快速入門
登陸方式
作業站只允許已經授權的用戶進行登錄,在從管理員處獲得你的賬號名和初始密碼后, Linux 或 Mac 用戶可直接從命令列登錄我們的作業站,使用 ssh 命令即可
ssh username@ip_address
username為管理員給你的賬號,ip_address為遠程主機的地址
比如:ssh zhangsan@172.18.121.14對于windows用戶,可以使用PuTTY,secureCRT,mobaterm等SSH客戶端工具,就個人而言,mobaterm官網地址使用最順手,
mobaterm使用示例
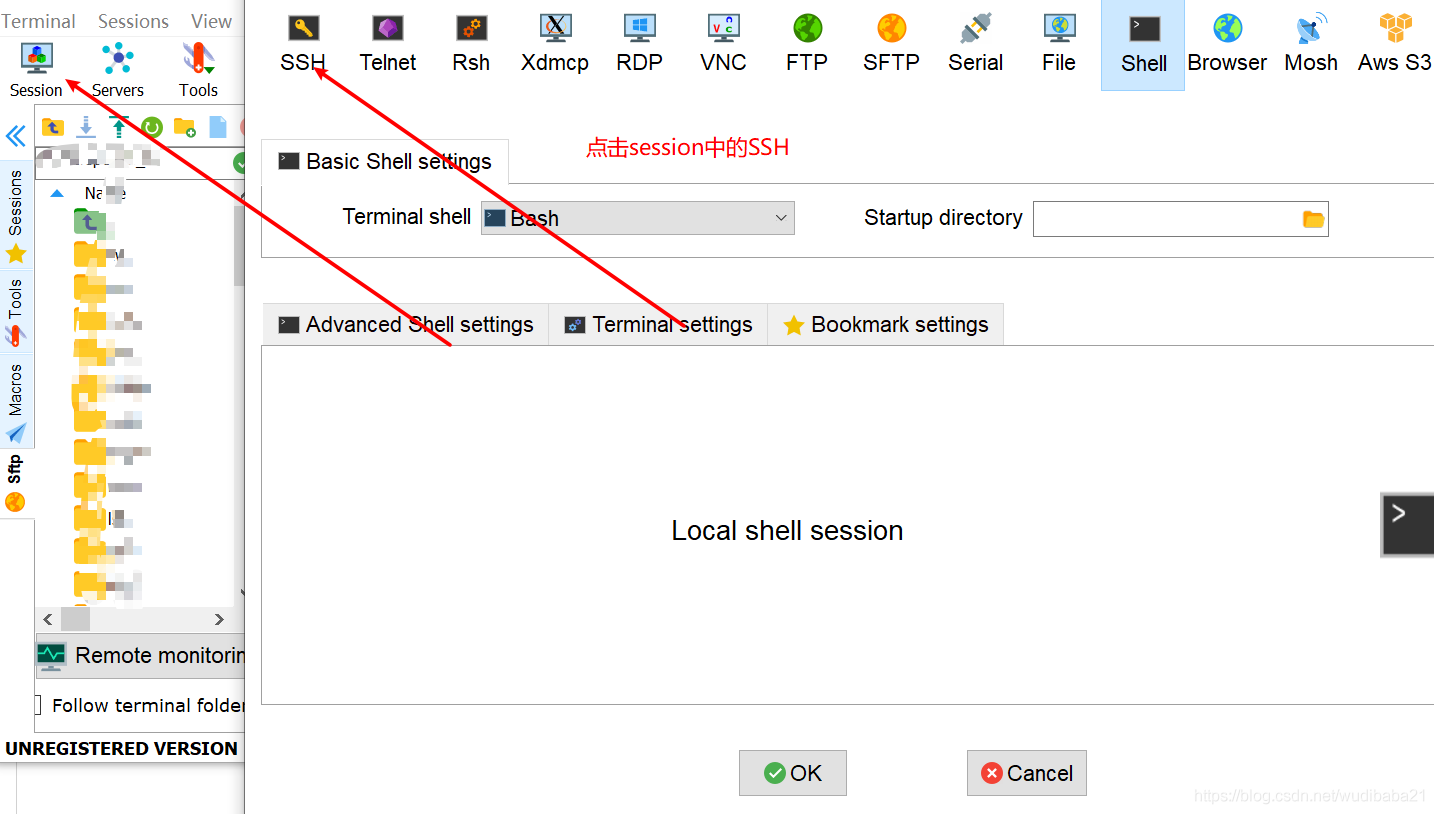
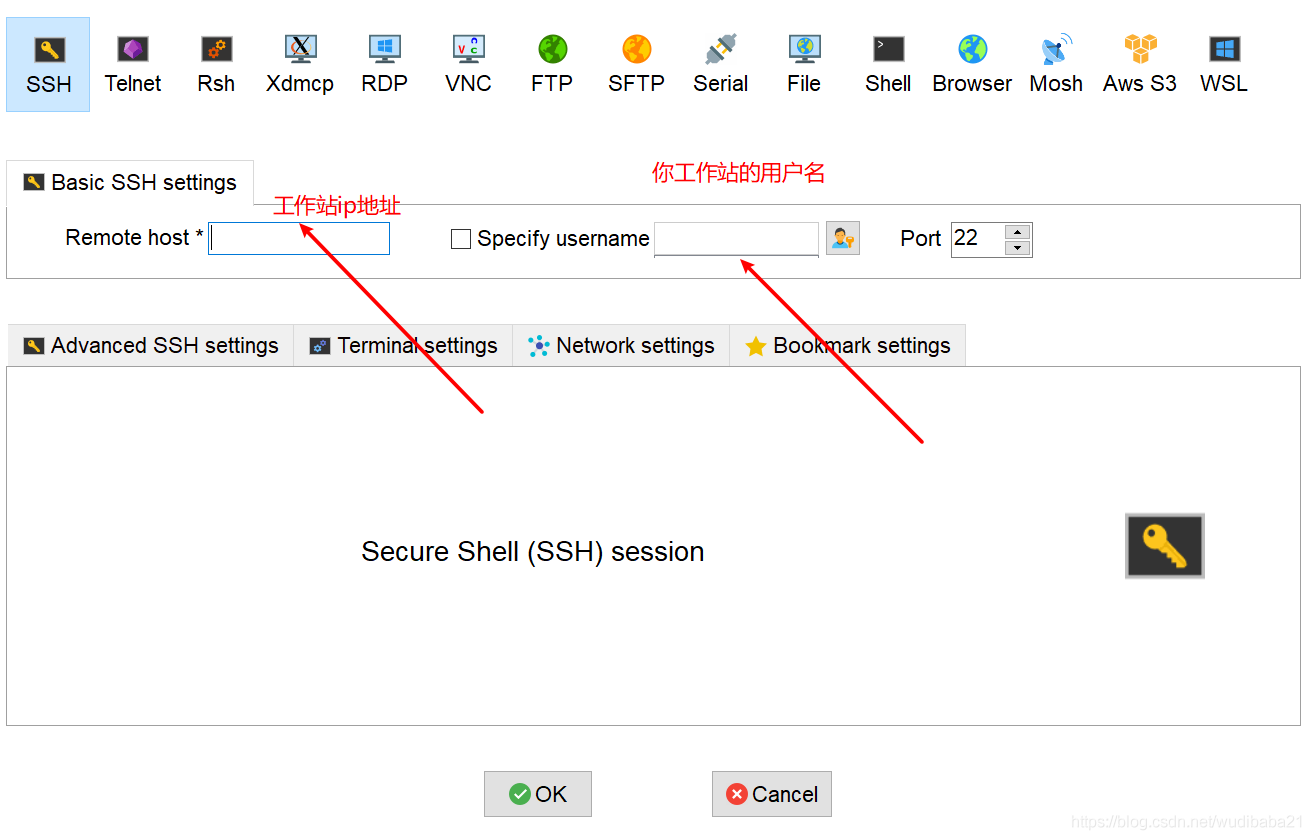
更多使用可以參考mobaterm使用
SLURM腳本---作業調度
SLURM 資源管理系統的管理物件包括:節點,磁區,作業和作業步,
-
節點:Node
- 即指計算節點
- 包含處理器、記憶體、磁盤空間等資源
- 具有空閑、分配、故障等狀態
- 使用節點名字標識
-
磁區:Partition
- 節點的邏輯分組
- 提供一種管理機制,可設定資源限制、訪問權限、優先級等
- 磁區可重疊,提供類似于佇列的功能
- 使用磁區名字標識
-
作業:Job
- 一次資源分配
- 位于一個磁區中,作業不能跨磁區
- 排隊調度后分配資源運行
- 通過作業 ID 標識
-
作業步:Jobstep
- 通過 srun 進行的任務加載
- 作業步可只使用作業中的部分節點
- 一個作業可包含多個作業步,可并發運行
- 在作業內通過作業步 ID 標識
三種模式:srun(互動模式)sbatch(批處理模式) salloc(分配模式)
名為 bcm的主機僅僅為用戶提供了登錄操作的 平臺,但程式的運行需要交給它背后的計算節點們完成,那么如何告訴作業站來運行我們的程式? 我們需要使用作業調度系統 SLURM,它給我們提供了若干運行程式的方式,在本章節 里我們簡要介紹最常用的方式:提交 SLURM 作業腳本的批處理方式
man slurm
sacct(1), sacctmgr(1), salloc(1)分配模式, sattach(1), sbatch(1)批處理模式運行, sbcast(1), scan‐
cel(1), scontrol(1), sinfo(1), smap(1), squeue(1), sreport(1), srun(1)互動模式,
sshare(1), sstat(1), strigger(1), sview(1), slurm.conf(5), slurmdbd.conf(5),
slurmctld(8), slurmd(8), slurmdbd(8), slurmstepd(8), spank(8)
上面命令舉例說明:
srun將任務分配到運行節點中
srun -n 8 -c 1 --gres=gpu:2 --pty bash
引數說明,-n 任務個數
“ --gres = gpu:2,mic:1”,“-gres = gpu:kepler:2”和“ --gres = help”, 注意:
通用資源,顯式設定--gres的值以指定零
每個通用資源的計數或設定為“ --gres = none”或設定為對應數量
-c num 使用cpu數量
--pty bash 進入該節點的終端
-w node02 進入指定節點
squeue查看全部用戶任務情況
sacct -S MMDD則會輸出從 MM 月 DD 日起的所有歷史作業
sacct -S 0916
JobID JobName Partition Account AllocCPUS State ExitCode
------------ ---------- ---------- ---------- ---------- ---------- --------
2635 bash defq users 8 FAILED 6:0
2636 bash defq users 8 COMPLETED 0:0
sinfo查看節點情況
defq* up infinite 1 drng node05
defq* up infinite 3 mix node[01,06-07]
defq* up infinite 2 idle node[02-03]
idle表示空閑,mix表示有任務在跑,但有空閑智源,drng表示無scontrol show jobs 顯示作業具體資訊
JobId=962 JobName=bash
UserId=zhangtao(1010) GroupId=zhangtao(1010) MCS_label=N/A
Priority=4294901079 Nice=0 Account=users QOS=normal
JobState=RUNNING Reason=None Dependency=(null)
Requeue=1 Restarts=0 BatchFlag=0 Reboot=0 ExitCode=0:0
RunTime=96-11:29:28 TimeLimit=UNLIMITED TimeMin=N/A
SubmitTime=2020-05-14T09:07:43 EligibleTime=2020-05-14T09:07:43
AccrueTime=Unknown
StartTime=2020-05-14T09:07:43 EndTime=Unknown Deadline=N/A
PreemptTime=None SuspendTime=None SecsPreSuspend=0
LastSchedEval=2020-05-14T09:07:43
Partition=defq AllocNode:Sid=bcm:10241
ReqNodeList=(null) ExcNodeList=(null)
NodeList=node05
BatchHost=node05
NumNodes=1 NumCPUs=8 NumTasks=8 CPUs/Task=1 ReqB:S:C:T=0:0:*:*
TRES=cpu=8,node=1,billing=8,gres/gpu=2
Socks/Node=* NtasksPerN:B:S:C=0:0:*:* CoreSpec=*
MinCPUsNode=1 MinMemoryNode=0 MinTmpDiskNode=0
Features=(null) DelayBoot=00:00:00
OverSubscribe=OK Contiguous=0 Licenses=(null) Network=(null)
Command=bash
WorkDir=/home/zhangtao/zy/CFF
Power=
TresPerNode=gpu:2總結起來,在作業站上進行運算的步驟如下:
-
登錄主節點,準備程式和資料,
-
撰寫 SLURM 腳本/進入互動模式,設定作業屬性(例如占用的資源,最長運行時間),
-
檢查可用資源,提交作業腳本,檢查任務狀態(使用 squeue 和 sinfo),
-
等待運行結束,驗收結果,
配置服務器個人運行環境
為了滿足同學們計算任務的需求,服務器中安裝了各種版本的軟體,大家可在同一軟體的不同版本之間切換,也可以在同一功能的不同軟體之間切換,以此來選擇最合適的編程環境和運行環境,使用系統命令 module 可以快速地達到這一效果,
module(可使用module就可彈出來)
Loading / Unloading commands:
add | load modulefile [...] Load modulefile(s)
rm | unload modulefile [...] Remove modulefile(s)
purge Unload all loaded modulefiles
reload | refresh Unload then load all loaded modulefiles
switch | swap [mod1] mod2 Unload mod1 and load mod2
Listing / Searching commands:
list [-t|-l] List loaded modules
avail [-d|-L] [-t|-l] [mod ...] List all or matching available modules
aliases List all module aliases
whatis [modulefile ...] Print whatis information of modulefile(s)
apropos | keyword | search str Search all name and whatis containing str
is-loaded [modulefile ...] Test if any of the modulefile(s) are loaded
is-avail modulefile [...] Is any of the modulefile(s) available
info-loaded modulefile Get full name of matching loaded module(s)
Collection of modules handling commands:
save [collection|file] Save current module list to collection
restore [collection|file] Restore module list from collection or file
saverm [collection] Remove saved collection
saveshow [collection|file] Display information about collection
savelist [-t|-l] List all saved collections
is-saved [collection ...] Test if any of the collection(s) exists
Shell's initialization files handling commands:
initlist List all modules loaded from init file
initadd modulefile [...] Add modulefile to shell init file
initrm modulefile [...] Remove modulefile from shell init file
initprepend modulefile [...] Add to beginning of list in init file
initswitch mod1 mod2 Switch mod1 with mod2 from init file
initclear Clear all modulefiles from init file
Environment direct handling commands:
prepend-path [-d c] var val [...] Prepend value to environment variable
append-path [-d c] var val [...] Append value to environment variable
module avail
blacs/openmpi/gcc/64/1.1patch03 intel-tbb-oss/ia32/2019_20191006oss
blas/gcc/64/3.8.0 intel-tbb-oss/intel64/2019_20191006oss
bonnie++/1.97.3 iozone/3_482
cm-pmix3/3.1.4 keras-py36-cuda10.1-gcc/2.3.1
cuda10.1/blas/10.1.243 lapack/gcc/64/3.8.0
cuda10.1/fft/10.1.243 ml-pythondeps-py36-cuda10.1-gcc/3.0.0
cuda10.1/nsight/10.1.243 mpich/ge/gcc/64/3.3
cuda10.1/profiler/10.1.243 mvapich2/gcc/64/2.3
cuda10.1/toolkit/10.1.243 nccl2-cuda10.1-gcc/2.4.8
cudnn/7.5.0 netcdf/gcc/64/4.6.1
default-environment netperf/2.7.0
fftw2/openmpi/gcc/64/double/2.1.5 openblas/dynamic(default)
fftw2/openmpi/gcc/64/float/2.1.5 openblas/dynamic/0.2.20
fftw3/openmpi/gcc/64/3.3.8 opencv3-py36-cuda10.1-gcc/3.4.7
gcc5/5.5.0 openmpi/cuda/64/3.1.4
gdb/8.2 openmpi/gcc/64/1.10.7
globalarrays/openmpi/gcc/64/5.7 protobuf3-gcc/3.7.1
hdf5/1.10.1 pytorch-py36-cuda10.1-gcc/1.3.0
hdf5_18/1.8.20 scalapack/openmpi/gcc/64/2.0.2
hpcx/2.4.0 sge/2011.11p1
hpl/2.2 slurm/18.08.8
hwloc/1.11.11 tensorflow-py36-cuda10.1-gcc/1.14.0
可以看出集群自帶的核心模塊數量,可以使用module add+模塊名加載或者module initadd+模塊名加載(初始化加載)
加載的模塊都在~/.bashrc中可以看到
module list查看當前加載的模塊
Currently Loaded Modulefiles:
1) slurm/18.08.8 2) cuda10.1/toolkit/10.1.243
洗掉與替換 module
如果要把某個模塊從系統環境中刪掉,需要使用
$ module remove <module name>
如果要洗掉全部的模塊,可以直接使用$ module purge
一個模塊洗掉之后,你將無法直接使用與之相關的命令,對應軟體的執行目錄無法被直接訪問,或者是還原成系統默認的版本,有的時候,模塊之間會有所沖突,你無法在同一時間同時加載兩個模塊,例如同一軟體的不同版本,或者是介面相同的不同軟體,當你載入其中一個后,再載入另一個就會出錯使用conda創建屬于你自己的虛擬環境
conda info -e查看有哪些虛擬環境
conda activate +虛擬環境名稱激活虛擬環境
創建虛擬環境并制定python版本
conda create -n your_env_name python=X.X
conda洗掉虛擬環境
conda remove -n tf2 --all
使用圖形化界面
通常情況下,在集群中我們都在命令列中操作,但是有時我們需要打開某些軟體的圖形 界面,此時我們需要借助 X11 轉發,
注意:在網路不好的時候請謹慎使用此功能,此時經過 X11 轉發的界面操作起來有 明顯卡頓,盡量在校內有線網或信號較好的無線網的環境下使用
Linux
在 Linux 環境中啟用 X11 轉發非常簡單,只需要在登錄時加入 -X 引數,
xxk@laptop: $ ssh -X user@server_ip
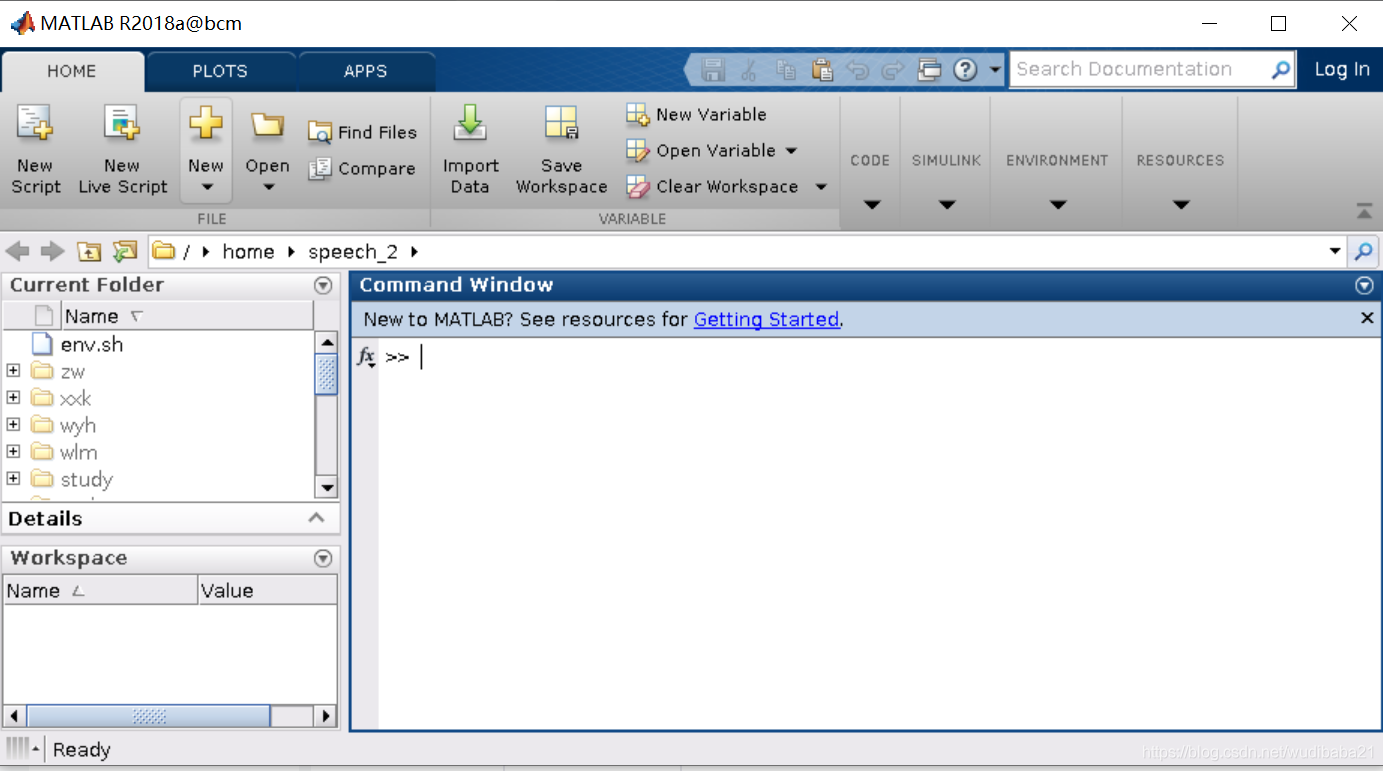
此后登錄集群可以直接輸入命令開啟圖形界面的程式,例如
matlab
MATLAB is selecting SOFTWARE OPENGL rendering.
firefox
Failed to open connection to "session" message bus: Using X11 for dbus-daemon autolaunch was disabled at compile time, set your DBUS_SESSION_BUS_ADDRESS instead
Running without a11y support!
Windows
使用 MobaXterm
推薦使用 MobaXterm 客戶端進行連接,官網地址>>
在默認情況下 MobaXterm 會自動打開 X11 的轉發,因此只需正常登錄然后直接輸入 打開軟體的命令即可
傳輸檔案
我們經常會將我們本地的一些檔案上傳到作業站上,或是從作業站下載檔案,這些作業用命令列可以輕松完成,
建議在傳輸檔案之前對要傳輸的檔案進行打包,以便有更高的傳輸效率,在 Linux 下可以使用 tar 工具進行打包,
$ tar -cjf archive.tar.bz2 folder1/ folder2/
上面的命令是將兩個檔案夾下的所有檔案打包到 archive.tar.bz2 檔案中,并進行一定壓縮,在作業站打包資料建議使用這個命令,
Windows 用戶可以使用 WinRAR 或者 Zip 進行打包,
在服務器中,相應的解包命令為
$ tar -xjf archive.tar.bz2
$ unzip archive.zip
$ unrar e archive.rar
Linux 或 Mac
使用 scp
在命令列中可以使用 scp 命令進行傳輸檔案,這是依賴于 SSH 的一個命令,如果已經配置了 SSH 無密碼 登錄那么每次復制將不必輸入密碼,否則,每次傳輸檔案都需要輸入密碼,
以下命令均在本地計算機中執行,
$ scp file username@ip_address:
$ scp file username@ip_address:Documents/
上面的第一條命令即可將 file 傳輸到作業站相應賬號的 HOME 檔案夾下,如果想要指定目錄,可以直接寫 相對于 HOME 檔案夾的路徑,例如第二條命令,
如果要使用 scp 命令復制檔案夾,需要加上 -r 引數,
$ scp -r folder username@ip_address:
從服務器傳輸檔案到本地只需將兩個引數的位置調換,
$ scp username@ip_address:file .
在這里我們使用 . 來表示本地的當前路徑,
使用 rsync
rsync 是強大的同步檔案的命令列工具,它比 scp 更加智能,rsync 支持從本地到本地, 從本地到服務器,從服務器到本地的檔案傳輸,使用 rsync 訪問服務器依賴于 SSH 的 配置,下面的例子假定用戶已經配置了 SSH 無密碼登錄,
傳輸檔案
rsync 基本的傳輸檔案命令為
# 下載檔案
rsync [OPTION...] [USER@]HOST:SRC... [DEST]
# 上傳檔案
rsync [OPTION...] SRC... [USER@]HOST:DEST
其中 SRC 表示來源的路徑,DEST 表示目標路徑,由于要訪問服務器,因此當來源或 目標不是本地時,需要指定服務器的用戶和主機名,用戶和主機名的指定可以直接使用 SSH 的 .ssh/config 表示的格式,
因此上傳可用
# 假設已經配好了 SSH config,server 表示的主機有意義
rsync -avz folder server:
# 如果沒有配置 SSH config
rsync -avz folder user@server_ip:
其中的三個選項,a 表示歸檔模式,在這個模式下傳輸將遞回地進行,并保留檔案的 權限資訊;v 表示將中間資訊輸出;z 表示在傳輸程序中進行壓縮來減少傳輸量, 下載只需要將 SRC 和 DEST 的地位對換,
rsync 的優勢在于,每次在傳輸之前會對檔案進行比較,只會傳輸那些真正改變的檔案, 在多數情況下會極大減小傳輸量,下面是一個例子,
[liuhy@laptop ~]$ ls test/
total 0 # test 檔案夾只有三個檔案
-rw-rw-r--. 1 liuhy liuhy 0 Jul 1 15:25 1.txt
-rw-rw-r--. 1 liuhy liuhy 0 Jul 1 15:25 2.txt
-rw-rw-r--. 1 liuhy liuhy 0 Jul 1 15:25 3.txt
# 使用 rsync 上傳
[liuhy@laptop ~]$ rsync -avz test server:
sending incremental file list
test/
test/1.txt
test/2.txt
test/3.txt
sent 213 bytes received 80 bytes 195.33 bytes/sec
total size is 0 speedup is 0.00
# 創建新檔案 4.txt
[liuhy@laptop ~]$ echo "hello world" >> test/4.txt
[liuhy@laptop ~]$ rsync -avz test server:
sending incremental file list
test/
test/4.txt # <- 只上傳了這一個檔案!
sent 184 bytes received 42 bytes 150.67 bytes/sec
total size is 12 speedup is 0.05
同步時洗掉
使用 rsync 上傳檔案時,如果 SRC 的檔案比 DEST 的檔案要少時,rsync 默認不會去 處理 DEST 多出來的檔案,如果要實作真的的完全同步,即洗掉 DEST 多出來的檔案,需要 給 rsync 加上 --delete 選項,
接著上面的例子,在本地洗掉 1.txt,并告訴服務器也要洗掉這個檔案
[liuhy@laptop ~]$ rm test/1.txt # 洗掉 1.txt
[liuhy@laptop ~]$ rsync -avz --delete test server:
sending incremental file list
test/
deleting test/1.txt # <- 在做洗掉操作!
sent 113 bytes received 37 bytes 100.00 bytes/sec
total size is 12 speedup is 0.08
斷點續傳
rsync 的同步演算法只能針對整個的檔案,默認情況下,如果檔案傳輸不完整,rsync 會 扔掉這些檔案,在下次傳輸的時候重新處理,當要傳輸單個大檔案時,由于網路等多方面 原因,傳輸很難一次完成,這時候就需要斷點續傳功能,
# 使用 rsync 指定 --partial 選項來保留傳輸未完成的檔案
[liuhy@laptop Downloads]$ rsync -avz --partial --progress gcc-7.3.0.tar.xz server:
sending incremental file list
gcc-7.3.0.tar.xz
36,208,640 57% 11.43MB/s 0:00:02 ^CKilled by signal 2.
# ^ 使用 Ctrl+C 強制終止
rsync error: unexplained error (code 255) at rsync.c(638) [sender=3.1.2]
# 指定 --append 選項來傳輸未完成的檔案
[liuhy@laptop Downloads]$ rsync -avz --append --progress gcc-7.3.0.tar.xz server:
sending incremental file list
gcc-7.3.0.tar.xz
62,462,388 100% 11.71MB/s 0:00:02 (xfr#1, to-chk=0/1)
sent 26,481,503 bytes received 34 bytes 7,566,153.43 bytes/sec
total size is 62,462,388 speedup is 2.36
# ^ 注意這是從 57% 開始傳的,sent 和 total size 不一樣,
將作業站目錄掛載到本地
如果不想使用 scp 命令,可以利用 sshfs 將服務器的 HOME 目錄掛載到本地,這并不會消耗你本地的存盤空間,
首先,使用如下命令安裝 sshfs 應用
$ sudo apt install sshfs
其中 apt 是 ubuntu/debian 的安裝包管理器,如果你在使用其它 Linux 發行版,請使用相應的安裝包管理器進行安裝,
安裝完畢后,在你喜歡的本地目錄下建立掛載點,為了方便,可以選擇個人的本地 HOME 檔案夾,
$ mkdir workstation
其中 workstation 為掛載點的名稱,可以隨意填寫,
最后,將服務器端的 HOME 檔案夾掛載到本地
$ sshfs username@ip_address: workstation
其中 username 為你用戶名,ip_address為服務器的地址,上面命令的最后一個 workstation 表示將服務器檔案夾掛載到剛創建的掛載點 workstation 上,使用時請將其替換成你實際創建掛載點的路徑,
掛載成功后,你可以從掛載點處(在本說明中為本地 HOME 檔案夾下的 workstation 目錄)直接訪問你的服務器遠端的目錄,非常方便,
當你不需要使用服務器檔案時,需要將服務器掛載目錄卸載,命令為
$ fusermount -u workstation
其中 workstation 為你事先創建好的掛載點,卸載前請確保本地沒有程式在使用遠程目錄下的檔案,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/92128.html
標籤:其他
下一篇:Mysql-安裝與配置glibc