在了解完什么是資料結構之后,讓我們一起來探索下資料結構中常見的一種—鏈表,
鏈表
鏈表是資料結構之一,其中的資料呈線性排列,在鏈表中,資料的添加和洗掉都較為方便,就是訪問比較耗費時間,
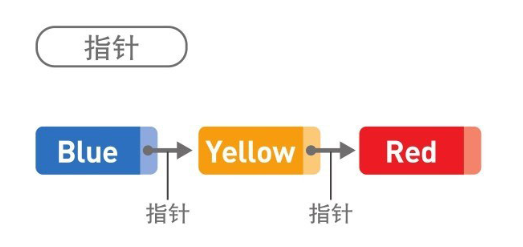
如上圖所示就是鏈表的概念圖,Blue、Yellow、Red 這 3 個字串作為資料被存盤于鏈表中,也就是資料域,每個資料都有 1 個指標,即指標域,它指向下一個資料的記憶體地址,其中 Red 是最后 1 個資料,Red 的指標不指向任何位置,也就是為 NULL,指向 NULL 的指標通常被稱為空指標,
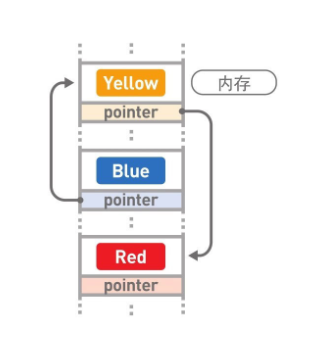
在鏈表中,資料一般都是分散存盤于記憶體中的,無須存盤在連續空間內,
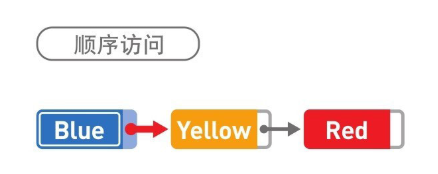
因為資料都是分散存盤的,所以如果想要訪問資料,只能從第 1 個資料開始,順著指標的指向一一往下訪問(這便是順序訪問),比如,想要找到 Red 這一資料,就得從 Blue 開始訪問,這之后,還要經過 Yellow,我們才能找到 Red,
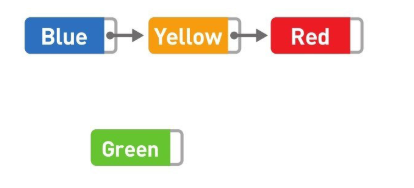
如果想要添加資料,只需要改變添加位置前后的指標指向就可以,非常簡單,比如,在 Blue 和 Yellow 之間添加 Green,
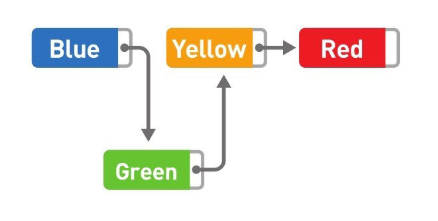
首先將 Blue 的指標指向的位置變成 Green,然后再把 Green 的指標指向 Yellow,資料的添加就大功告成了,
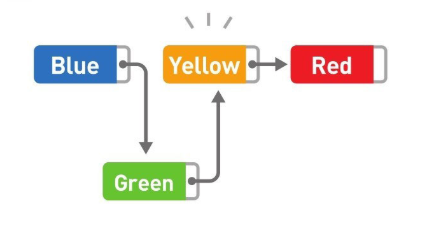
資料的洗掉也一樣,只要改變指標的指向就可以,比如洗掉 Yellow,
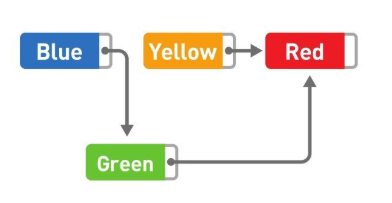
這時,只需要把 Green 指標指向的位置從 Yellow 變成 Red,洗掉就完成了,雖然 Yellow 本身還存盤在記憶體中,但是不管從哪里都無法訪問這個資料,所以也就沒有特意去洗掉它的必要了,今后需要用到 Yellow 所在的存盤空間時,只要用新資料覆寫掉就可以了,
那么對鏈表的操作所需的運行時間到底是多少呢?在這里,我們把鏈表中的資料量記成 n,訪問資料時,我們需要從鏈表頭部開始查找(線性查找),如果目標資料在鏈表最后的話,需要的時間就是 O(n),
另外,添加資料只需要更改兩個指標的指向,所以耗費的時間與 n 無關,如果已經到達了添加資料的位置,那么添加操作只需花費 O(1)的時間,洗掉資料同樣也只需 O(1)的時間,
鏈表的實作
在對鏈表有了大概的認識以后,我們用 Java 去實作屬于自己的鏈表:
public class ListNode {
int val;
ListNode next;
ListNode(int x) {
val = x;
}
}
class MyLinkedList {
int size;
/**
* 哨兵節點作為偽頭
*/
ListNode head;
public MyLinkedList() {
size = 0;
head = new ListNode(0);
}
/**
* 獲取鏈表第 index 個節點的值,如果索引是無效的,回傳-1
*
* @param index
* @return
*/
public int get(int index) {
// 若索引無效
if (index < 0 || index >= size) {
return -1;
}
ListNode curr = head;
// 從偽頭節點開始,向前走 index+1 步
for (int i = 0; i < index + 1; ++i) {
curr = curr.next;
}
return curr.val;
}
/**
* 在頭部插入節點
*
* @param val
*/
public void addAtHead(int val) {
addAtIndex(0, val);
}
/**
* 在尾部插入節點
*
* @param val
*/
public void addAtTail(int val) {
addAtIndex(size, val);
}
/**
* 在鏈表中的第 index 個節點前添加值為 val 的一個節點,如果 index 等于鏈表的長度時,節點將被添加到鏈表的末尾,如果 index 大于鏈表長度,節點將無法插入
*
* @param index
* @param val
*/
public void addAtIndex(int index, int val) {
// 如果index大于長度,則不會插入該節點,
if (index > size) {
return;
}
// 如果 index 為負,則該節點將插入串列的開頭,
if (index < 0) {
index = 0;
}
++size;
// 查找要添加的節點的前驅節點
ListNode pred = head;
for (int i = 0; i < index; ++i) {
pred = pred.next;
}
// 要添加的節點
ListNode toAdd = new ListNode(val);
// 通過改變 next 來插入節點
toAdd.next = pred.next;
pred.next = toAdd;
}
/**
* 如果 index 是有效的,洗掉鏈表中的第 index 個節點
*
* @param index
*/
public void deleteAtIndex(int index) {
// 如果 index 無效,則不執行任何操作
if (index < 0 || index >= size) {
return;
}
size--;
// 找到要洗掉節點的前驅節點
ListNode pred = head;
for (int i = 0; i < index; ++i) {
pred = pred.next;
}
// 通過改變 next 來洗掉節點
pred.next = pred.next.next;
}
}
到這里,我相信大家應該對鏈表有了進一步的理解,大家可以用不同的語言去設計實作下,
鏈表擴展
以上講述的鏈表是最基本的一種鏈表,除此之外,還存在幾種擴展方便的鏈表,
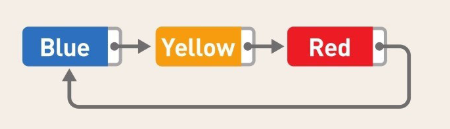
雖然上文中提到的鏈表在尾部沒有指標,但我們也可以在鏈表尾部使用指標,并且讓它指向鏈表頭部的資料,將鏈表變成環形,這便是回圈鏈表,也叫環形鏈表,回圈鏈表沒有頭和尾的概念,想要保存數量固定的最新資料時通常會使用這種鏈表,
另外,以上提到的鏈表里的每個資料都只有一個指標,但我們可以把指標設定為兩個,并且讓它們分別指向前后資料,這就是雙向鏈表,使用這種鏈表,不僅可以從前往后,還可以從后往前遍歷資料,十分方便,
但是,雙向鏈表存在兩個缺點:一是指標數的增加會導致存盤空間需求增加;二是添加和洗掉資料時需要改變更多指標的指向,

總結
看完之后,相信大家都對鏈表和鏈表的基本操作有了一定的了解,還對回圈鏈表和雙向鏈表有了初步的認識,大家可以使用自己喜歡的語言去設計實作下單向鏈表,有能力的話可以把回圈鏈表和雙向鏈表也實作下,
說完鏈表,當然不能忘記經常和鏈表同時出現在面試官口中的—陣列,將在接下來的文章對其進行展開介紹,
參考
《我的第一本演算法書》
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/91933.html
標籤:其他
上一篇:Codeforces Round #617 (Div. 3) String Coloring(E1.E2)
下一篇:什么是資料結構?