Linear Programming),相反,如果目標函式或任何一個約 束函式為非線性函式,則該問題為非線性規劃問題(Nonlinear Programming) ,
在非線性優化問題中,有一類比較特殊的問題是凸優化問題(Convex Programming),在凸優化問題中,變數
x
x
x的可行域為凸集,即對于集合中任意兩點,它們的連線全部位于在集合內部,目標函式
f
f
f也必須為凸函式,即滿足
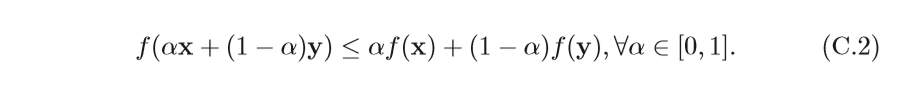
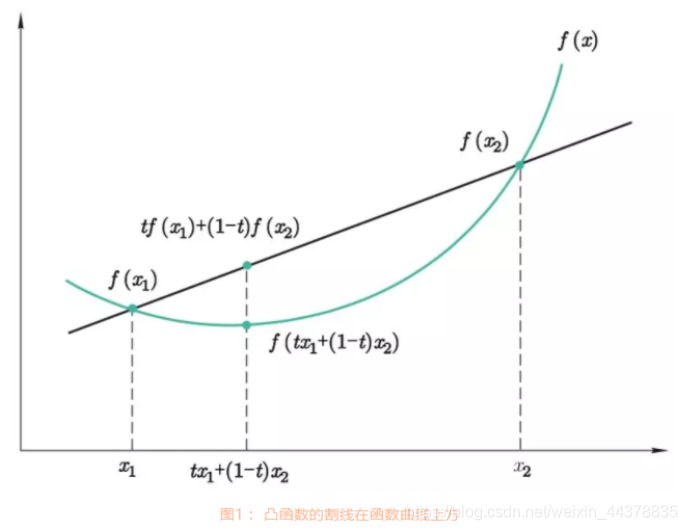
圖片來源:https://www.cnblogs.com/always-fight/p/9377554.html
凸優化問題是一種特殊的約束優化問題,需滿足目標函式為凸函式,并且等式約束函式為線性函式,不等式約束函式為凹函式,
在資料科學的模型求解中,如果優化的目標函式是凸函式,則區域極小值就是全域最小值,這也意味著我們求得的模型是全域最優的,不會陷入到區域最優值,
3.2 優化演算法
優化問題一般都是通過迭代的方式來求解:通過猜測一個初始的估計
x
0
x_0
x0?, 然后不斷迭代產生新的估計
x
1
,
x
2
,
?
?
?
x
t
x_1,x_2,···x_t
x1?,x2?,???xt?,希望
x
t
x_t
xt?最終收斂到期望的最優解
x
?
x^?
x?, 一個好的優化演算法應該是在一定的時間或空間復雜度下能夠快速準確地找到最優解,同時,好的優化演算法受初始猜測點的影響較小,通過迭代能穩定地找到 最優解
x
?
x^?
x?的鄰域,然后迅速收斂于
x
?
x^?
x?,
優化演算法中常用的迭代方法有線性搜索和置信域方法等,線性搜索的策略 是尋找方向和步長,具體演算法有梯度下降法、牛頓法、共軛梯度法等,
3.2.1 全域最優和區域最優
對于很多非線性優化問題,會存在若干個區域的極小值,區域最小值,或 區域最優解
x
?
x^?
x?定義為:存在一個
δ
>
0
δ > 0
δ>0,對于所有的滿足
∥
x
?
x
?
∥
≤
δ
∥x?x?∥≤ δ
∥x?x?∥≤δ的
x
x
x,公 式
f
(
x
?
)
≤
f
(
x
)
f(x?)≤ f(x)
f(x?)≤f(x)成立,也就是說,在
x
?
x^?
x?的附近區域內,所有的函式值都大于或 者等于
f
(
x
?
)
f(x^?)
f(x?),
對于所有的
x
∈
A
x∈ A
x∈A,都有
f
(
x
?
)
≤
f
(
x
)
f(x^?)≤ f(x)
f(x?)≤f(x)成立,則
x
?
x^?
x?為全域最小值,或全域最優解,
一般的,求區域最優解是容易的,但很難保證其為全域最優解,對于線性規劃或凸優化問題,區域最優解就是全域最優解,
要確認一個點
x
?
x^?
x?是否為區域最優解,通過比較它的鄰域內有沒有更小的函 數值是不現實的,如果函式
f
(
x
)
f(x)
f(x)是二次連續可微的,我們可以通過檢查目標函式在點
x
?
x^?
x?的梯度
?
f
(
x
?
)
?f(x^?)
?f(x?)和Hessian矩陣
?
2
f
(
x
?
)
?^2f(x^?)
?2f(x?)來判斷,



3.2.2 梯度下降法
梯度下降法(Gradient Descent Method),也叫最速下降法(Steepest Descend Method),經常用來求解無約束優化的極小值問題,
對于函式
f
(
x
)
f(x)
f(x),如果
f
(
x
)
f(x)
f(x)在點
x
t
x_t
xt? 附近是連續可微的,那么
f
(
x
)
f(x)
f(x)下降最快 的方向是
f
(
x
)
f(x)
f(x)在
x
t
x_t
xt?點的梯度方法的反方向,
根據泰勒一階展開公式,
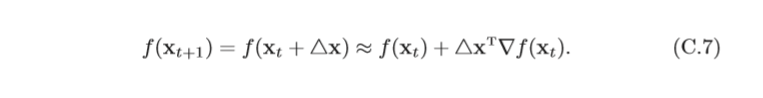
要使得
f
(
x
t
+
1
)
<
f
(
x
t
)
f(x_{t+1}) < f(x_t)
f(xt+1?)<f(xt?),就得使
△
x
T
?
f
(
x
t
)
<
0
△x^T?f(x_t) < 0
△xT?f(xt?)<0,我們取
△
x
=
?
α
?
f
(
x
t
)
△x=?α?f(x_t)
△x=?α?f(xt?), 如果
α
>
0
α > 0
α>0為一個夠小數值時,那么
f
(
x
t
+
1
)
<
f
(
x
t
)
f(x_{t+1}) < f(x_t)
f(xt+1?)<f(xt?)成立,
這樣我們就可以從一個初始值
x
0
x_0
x0? 出發,通過迭代公式
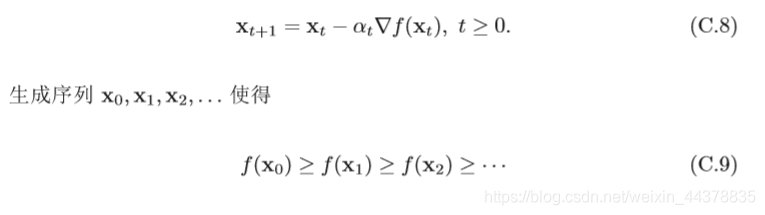
如果順利的話,序列
(
x
n
)
(x_n)
(xn?)收斂到區域最優解
x
?
x^?
x?,注意每次迭代步長
α
α
α可以改變,但其取值必須合適,如果過大就不會收斂,如果過小則收斂速度太慢,
梯度下降法的程序如圖C.1所示,曲線是等高線(水平集),即函式
f
f
f為不同 常數的集合構成的曲線,紅色的箭頭指向該點梯度的反方向(梯度方向與通過該點的等高線垂直),沿著梯度下降方向,將最終到達函式
f
f
f值的區域最優解,
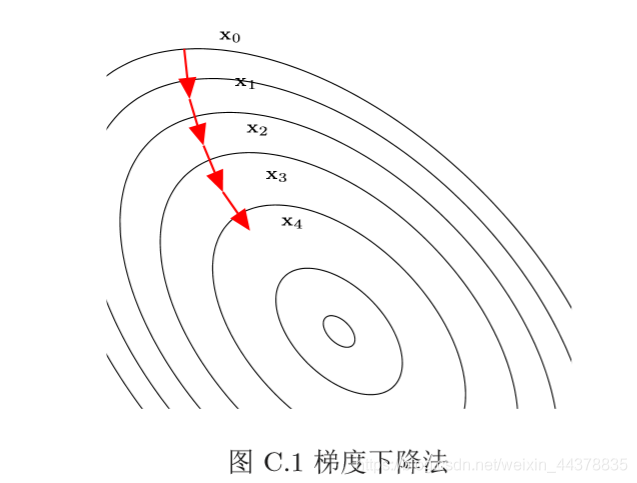
梯度下降法為一階收斂演算法,當靠近極小值時梯度變小,收斂速度會變慢, 并且可能以“之字形”的方式下降,如果目標函式為二階連續可微,我們可以采用牛頓法,牛頓法為二階收斂演算法,收斂速度更快,但是每次迭代需要計算 Hessian矩陣的逆矩陣,復雜較高,
相反,如果我們要求解一個最大值問題,就需要向梯度正方向迭代進行搜 索,逐漸接近函式的區域極大值點,這個程序則被稱為梯度上升法(Gradient Ascent),
3.2.3 拉格朗日乘數法與KKT條件
拉格朗日乘數法(Lagrange Multiplier)是約束優化問題的一種有效求解 方法,約束優化問題可以表示為

等式約束優化問題
如果公式(C.10)中只有等式約束,我們可以構造一個拉格朗日函式
Λ
(
x
,
λ
)
Λ(x,λ)
Λ(x,λ)
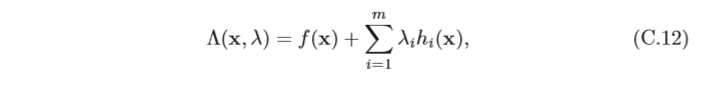
其中
λ
λ
λ為拉格朗日乘數,可以是正數或負數,如果
f
(
x
?
)
f(x^?)
f(x?)是原始約束優化問題 的區域最優值,那么存在一個KaTeX parse error: Expected group after '^' at position 3: λ?^?使得
(
x
?
,
λ
?
)
(x^?,λ^?)
(x?,λ?)為拉格朗日函式
Λ
(
x
,
λ
)
Λ(x,λ)
Λ(x,λ)的平穩點 (stationary point)(平穩點是指一階偏導數為 0 的點,平穩點不一定為極值點),因此,只需要令
?
Λ
(
x
,
λ
)
?
x
=
0
和
?
Λ
(
x
,
λ
)
?
λ
=
0
\frac{\partial Λ(x,λ)}{\partial x}=0和\frac{\partial Λ(x,λ)}{\partial\lambda}=0
?x?Λ(x,λ)?=0和?λ?Λ(x,λ)?=0,得到:
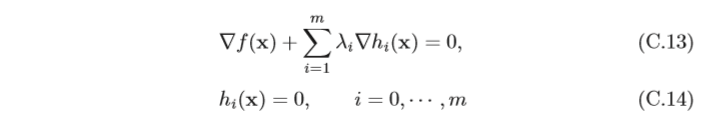
上面方程組的解即為原始問題的可能解,在實際應用中,需根據問題來驗證是 否為極值點,
拉格朗日乘數法是將一個有
d
d
d個變數和
m
m
m個等式約束條件的最優化問題轉 換為一個有
d
+
m
d+m
d+m個變數的函式求平穩點的問題,拉格朗日乘數法所得的平穩 點會包含原問題的所有極值點,但并不保證每個平穩點都是原問題的極值點
不等式約束優化問題
對于公式(C.10)中定義的一般約束優化問題,其拉格朗日函式為
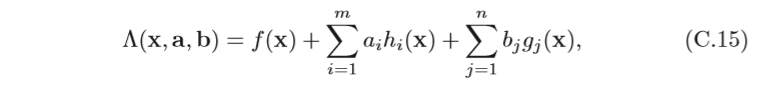
其中
a
=
[
a
1
,
?
?
?
,
a
m
]
T
a =[a_1,··· ,a_m]^T
a=[a1?,???,am?]T為等式約束的拉格朗日乘數,
b
=
[
b
1
,
?
?
?
,
b
n
]
T
b=[b_1,··· ,b_n]^T
b=[b1?,???,bn?]T 為不等式 約束的拉格朗日乘數,
當約束條件不滿足時,有
m
a
x
a
,
b
Λ
(
x
,
a
,
b
)
=
∞
max_{a,b}Λ(x,a,b) = ∞
maxa,b?Λ(x,a,b)=∞;當約束條件滿足時并且
b
≥
0
b≥0
b≥0時,
m
a
x
a
,
b
Λ
(
x
,
a
,
b
)
=
f
(
x
)
max_{a,b}Λ(x,a,b)= f(x)
maxa,b?Λ(x,a,b)=f(x),因此原始約束優化問題等價于

對偶問題 主問題的優化一般比較困難,我們可以通過交換
m
i
n
?
m
a
x
min-max
min?max的順序來簡化,定義拉格朗日對偶函式為
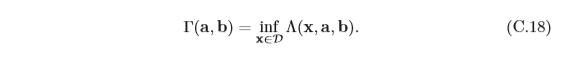
Γ
(
a
,
b
)
Γ(a,b)
Γ(a,b)是一個凹函式,即使
f
(
x
)
f(x)
f(x)是非凸的,

優化拉格朗日對偶函式
Γ
(
a
,
b
)
Γ(a,b)
Γ(a,b)并得到原問題的最優下界,稱為拉格朗日對 偶問題(Lagrange Dual Problem),
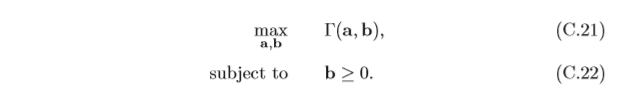
拉格朗日對偶函式為凹函式,因此拉格朗日對偶問題為凸優化問題,
令
d
?
d^?
d?是拉格朗日對偶問題的最優值,則有
d
?
≤
p
?
d^? ≤ p^?
d?≤p?,這個性質稱為弱對偶 性(Weak Duality),如果
d
?
=
p
?
d^? = p^?
d?=p?,這個性質稱為強對偶性(Strong Duality)
當強對偶性成立時,令
x
?
x^?
x?和
a
?
,
b
?
a^?,b^?
a?,b?分別是原問題問題和對偶問題的最優解, 那么它們滿足以下條件:
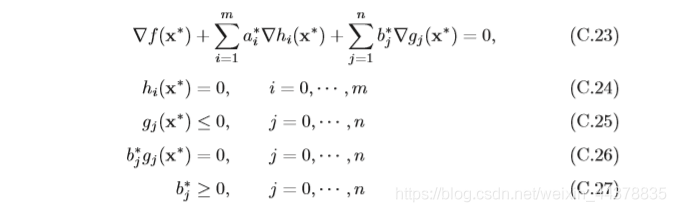
稱為不等式約束優化問題的KKT條件(Karush-Kuhn-TuckerConditions),KKT 條件是拉格朗日乘數法在不等式約束優化問題上的泛化,當原問題是凸優化問 題時,滿足KKT條件的解也是原問題和對偶問題的最優解,
KKT條件中需要關注的是公式(C.26),稱為互補松弛條件(Complementary Slackness),如果最優解 x ? x^? x?出現在不等式約束的邊界上 g j ( x ) = 0 g_j(x) = 0 gj?(x)=0,則 b j ? > 0 b^?_ j > 0 bj??>0; 如果x?出現在不等式約束的內部 g j ( x ) < 0 g_j(x) < 0 gj?(x)<0,則 b j ? = 0 b^?_ j =0 bj??=0,互補松弛條件說明當最 優解出現在不等式約束的內部,則約束失效,
4 概率論與隨機程序
概率論主要研究大量隨機現象中的數量規律,其應用十分廣泛,幾乎遍及各個領域,
4.1 樣本空間
樣本空間是一個隨機試驗所有可能結果的集合,例如,如果拋擲一枚硬幣, 那么樣本空間就是集合{正面,反面},如果投擲一個骰子,那么樣本空間就是 {1,2,3,4,5,6},隨機試驗中的每個可能結果稱為樣本點,
有些試驗有兩個或多個可能的樣本空間,例如,從52張撲克牌中隨機抽出 一張,樣本空間可以是數字(A到K),也可以是花色(黑桃,紅桃,梅花,方 塊),如果要完整地描述一張牌,就需要同時給出數字和花色,這時樣本空間可以通過構建上述兩個樣本空間的笛卡兒乘積來得到,

4.2 事件和概率
隨機事件(或簡稱事件)指的是一個被賦予概率的事物集合,也就是樣本空間中的一個子集,概率(Probability)表示一個隨機事件發生的可能性大小, 為0到1之間的一個非負實數,比如,一個0.5的概率表示一個事件有50%的可能性發生,
對于一個機會均等的拋硬幣動作來說,其樣本空間為“正面”或“反面”, 我們可以定義各個隨機事件,并計算其概率,比如,

4.2.1 隨機變數
在隨機試驗中,試驗的結果可以用一個數X 來表示,這個數X 是隨著試 驗結果的不同而變化的,是樣本點的一個函式,我們把這種數稱為隨機變數 (Random Variable),例如,隨機擲一個骰子,得到的點數就可以看成一個隨機變數
X
X
X,
X
X
X的取值為{1,2,3,4,5,6},
如果隨機擲兩個骰子,整個事件空間
?
?
?可以由36個元素組成:
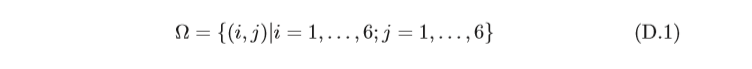
一個隨機事件也可以定義多個隨機變數,比如在擲兩個骰子的隨機事件中, 可以定義隨機變數X 為獲得的兩個骰子的點數和,也可以定義隨機變數Y 為獲 得的兩個骰子的點數差,隨機變數X 可以有11個整數值,而隨機變數Y 只有6 個,
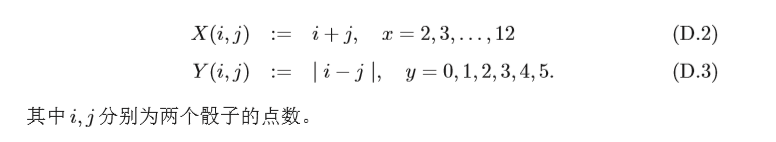 #### 離散隨機變數
#### 離散隨機變數
如果隨機變數X 所可能取的值為有限可列舉的,有
n
n
n個有限取值
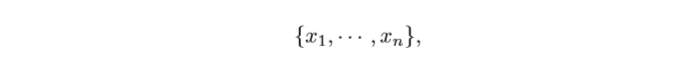
則稱
X
X
X為離散隨機變數,
要了解
X
X
X 的統計規律,就必須知道它取每種可能值
x
i
x_i
xi? 的概率,即
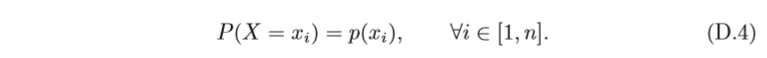
p
(
x
)
1
)
,
?
?
?
,
p
(
x
n
)
p(x)1),··· ,p(x_n)
p(x)1),???,p(xn?)稱為離散型隨機變數
X
X
X的概率分布(Probability Distribution) 或分布,并且滿足

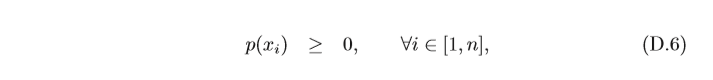
注:一般用大寫的字母表示一個隨機變數,用小字字母表示 該變數的某一個具體的取值,
常見的離散隨機變數的概率分布有:
伯努利分布 在一次試驗中,事件
A
A
A出現的概率為
μ
μ
μ,不出現的概率為
1
?
μ
1?μ
1?μ,若 用變數
X
X
X 表示事件
A
A
A出現的次數,則
X
X
X 的取值為0和1,其相應的分布為
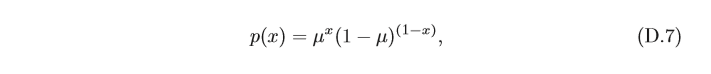
這個分布稱為伯努利分布(Bernoulli Distribution) ,又名兩點分布或者0-1分布,
二項分布 在
n
n
n次伯努利分布中,若以變數
X
X
X 表示事件
A
A
A出現的次數,則
X
X
X 的 取值為
0
,
?
?
?
,
n
{0,··· ,n}
0,???,n,其相應的分布為二項分布(Binomial Distribution),


連續隨機變數
與離散隨機變數不同,一些隨機變數X 的取值是不可列舉的,由全部實數 或者由一部磁區間組成,比如

對于連續隨機變數
X
X
X,它取一個具體值
x
i
x_i
xi? 的概率為0,這與離散隨機變數 截然不同,因此用列舉連續隨機變數取某個值的概率來描述這種隨機變數不但 做不到,也毫無意義,
連續隨機變數
X
X
X的概率分布一般用概率密度函式(Probability Density Function,PDF)
p
(
x
)
p(x)
p(x)來描述,
p
(
x
)
p(x)
p(x)為可積函式,并滿足
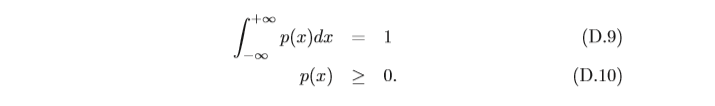
給定概率密度函式
p
(
x
)
p(x)
p(x),便可以計算出隨機變數落入某一個區間的概率,而
p
(
x
)
p(x)
p(x)本身反映了隨機變數取落入
x
x
x的非常小的鄰近區間中的概率大小,
常見的連續隨機變數的概率分布有:
均勻分布 若
a
,
b
a,b
a,b為有限數,
[
a
,
b
]
[a,b]
[a,b]上的均勻分布(Uniform Distribution)的概率密度函式定義為
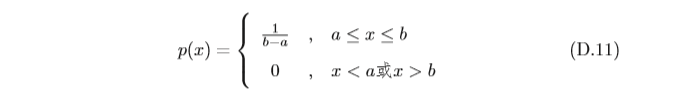
正態分布 正態分布(Normal Distribution),又名高斯分布(Gaussian Distribution),是自然界最常見的一種分布,并且具有很多良好的性質,在很多領域 都有非常重要的影響力,其概率密度函式為

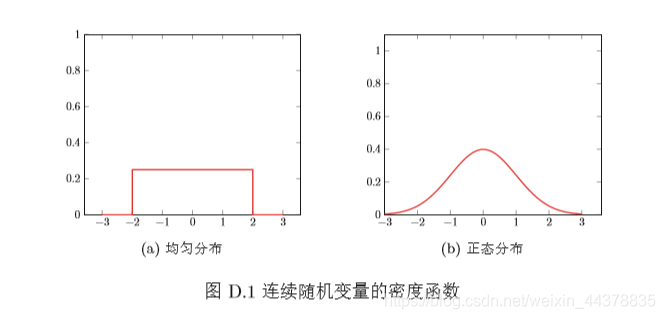
圖D.1a和D.1b分別顯示了均勻分布和正態分布的概率密度函式,
累積分布函式
對于一個隨機變數
X
X
X,其累積分布函式(Cumulative Distribution Function, CDF)是隨機變數
X
X
X 的取值小于等于
x
x
x的概率,
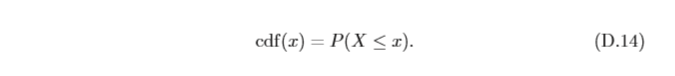
以連續隨機變數
X
X
X 為例,累積分布函式定義為
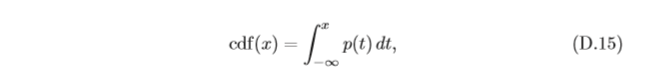
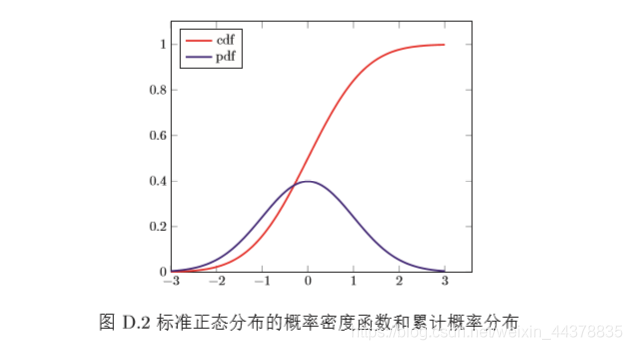
其中
p
(
x
)
p(x)
p(x)為概率密度函式,圖D.2給出了標準正態分布的累計分布函式,
4.2.2 隨機向量
隨機向量是指一組隨機變數構成的向量,如果
X
1
,
X
2
,
?
?
?
,
X
n
X_1,X_2,··· ,X_n
X1?,X2?,???,Xn?為
n
n
n個隨機 變數, 那么稱
[
X
1
,
X
2
,
?
?
?
,
X
n
]
[X_1,X_2,··· ,X_n]
[X1?,X2?,???,Xn?]為一個
n
n
n維隨機向量,一維隨機向量稱為隨機變數,
隨機向量也分為離散隨機向量和連續隨機向量,
離散隨機向量
離散隨機向量的聯合概率分布(Joint Probability Distribution)為
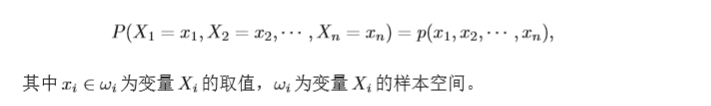
和離散隨機變數類似,離散隨機向量的概率分布滿足
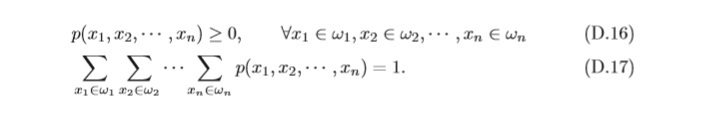
多項分布 一個常見的離散向量概率分布為多項分布(Multinomial Distribution),多項分布是二項分布在隨機向量的推廣,假設一個袋子中裝了很多球, 總共有
K
K
K 個不同的顏色,我們從袋子中取出
n
n
n個球,每次取出一個球時,就在袋子中放入一個同樣顏色的球,這樣保證同一顏色的球在不同試驗中被取出的 概率是相等的,令
X
X
X為一個
K
K
K 維隨機向量,每個元素
X
k
(
k
=
1
,
?
?
?
,
K
)
X_k(k =1,··· ,K)
Xk?(k=1,???,K)為取出的
n
n
n個球中顏色為k的球的數量,則
X
X
X服從多項分布,其概率分布為

多項分布的概率分布也可以用gamma函式表示:

連續隨機向量
連續隨機向量的其聯合概率密度函式(Joint Probability Density Function) 滿足
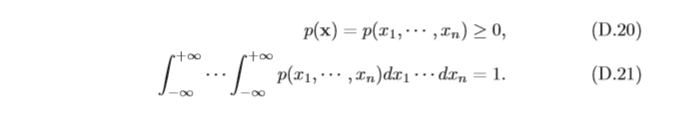
多元正態分布 一個常見的連續隨機向量分布為多元正態分布(Multivariate Normal Distribution),也稱為多元高斯分布(Multivariate Gaussian Distribution) ,若
n
n
n維隨機向量
X
=
[
X
1
,
.
.
.
,
X
n
]
T
X=[X_1,...,X_n]^T
X=[X1?,...,Xn?]T服從
n
n
n元正態分布,其密度函式為
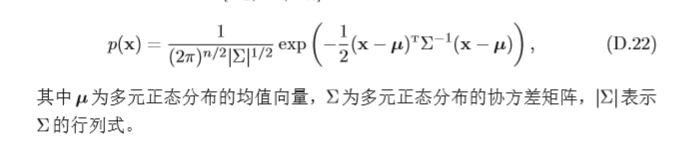
各項同性高斯分布 如果一個多元高斯分布的協方差矩陣簡化為
Σ
=
σ
2
I
Σ= σ^2I
Σ=σ2I,即每 一個維隨機變數都獨立并且方差相同,那么這個多元高斯分布稱為各項同性高 斯分布(Isotropic Gaussian Distribution),
Dirichlet分布 一個
n
n
n維隨機向量
X
X
X的Dirichlet分布為

4.2.3 邊際分布
對于二維離散隨機向量
(
X
,
Y
)
(X,Y)
(X,Y),假設X 取值空間為
?
x
,
Y
?_x,Y
?x?,Y取值空間為
?
y
?_y
?y?, 其聯合概率分布滿足
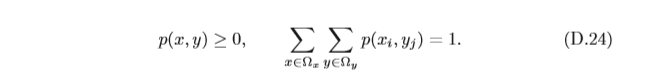
對于聯合概率分布
p
(
x
,
y
)
p(x,y)
p(x,y),我們可以分別對
x
x
x和
y
y
y進行求和,
(1)對于固定的
x
x
x,
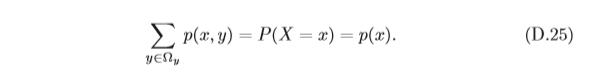
(2)對于固定的y,
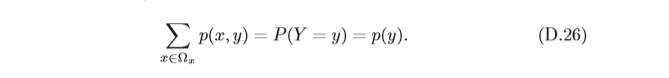
由離散隨機向量
(
X
,
Y
)
(X,Y)
(X,Y)的聯合概率分布,對
Y
Y
Y 的所有取值進行求和得到
X
X
X 的概率分布;而對
X
X
X 的所有取值進行求和得到
Y
Y
Y 的概率分布,這里
p
(
x
)
p(x)
p(x)和
p
(
y
)
p(y)
p(y) 就稱為
p
(
x
,
y
)
p(x,y)
p(x,y)的邊際分布(Marginal Distribution),
對于二維連續隨機向量
(
X
,
Y
)
(X,Y)
(X,Y),其邊際分布為:
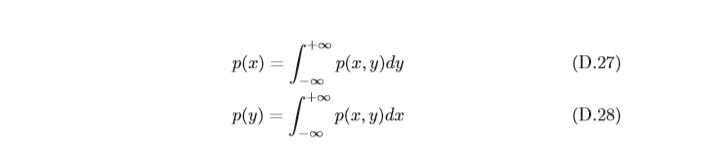
一個二元正態分布的邊際分布仍為正態分布,
不失一般性,以上對二維隨 機向量進行討論,這些結論 在多維時依然成立,
4.2.4 條件概率分布
對于離散隨機向量
(
X
,
Y
)
(X,Y)
(X,Y),已知
X
=
x
X = x
X=x的條件下,隨機變數
Y
=
y
Y = y
Y=y的條件 概率(Conditional Probability)為:

對于二維連續隨機向量
(
X
,
Y
)
(X,Y)
(X,Y),已知
X
=
x
X = x
X=x的條件下,隨機變數
Y
=
y
Y = y
Y=y的 條件概率密度函式(Conditional Probability Density Function)為
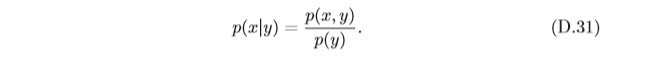
通過公式(D.30)和(D.31),我們可以得到兩個條件概率
p
(
y
∣
x
)
p(y|x)
p(y∣x)和
p
(
x
∣
y
)
p(x|y)
p(x∣y)之 間的關系,
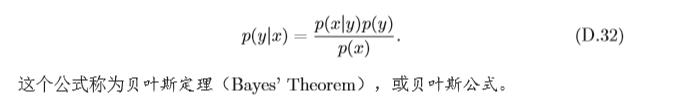
4.2.5 獨立與條件獨立
對于兩個離散(或連續)隨機變數
X
X
X 和
Y
Y
Y ,如果其聯合概率(或聯合概率 密度函式)
p
(
x
,
y
)
p(x,y)
p(x,y)滿足
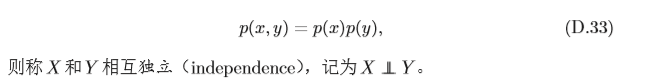
對于三個離散(或連續)隨機變數
X
X
X、
Y
Y
Y 和
Z
Z
Z,如果條件概率(或聯合概 率密度函式)
p
(
x
,
y
∣
z
)
p(x,y|z)
p(x,y∣z)滿足

4.2.6 期望和方差
期望 對于離散變數
X
X
X,其概率分布為
p
(
x
1
)
,
?
?
?
,
p
(
x
n
)
p(x_1),··· ,p(x_n)
p(x1?),???,p(xn?),
X
X
X的期望(Expectation) 或均值定義為
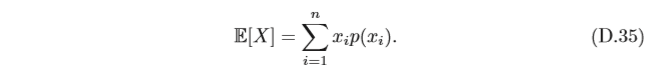
對于連續隨機變數
X
X
X,概率密度函式為
p
(
x
)
p(x)
p(x),其期望定義為
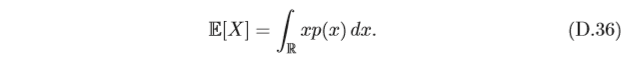
方差 隨機變數X的方差(Variance)用來定義它的概率分布的離散程度,定義為
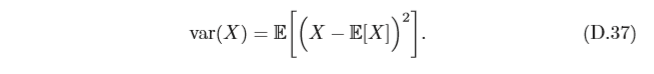
隨機變數
X
X
X 的方差也稱為它的二階矩,
v
a
r
(
X
)
\sqrt{var(X)}
var(X)
?則稱為
X
X
X 的根方差或標準差 ,
協方差 兩個連續隨機變數
X
X
X 和
Y
Y
Y 的協方差(Covariance)用來衡量兩個隨機變 量的分布之間的總體變化性,定義為
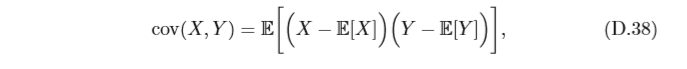
協方差經常也用來衡量兩個隨機變數之間的線性相關性(這里的線性相關和線性代數 中的線性相關含義不同),如果兩個隨機變 量的協方差為0,那么稱這兩個隨機變數是線性不相關,兩個隨機變數之間沒有線性相關性,并非表示它們之間獨立的,可能存在某種非線性的函式關系,反 之,如果
X
X
X與
Y
Y
Y 是統計獨立的,那么它們之間的協方差一定為0,
協方差矩陣 兩個
m
m
m和
n
n
n維的連續隨機向量
X
X
X和
Y
Y
Y,它們的協方差(Covariance) 為
m
×
n
m×n
m×n的矩陣,定義為
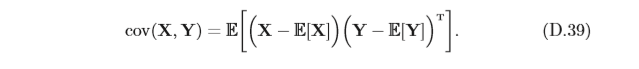
協方差矩陣
c
o
v
(
X
,
Y
)
cov(X,Y)
cov(X,Y)的第
(
i
,
j
)
(i,j)
(i,j)個元素等于隨機變數
X
i
X_i
Xi?和
Y
j
Y_j
Yj? 的協方差,兩 個向量變數的協方差
c
o
v
(
X
,
Y
)
cov(X,Y)
cov(X,Y)與cov(Y,X)互為轉置關系,
如果兩個隨機向量的協方差矩陣為對角陣,那么稱這兩個隨機向量是無 關的,
單個隨機向量X的協方差矩陣定義為
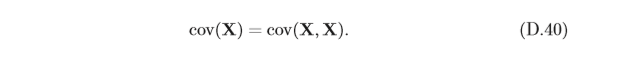
Jensen不等式
如果
X
X
X 是隨機變數,
g
g
g是凸函式,則

大數定律
大數定律(Law Of Large Numbers)是指
n
n
n個樣本
X
1
,
?
?
?
,
X
n
X_1,··· ,X_n
X1?,???,Xn? 是獨立同分布的,即
E
[
X
1
]
=
?
?
?
=
E
[
X
n
]
=
μ
E[X_1]=···= E[X_n]= μ
E[X1?]=???=E[Xn?]=μ,那么其均值
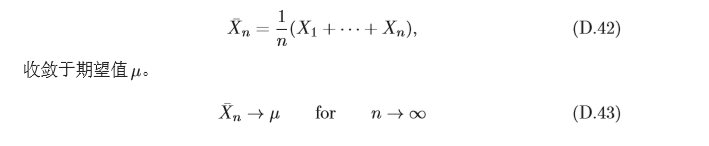
4.3 隨機程序
隨機程序(Stochastic Process)是一組隨機變數 X t X_t Xt? 的集合,其中t屬于一 個索引(index)集合 T T T,索引集合 T T T 可以定義在時間域或者空間域,但一般為 時間域,以實數或正數表示,當 t t t為實數時,隨機程序為連續隨機程序;當 t t t為 整數時,為離散隨機程序,日常生活中的很多例子包括股票的波動、語音信號、 身高的變化等都可以看作是隨機程序,常見的和時間相關的隨機程序模型包括 貝努力程序、隨機游走、馬爾可夫程序等,和空間相關的隨機程序通常稱為隨 機場(Random Field),比如一張二維的圖片,每個像素點(變數)通過空間 的位置進行索引,這些像素就組成了一個隨機程序,
4.3.1 馬爾可夫程序
馬爾可夫性質 在隨機程序中,馬爾可夫性質(MarkovProperty)是指一個隨機 程序在給定現在狀態及所有過去狀態情況下,其未來狀態的條件概率分布僅依 賴于當前狀態,以離散隨機程序為例,假設隨機變數
X
0
,
X
1
,
?
?
?
,
X
T
X_0,X_1,··· ,X_T
X0?,X1?,???,XT? 構成一個 隨機程序,這些隨機變數的所有可能取值的集合被稱為狀態空間(State Space) ,如果
X
t
+
1
X_{t+1}
Xt+1? 對于過去狀態的條件概率分布僅是
X
t
X_t
Xt? 的一個函式,則
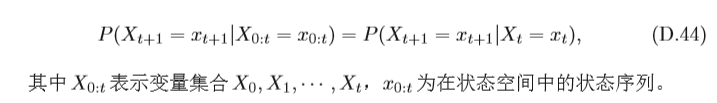
馬爾可夫性質也可以描述為給定當前狀態時,將來的狀態與過去狀態是條 件獨立的,
馬爾可夫鏈
離散時間的馬爾可夫程序也稱為馬爾可夫鏈(Markov Chain),如果一個 馬爾可夫鏈的條件概率
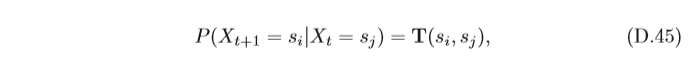
在不同時間都是不變的,即和時間
t
t
t無關,則稱為時間同質的馬爾可夫鏈(TimeHomogeneous Markov Chains),如果狀態空間是有限的,
T
(
s
i
,
s
j
)
T(s_i,s_j)
T(si?,sj?)也可以用一 個矩陣
T
T
T 表示,稱為狀態轉移矩陣(Transition Matrix),其中元素
t
i
j
t_{ij}
tij? 表示狀 態
s
i
s_i
si? 轉移到狀態
s
j
s_j
sj? 的概率,
平穩分布 假設狀態空間大小為
M
M
M,向量
π
=
[
π
1
,
?
?
?
,
π
M
]
T
π = [π_1,··· ,π_M]^T
π=[π1?,???,πM?]T 為狀態空間中的一 個分布,滿足
0
≤
π
i
≤
1
0≤ π_i ≤1
0≤πi?≤1和
∑
i
=
1
M
π
i
=
1
\sum^M_{i=1}\pi_i=1
∑i=1M?πi?=1
對于狀態轉移矩陣為
T
T
T的時間同質的馬爾可夫鏈,如果存在一個分布
π
π
π滿足
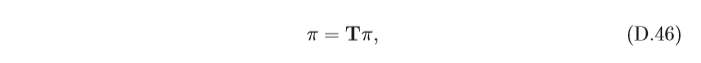
即分布π就稱為該馬爾可夫鏈的平穩分布(Stationary Distribution),根據特 征向量的定義可知,
π
π
π為矩陣
T
T
T的(歸一化)的對應特征值為1的特征向量,
如果一個馬爾可夫鏈的狀態轉移矩陣
T
T
T滿足所有狀態可遍歷性以及非周期性,那么對于任意一個初始狀態分布
π
(
0
)
π(0)
π(0),將經過一定時間的狀態轉移之后,都 會收斂到平穩分布,即
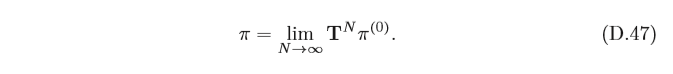

4.3.2 高斯程序
高斯程序(Gaussian Process)也是一種應用廣泛的隨機程序模型,假設有 一組連續隨機變數
X
0
,
X
1
,
?
?
?
,
X
T
X_0,X_1,··· ,X_T
X0?,X1?,???,XT?,如果由這組隨機變數構成的任一有限集合
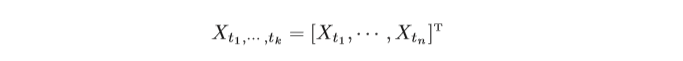
都服從一個多元正態分布,那么這組隨機變數為一個隨機程序,高斯程序也可 以定義為:如果
X
t
1
,
?
?
?
,
t
n
X_{t_1,···,t_n}
Xt1?,???,tn?? 的任一線性組合都服從一元正態分布,那么這組隨機 變數為一個隨機程序,
高斯程序回歸 高斯程序回歸(Gaussian Process Regression)是利用高斯程序 來對一個函式分布進行建模,和機器學習中引數化建模(比如貝葉斯線性回歸) 相比,高斯程序是一種非引數模型,可以擬合一個黑盒函式,并給出擬合結果的置信度
假設一個未知函式
f
(
x
)
f(x)
f(x)服從高斯程序,且為平滑函式,如果兩個樣本
x
1
,
x
2
x_1,x_2
x1?,x2? 比較接近,那么對應的
f
(
x
1
)
,
f
(
x
2
)
f(x_1),f(x_2)
f(x1?),f(x2?)也比較接近,假設從函式f(x)中采樣有限 個樣本
X
=
[
x
1
,
x
2
,
?
?
?
,
x
N
]
X =[x_1,x_2,··· ,x_N]
X=[x1?,x2?,???,xN?],這
N
N
N個點服從一個多元正態分布,
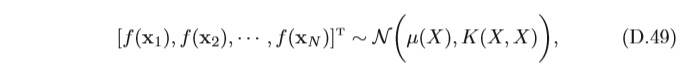
其中
μ
(
X
)
=
[
μ
(
x
1
)
,
μ
(
x
2
)
,
?
?
?
,
μ
(
x
N
)
]
T
μ(X)=[μ(x_1),μ(x_2),··· ,μ(x_N)]^T
μ(X)=[μ(x1?),μ(x2?),???,μ(xN?)]T是均值向量,
K
(
X
,
X
)
=
[
k
(
x
i
,
x
j
)
]
N
×
N
K(X,X)=[k(x_i,x_j)]_{N×N}
K(X,X)=[k(xi?,xj?)]N×N? 是協方差矩陣,
k
(
x
i
,
x
j
)
k(x_i,x_j)
k(xi?,xj?)為核函式,可以衡量兩個樣本的相似度,
在高斯程序回歸,一個常用的核函式是平方指數(Squared Exponential)函式(在支持向量機中,平方指數核函式也叫高斯核函式或徑 向基函式,這里為了避免混 淆,我們稱為平方指數核函式,)
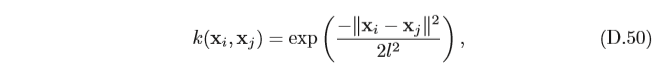
其中
l
l
l為超引數,當
x
i
x_i
xi? 和
x
j
x_j
xj? 越接近,其核函式的值越大,表明
f
(
x
i
)
f(x_i)
f(xi?)和
f
(
x
j
)
f(x_j)
f(xj?)越 相關,
假設
f
(
x
)
f(x)
f(x)的一組帶噪聲的觀測值為
(
x
n
,
y
n
)
n
=
1
N
{(xn,yn)}^N_{n=1}
(xn,yn)n=1N?,其中
y
n
~
N
(
f
(
x
n
)
,
σ
2
)
y_n ~N(f(x_n),σ^2)
yn?~N(f(xn?),σ2) 為正態分布,
σ
σ
σ為噪聲方差,
對于一個新的樣本點
x
?
x^?
x?,我們希望預測函式
y
?
=
f
(
x
?
)
y^? = f(x^?)
y?=f(x?),令
y
=
[
y
1
,
y
2
,
?
?
?
,
y
n
]
y=[y_1,y_2,··· ,y_n]
y=[y1?,y2?,???,yn?] 為已有的觀測值,根據高斯程序的假設,
[
y
;
y
?
]
[y;y^?]
[y;y?]滿足
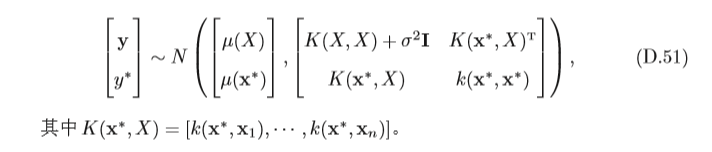
根據上面的聯合分布,
y
?
y^?
y?的后驗分布為
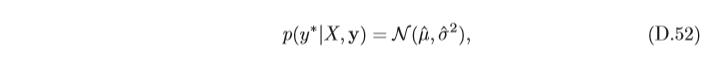
其中均值
μ
^
\hat{μ}
μ^和方差
σ
^
\hat{σ}
σ^為
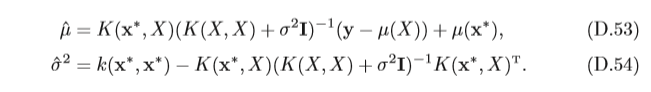
公式(D.53)可以看出,均值函式
μ
(
x
)
μ(x)
μ(x)可以近似地互相抵消,在實際應用 中,一般假設
μ
(
x
)
=
0
μ(x)=0
μ(x)=0,均值
μ
^
\hat{\mu}
μ^?可以簡化為:
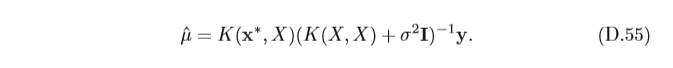
高斯程序回歸可以認為是一種有效的貝葉斯優化方法,廣泛地應用于機器 學習中,
5 資訊論
資訊論(Information Theory)是數學、物理、統計、計算機科學等多個學科的 交叉領域,資訊論是由 Claude Shannon最早提出的,主要研究資訊的量化、存 儲和通信等方法,這里,“資訊”是指一組訊息的集合,假設在一個噪聲通道上發送訊息,我們需要考慮如何對每一個資訊進行編碼、傳輸以及解碼,使得接 收者可以盡可能準確地重構出訊息,
在機器學習相關領域,資訊論也有著大量的應用,比如特征抽取、統計推斷、自然語言處理等,
5.1 熵
5.1.1 自資訊和熵
熵(Entropy)最早是物理學的概念,用于表示一個熱力學系統的無序程度, 在資訊論中,熵用來衡量一個隨機事件的不確定性,假設對一個隨機變數
X
X
X(取值集合為
X
X
X,概率分布為
p
(
x
)
,
x
∈
X
p(x),x ∈X
p(x),x∈X進行編碼,自資訊
I
(
x
)
I(x)
I(x)是變數
X
=
x
X = x
X=x時 的資訊量或編碼長度,定義為
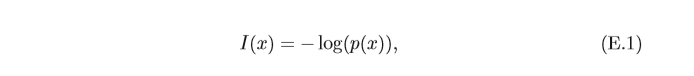
那么隨機變數
X
X
X 的平均編碼長度,即熵定義為
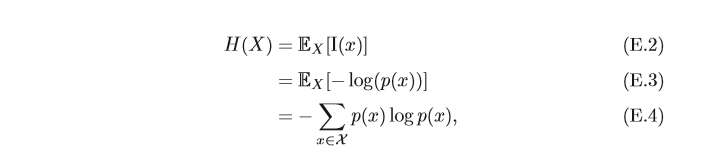
其中當
p
(
x
i
)
=
0
p(x_i)=0
p(xi?)=0時,我們定義
0
l
o
g
0
=
0
0log0=0
0log0=0,這與極限一致,
l
i
m
p
→
0
+
p
l
o
g
p
=
0
lim_{p→0}+ plogp =0
limp→0?+plogp=0
注:在熵的定義中,對數的底可 以使用2、自然常數e,或是 10,
熵是一個隨機變數的平均編碼長度,即自資訊的數學期望,熵越高,則隨機變數的資訊越多;熵越低,則資訊越少,如果變數
X
X
X當且僅當在
x
x
x時
p
(
x
)
=
1
p(x)=1
p(x)=1, 則熵為0,也就是說,對于一個確定的資訊,其熵為0,資訊量也為0,如果其概率 分布為一個均勻分布,則熵最大,假設一個隨機變數
X
X
X 有三種可能值
x
1
,
x
2
,
x
3
x_1,x_2,x_3
x1?,x2?,x3?, 不同概率分布對應的熵如下:

5.2 聯合熵和條件熵

5.2 互資訊
互資訊(Mutual Information)是衡量已知一個變數時,另一個變數不確定 性的減少程度,兩個離散隨機變數
X
X
X 和
Y
Y
Y 的互資訊定義為
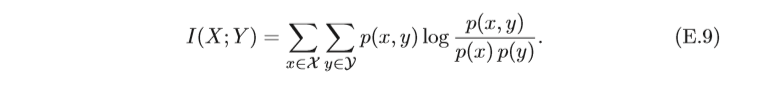
互資訊的一個性質為
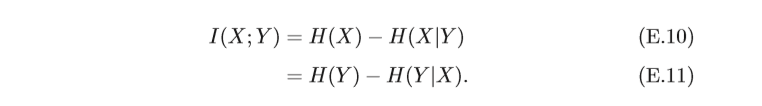
如果
X
X
X 和
Y
Y
Y 相互獨立,即
X
X
X 不對
Y
Y
Y提供任何資訊,反之亦然,因此它們的互資訊為零,
5.3 交叉熵和散度
5.3.1 交叉熵
對應分布為
p
(
x
)
p(x)
p(x)的隨機變數,熵
H
(
p
)
H(p)
H(p)表示其最優編碼長度,交叉熵(Cross Entropy)是按照概率分布
q
q
q的最優編碼對真實分布為
p
p
p的資訊進行編碼的長度, 定義為
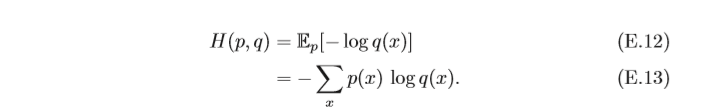
在給定p的情況下,如果
q
q
q和
p
p
p越接近,交叉熵越小;如果
q
q
q和
p
p
p越遠,交叉熵就越大,
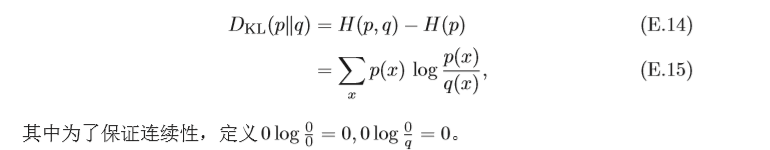
5.3.2 KL散度
KL散度(Kullback-Leibler Divergence),也叫KL距離或相對熵(Relative Entropy),是用概率分布q來近似p時所造成的資訊損失量,KL散度是按照概 率分布
q
q
q的最優編碼對真實分布為
p
p
p的資訊進行編碼,其平均編碼長度
H
(
p
,
q
)
H(p,q)
H(p,q) 和
p
p
p的最優平均編碼長度
H
(
p
)
H(p)
H(p)之間的差異,對于離散概率分布
p
p
p和
q
q
q,從
q
q
q到
p
p
p 的KL散度定義為
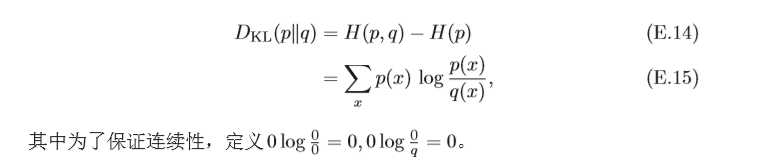
KL散度可以是衡量兩個概率分布之間的距離,KL散度總是非負的,
D
K
L
(
p
∥
q
)
≥
0
D_{KL}(p∥q)≥ 0
DKL?(p∥q)≥0,只有當
p
=
q
p = q
p=q時,
D
K
L
(
p
∥
q
)
=
0
D_{KL}(p∥q)=0
DKL?(p∥q)=0,如果兩個分布越接近,KL散度越小;如果 兩個分布越遠,KL散度就越大,但KL散度并不是一個真正的度量或距離,一 是KL散度不滿足距離的對稱性,二是KL散度不滿足距離的三角不等式性質,
5.3.3 JS散度
JS散度(Jensen–Shannon Divergence)是一種對稱的衡量兩個分布相似度 的度量方式,定義為
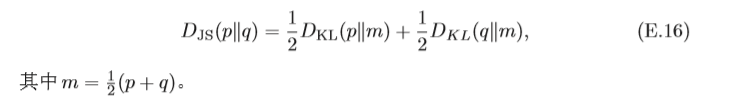
JS散度是KL散度一種改進,但兩種散度有存在一個問題,即如果兩個分布
p
,
q
p,q
p,q個分布沒有重疊或者重疊非常少時,KL散度和JS散度都很難衡量兩個分布的距離,
5.3.4 Wasserstein距離
Wasserstein距離(Wasserstein Distance)也是用于衡量兩個分布之間的距離,對于兩個分布
q
1
,
q
2
q_1,q_2
q1?,q2?,
p
t
h
?
W
a
s
s
e
r
s
t
e
i
n
p^{th}-Wasserstein
pth?Wasserstein距離定義為
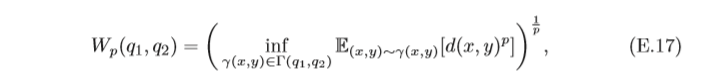
其中
Γ
(
q
1
,
q
2
)
Γ(q1,q2)
Γ(q1,q2)是邊際分布為
q
1
q_1
q1?和
q
2
q_2
q2?的所有可能的聯合分布集合,
d
(
x
,
y
)
d(x,y)
d(x,y)為
x
x
x和
y
y
y的距離,比如
l
p
l_p
lp? 距離等,
如果將兩個分布看作是兩個土堆,聯合分布
γ
(
x
,
y
)
γ(x,y)
γ(x,y)看作是從土堆
q
1
q_1
q1?的位置 x到土堆
q
2
q_2
q2? 的位置
y
y
y的搬運土的數量,并有
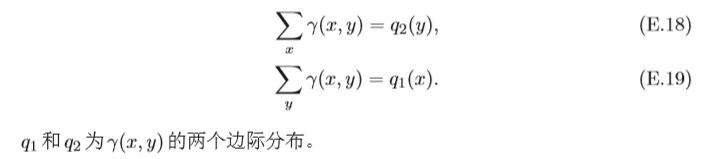
E
(
x
,
y
)
~
γ
(
x
,
y
)
[
d
(
x
,
y
)
p
]
E_{(x,y)~γ(x,y)}[d(x,y)^p]
E(x,y)~γ(x,y)?[d(x,y)p]可以理解為在聯合分布
γ
(
x
,
y
)
γ(x,y)
γ(x,y)下把形狀為
q
1
q_1
q1? 的土堆搬運到形狀為
q
2
q_2
q2? 的土堆所需的作業量,
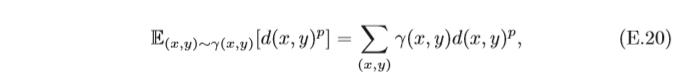
其中從土堆
q
1
q_1
q1? 中的點
x
x
x到土堆
q
2
q_2
q2? 中的點
y
y
y的移動土的數量和距離分別為
γ
(
x
,
y
)
γ(x,y)
γ(x,y) 和
d
(
x
,
y
)
p
d(x,y)^p
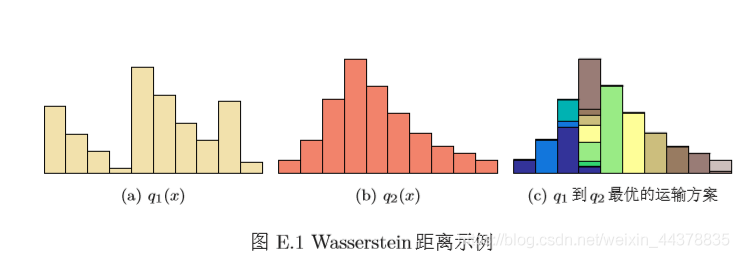
d(x,y)p,因此,Wasserstein距離可以理解為搬運土堆的最小作業量,也稱為推土機距離(Earth-Mover’s Distance,EMD),圖E.1給出了兩個離散變數分布的Wasserstein距離示例,圖E.1c中同顏色方塊表示在分布
q
1
q_1
q1? 中為相同位置,
Wasserstein距離相比KL散度和JS散度的優勢在于:即使兩個分布沒有重 疊或者重疊非常少,Wasserstein距離仍然能反映兩個分布的遠近,
對于
R
n
R^n
Rn 空間中的兩個高斯分布
p
=
N
(
μ
1
,
Σ
1
)
p = N(μ_1,Σ_1)
p=N(μ1?,Σ1?)和
q
=
N
(
μ
2
,
Σ
2
)
q = N(μ_2,Σ_2)
q=N(μ2?,Σ2?),它們的
2
n
d
?
W
a
s
s
e
r
s
t
e
i
n
2^{nd}-Wasserstein
2nd?Wasserstein距離為
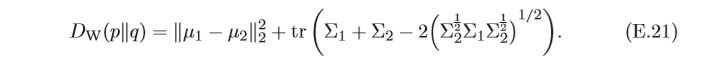
當兩個分布的的方差為0時,
2
n
d
?
W
a
s
s
e
r
s
t
e
i
n
2^{nd}-Wasserstein
2nd?Wasserstein距離等價與歐氏距離,
本文的大部分內容來自邱錫鵬教授的《神經網路與深度學習》一書,
在未來深入學習機器學習的程序中,本人會對其進行更新補充,更新資訊將發布在微信公眾號(二進制人工智能)上,

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/91009.html
標籤:AI