引言
在 T C P / I P 協議族中,鏈路層主要有三個目的:(1)為 I P 模塊發送和
接收 I P 資料報;(2)為 A R P 模塊發送 A R P 請求和接收 A R P 應答;(3)為 R A R P 發送 R A R P 請
求和接收 R A R P 應答,T C P / I P 支持多種不同的鏈路層協議,這取決于網路所使用的硬體,如以
太網、令牌環網、F D D I(光纖分布式資料介面)及 R S-2 3 2 串行線路等,
我們將詳細討論以太網鏈路層協議,兩個串行介面鏈路層協議( S L I P 和 P P P),
以及大多數實作都包含的環回( l o o p b a c k)驅動程式,以太網和 S L I P 是本書中大多數例子使
用的鏈路層,對 M T U(最大傳輸單元)進行了介紹,這個概念在本書的后面章節中將多次遇
到,
以太網和 IEEE 802 封裝
以太網這個術語一般是指數字設備公司( Digital Equipment Corp.)、英特爾公司(I n t e l
C o r p .)和 X e r o x 公司在 1 9 8 2 年聯合公布的一個標準,它是當今 T C P / I P 采用的主要的局域網技
術,它采用一種稱作 C S M A / C D 的媒體接入方法,其意思是帶沖突檢測的載波偵聽多路接入
(Carrier Sense, Multiple Access with Collision Detection),它的速率為 10 Mb/s,地址為 48 bit,
幾年后,I E E E(電子電氣工程師協會) 8 0 2 委員會公布了一個稍有不同的標準集,其中
8 0 2 . 3 針對整個 C S M A / C D 網路,8 0 2 . 4 針對令牌總線網路,8 0 2 . 5 針對令牌環網路,這三者的共
同特性由 8 0 2 . 2 標準來定義,那就是 8 0 2 網路共有的邏輯鏈路控制( L L C),不幸的是,8 0 2 . 2 和
8 0 2 . 3 定義了一個與以太網不同的幀格式,文獻 [Stallings 1987]對所有的 IEEE 802 標準進行了
詳細的介紹,
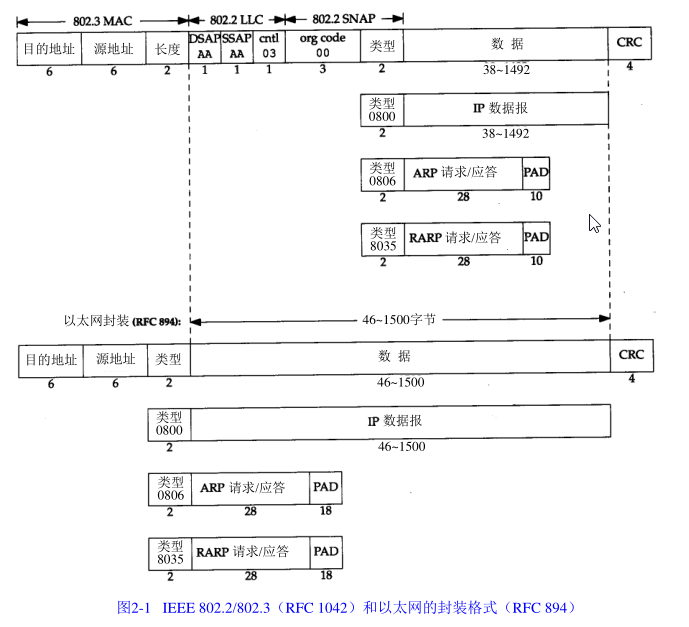
在以太網幀格式中,型別欄位之后就是資料;而在 8 0 2 幀格式中,跟隨在后面的是 3 位元組
的 802.2 LLC 和 5 位元組的 802.2 SNAP,目的服務訪問點( Destination Service Access Point,
D S A P)和源服務訪問點(Source Service Access Point, SSAP)的值都設為 0 x a a,Ct r l 欄位的
值設為 3,隨后的 3 個位元組 o rg code 都置為 0,再接下來的 2 個位元組型別欄位和以太網幀格式一樣
(其他型別欄位值可以參見 RFC 1340 [Reynolds and Postel 1992]),
C R C 欄位用于幀內后續位元組差錯的回圈冗余碼檢驗(檢驗和)(它也被稱為 F C S 或幀檢驗
序列),
8 0 2 . 3 標準定義的幀和以太網的幀都有最小長度要求, 8 0 2 . 3 規定資料部分必須至少為 3 8 字
節,而對于以太網,則要求最少要有 4 6 位元組,為了保證這一點,必須在不足的空間插入填充
(p a d)位元組,在開始觀察線路上的分組時將遇到這種最小長度的情況
尾部封裝
RFC 893[Leffler and Karels 1984]描述了另一種用于以太網的封裝格式,稱作尾部封裝
(trailer encapsulation),這是一個早期 B S D 系統在 DEC VA X 機上運行時的試驗格式,它通過
調整 I P 資料報中欄位的次序來提高性能,在以太網資料幀中,開始的那部分是變長的欄位
(I P 首部和 T C P 首部),把它們移到尾部(在 C R C 之前),這樣當把資料復制到內核時,就可以
把資料幀中的資料部分映射到一個硬體頁面,節省記憶體到記憶體的復制程序, T C P 資料報的長
度是 5 1 2 位元組的整數倍,正好可以用內核中的頁表來處理,兩臺主機通過協商使用 A R P 擴展協
議對資料幀進行尾部封裝,這些資料幀需定義不同的以太網幀型別值,
現在,尾部封裝已遭到反對,因此我們不對它舉任何例子,有興趣的讀者請參閱 RFC 893
以及文獻[ L e ffler et al. 1989]的 11 . 8 節,
SLIP:串行線路 IP
S L I P 的全稱是 Serial Line IP,它是一種在串行線路上對 I P 資料報進行封裝的簡單形式,在
RFC 1055[Romkey 1988]中有詳細描述,S L I P 適用于家庭中每臺計算機幾乎都有的 R S - 2 3 2 串
行埠和高速調制解調器接入 I n t e r n e t,
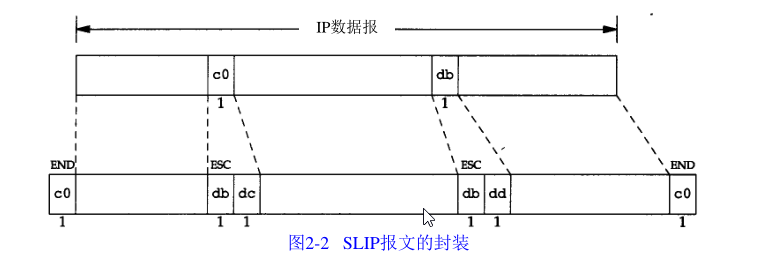
下面的規則描述了 S L I P 協議定義的幀格式:
- IP 資料報以一個稱作 E N D(0 x c 0)的特殊字符結束,同時,為了防止資料報到來之前
的線路噪聲被當成資料報內容,大多數實作在資料報的開始處也傳一個 E N D 字符(如果有線
路噪聲,那么 E N D 字符將結束這份錯誤的報文,這樣當前的報文得以正確地傳輸,而前一個
錯誤報文交給上層后,會發現其內容毫無意義而被丟棄), - 如果 I P 報文中某個字符為 E N D,那么就要連續傳輸兩個位元組 0 x d b 和 0 x d c 來取代它,
0 x d b 這個特殊字符被稱作 S L I P 的 E S C 字符,但是它的值與 A S C I I 碼的 E S C 字符(0 x 1 b)不同, - 如果 I P 報文中某個字符為 S L I P 的 E S C 字符,那么就要連續傳輸兩個位元組 0 x d b 和 0 x d d 來
取代它,
圖 2 - 2 中的例子就是含有一個 E N D 字符和一個 E S C 字符的 I P 報文,在這個例子中,在串行
線路上傳輸的總位元組數是原 I P 報文長度再加 4 個位元組,
S L I P 的歷史要追溯到 1 9 8 4 年,Rick Adams 第一次在 4 . 2 B S D 系統中實作,盡管它本
身的描述是一種非標準的協議,但是隨著調制解調器的速率和可靠性的提高, S L I P 越
來越流行,現在,它的許多產品可以公開獲得,而且很多廠家都支持這種協議
壓縮的 SLIP
由于串行線路的速率通常較低( 19200 b/s 或更低),而且通信經常是互動式的(如 Te l n e t
和 R l o g i n,二者都使用 T C P),因此在 S L I P 線路上有許多小的 T C P 分組進行交換,為了傳送 1 個
位元組的資料需要 2 0 個位元組的 I P 首部和 2 0 個位元組的 T C P 首部,總數超過 4 0 個位元組
既然承認這些性能上的缺陷,于是人們提出一個被稱作 C S L I P(即壓縮 S L I P)的新協議,
它在 RFC 1144[Jacobson 1990a]中被詳細描述,C S L I P 一般能把上面的 4 0 個位元組壓縮到 3 或 5 個
位元組,它能在 C S L I P 的每一端維持多達 1 6 個 T C P 連接,并且知道其中每個連接的首部中的某些
欄位一般不會發生變化,對于那些發生變化的欄位,大多數只是一些小的數字和的改變,這
些被壓縮的首部大大地縮短了互動回應時間,
現在大多數的 S L I P 產品都支持 C S L I P,作者所在的子網(參見封面內頁)中有兩條
SLIP 鏈路,它們均是 CSLIP 鏈路,
PPP:點對點協議
P P P,點對點協議修改了 S L I P 協議中的所有缺陷,P P P 包括以下三個部分:
- 在串行鏈路上封裝 I P 資料報的方法, P P P 既支持資料為 8 位和無奇偶檢驗的異步模式
(如大多數計算機上都普遍存在的串行介面),還支持面向位元的同步鏈接, - 建立、配置及測驗資料鏈路的鏈路控制協議( L C P:Link Control Protocol),它允許通
信雙方進行協商,以確定不同的選項, - 針對不同網路層協議的網路控制協議( N C P:Network Control Protocol)體系,當前
R F C 定義的網路層有 I P、O S I 網路層、D E C n e t 以及 A p p l e Ta l k,例如,IP NCP 允許雙方商定是
否對報文首部進行壓縮,類似于 C S L I P(縮寫詞 N C P 也可用在 T C P 的前面),
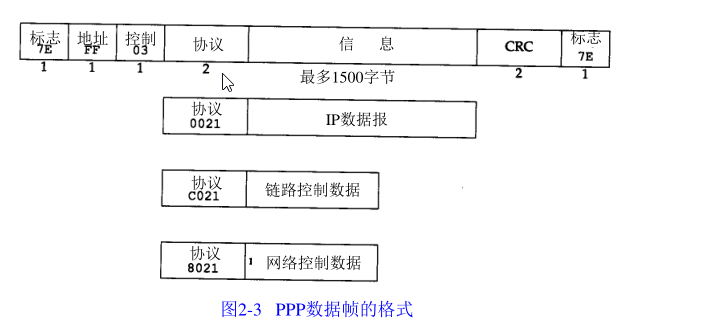
P P P 比 S L I P 具有下面這些優點:(1) PPP 支持在單根串行線路上運行多種協議,
不只是 I P 協議;(2) 每一幀都有回圈冗余檢驗; (3) 通信雙方可以進行 I P 地址的動態協商(使用
I P 網路控制協議);(4) 與 C S L I P 類似,對 T C P 和 I P 報文首部進行壓縮; (5) 鏈路控制協議可以
對多個資料鏈路選項進行設定,為這些優點付出的代價是在每一幀的首部增加 3 個位元組,當建
立鏈路時要發送幾幀協商資料,以及更為復雜的實作,
盡管 P P P 比 S L I P 有更多的優點,但是現在的 S L I P 用戶仍然比 P P P 用戶多,隨著產品
越來越多,產家也開始逐漸支持 PPP,因此最終 PPP 應該取代 SLIP
環回介面
大多數的產品都支持環回介面( Loopback Interface),以允許運行在同一臺主機上的客戶
程式和服務器程式通過 T C P / I P 進行通信,A 類網路號 1 2 7 就是為環回介面預留的,根據慣例,
大多數系統把 I P 地址 1 2 7 . 0 . 0 . 1 分配給這個介面,并命名為 l o c a l h o s t,一個傳給環回介面的 I P 數
據報不能在任何網路上出現
我們想象,一旦傳輸層檢測到目的端地址是環回地址時,應該可以省略部分傳輸層和所
有網路層的邏輯操作,但是大多數的產品還是照樣完成傳輸層和網路層的所有程序,只是當
I P 資料報離開網路層時把它回傳給自己,
圖 2 - 4 是環回介面處理 I P 資料報的簡單程序
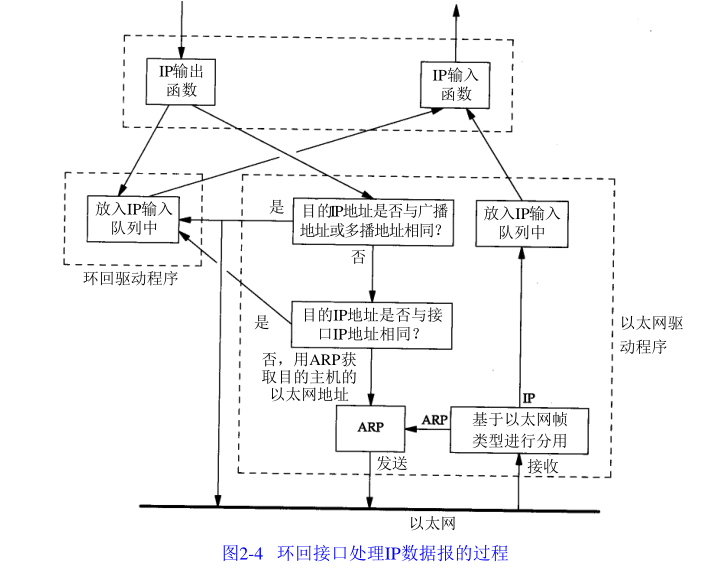
圖中需要指出的關鍵點是:
- 傳給環回地址(一般是 1 2 7 . 0 . 0 . 1)的任何資料均作為 I P 輸入,
- 傳給廣播地址或多播地址的資料報復制一份傳給環回介面,然后送到以太網上,這是
因為廣播傳送和多播傳送的定義(第 1 2 章)包含主機本身,
3 ) 任何傳給該主機 I P 地址的資料均送到環回介面,
看上去用傳輸層和 I P 層的方法來處理環回資料似乎效率不高,但它簡化了設計,因為環
回介面可以被看作是網路層下面的另一個鏈路層,網路層把一份資料報傳送給環回介面,就
像傳給其他鏈路層一樣,只不過環回介面把它回傳到 I P 的輸入佇列中,
最大傳輸單元 MTU

路徑 MTU
當在同一個網路上的兩臺主機互相進行通信時,該網路的 M T U 是非常重要的,但是如果
兩臺主機之間的通信要通過多個網路,那么每個網路的鏈路層就可能有不同的 M T U,重要的
不是兩臺主機所在網路的 M T U 的值,重要的是兩臺通信主機路徑中的最小 M T U,它被稱作路
徑 M T U,
串行線路吞吐量計算
如果線路速率是 9600 b/s,而一個位元組有 8 bit,加上一個起始位元和一個停止位元,那么
線路的速率就是 960 B/s(位元組/秒),以這個速率傳輸一個 1 0 2 4 位元組的分組需要 1066 ms,如果
用 S L I P 鏈接運行一個互動式應用程式,同時還運行另一個應用程式如 F T P 發送或接收 1 0 2 4 字
節的資料,那么一般來說就必須等待一半的時間( 533 ms)才能把互動式應用程式的分組數
據發送出去,
假定互動分組資料可以在其他“大塊”分組資料發送之前被發送出去,大多數的 S L I P 實
現確實提供這類服務排隊方法,把互動資料放在大塊的資料前面,互動通信一般有 Te l n e t、
R l o g i n 以及 F T P 的控制部分(用戶的命令,而不是資料),
這種服務排隊方法是不完善的,它不能影響已經進入下游(如串行驅動程式)隊
列的非互動資料,同時,新型的調制解調器具有很大的緩沖區,因此非互動資料可能
已經進入該緩沖區了,
對于互動應用來說,等待 533 ms 是不能接受的,關于人的有關研究表明,互動回應時間
超過 1 0 0 ~ 200 ms 就被認為是不好的 [Jacobson 1990a],這是發送一份互動報文出去后,直到
接收到回應資訊(通常是出現一個回顯字符)為止的往返時間,
不幸的是,當使用新型的糾錯和壓縮調制解調器時,這樣的計算就更難了,這些調制解
調器所采用的壓縮方法使得在線路上傳輸的位元組數大大減少,但糾錯機制又會增加傳輸的時
間,不過,這些計算是我們進行合理決策的入口點,
小結
這討論了 I n t e r n e t 協議族中的最底層協議,鏈路層協議,我們比較了以太網和 I E E E
8 0 2 . 2 / 8 0 2 . 3 的封裝格式,以及 S L I P 和 P P P 的封裝格式,由于 S L I P 和 P P P 經常用于低速的鏈路,
二者都提供了壓縮不常變化的公共欄位的方法,這使互動性能得到提高,
大多數的實作都提供環回介面,訪問這個介面可以通過特殊的環回地址,一般為
1 2 7 . 0 . 0 . 1,也可以通過發送 I P 資料報給主機所擁有的任一 I P 地址,當環回資料回到上層的協議
堆疊中時,它已經過傳輸層和 I P 層完整的處理程序,
我們描述了很多鏈路都具有的一個重要特性, M T U,相關的一個概念是路徑 M T U,根據
典型的串行線路 M T U,對 S L I P 和 C S L I P 鏈路的傳輸時延進行了計算,
這的內容只覆寫了當今 T C P / I P 所采用的部分資料鏈路公共技術, T C P / I P 成功的原因之
一是它幾乎能在任何資料鏈路技術上運行,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/93544.html
標籤:其他