求助大佬,為什么我爬取的網頁原始碼是這個樣子????
uj5u.com熱心網友回復:
什么問題?是想說為什么會出現 &#xxxxx 的這些東西嗎?&#開頭后面加上編碼是 css-font的表示形式,是網頁里面設定的圖示,字體反爬也是長這樣的uj5u.com熱心網友回復:
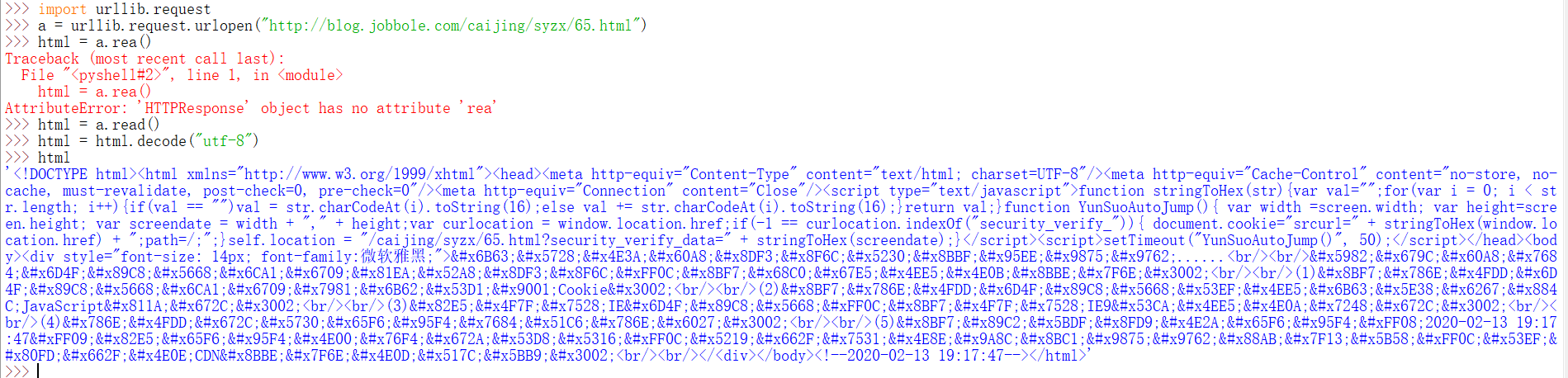
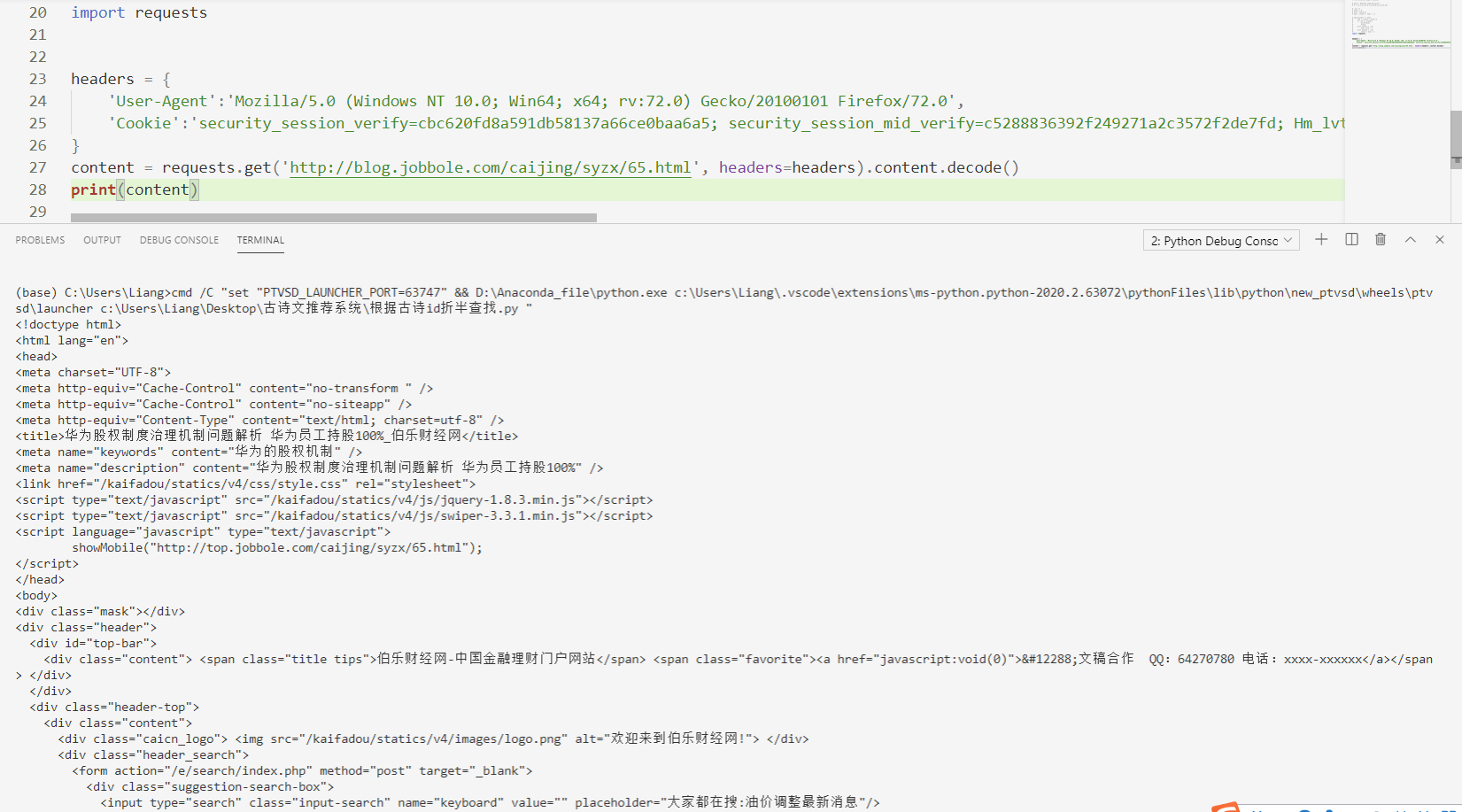
我用scrapy的xpath去爬一篇博文的標題,試了好幾種方法,發現爬出來的是一個空的串列,然后我用response.body然后輸出的就是這一串代碼,和這個是一樣的,但是我看的視頻資料應該回傳的是網頁原始碼啊。
uj5u.com熱心網友回復:
網頁原始碼 指的是 字串,類似于<html>xxx <body>xxx</body> xxx</html>
你上面截圖的,就是 網頁原始碼。
你說的 視頻中的網頁原始碼 指的是哪樣的??
uj5u.com熱心網友回復:
你好,這個問題我已經解決了,你可以看一下你給的截圖回傳的代碼,是一段驗證 cookie 的 JavaScript代碼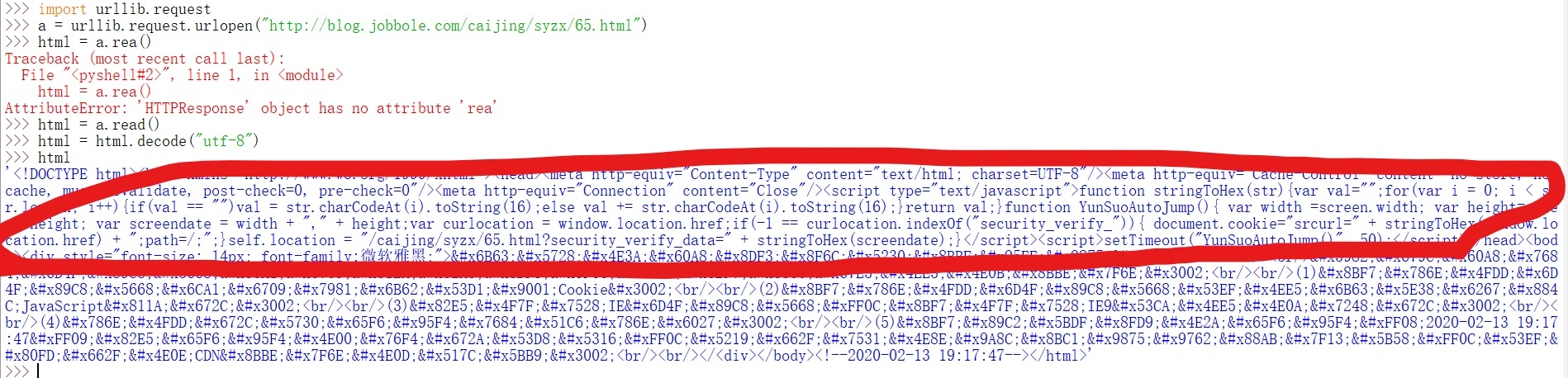
放到編譯器里 format 看一下
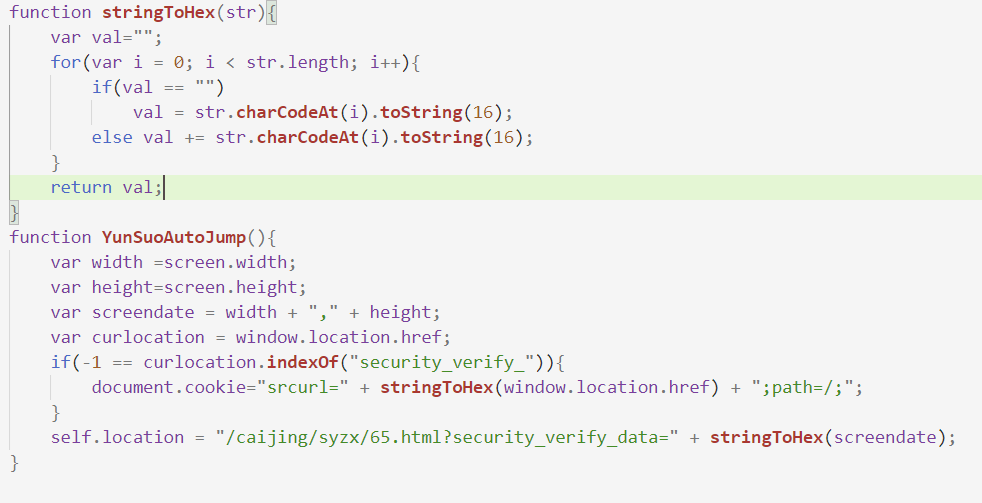
它是在url上攜帶了引數資訊,然后網站進行了安全驗證,你只需要抓包,把 cookie 帶上即可
這是我用火狐抓的包,找到里面的cookie
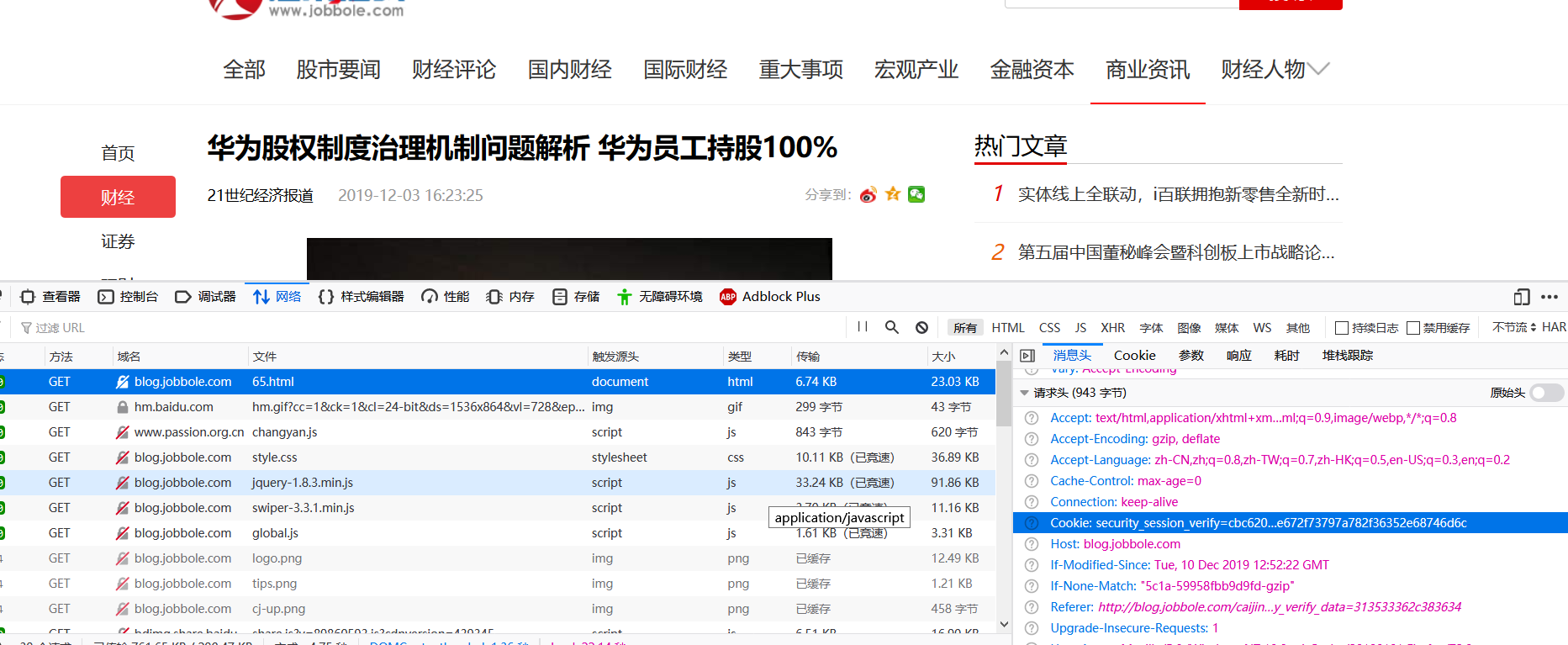
request的時候帶上cookie進行認證就可以了
uj5u.com熱心網友回復:
補充一下,對于這種網頁的話,你請求的時候攜帶的 cookie 的引數是得變化的,具體攜帶的密匙怎么變,就得執行里面生成密匙的 js 代碼,python有一個叫 execjs 的庫,前提是你要會操作 js 代碼,利用它給的生成密匙的字串,放到execjs里面進行編譯,根據不同的 url 生成不同的密匙,修改 cookie 對應的值,請求的時候帶上 cookie 即可解決uj5u.com熱心網友回復:
謝謝大佬 我知道啥原因了
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/93739.html
上一篇:Python bs4安裝問題
下一篇:求教怎樣打開R-3.5.0