動態規劃(下)
- Ⅰ 前言
- Ⅱ 字串相似度的量化
- Ⅲ 萊文斯坦距離的計算
- Ⅳ 最長公共子串長度的計算
- Ⅴ 如何實作搜索引擎的拼寫糾錯
Ⅰ 前言
如果對動態規劃的基礎內容還有不了解的同學,可以跳轉去看我下面的文章👇
【資料結構與演算法】->演算法->動態規劃(上)->初識動態規劃->怎么精準地幫助女朋友薅羊毛
【資料結構與演算法】->演算法->動態規劃(中)->詳解動態規劃理論
在我前面的一篇文章 Trie 樹 中我提到了搜索引擎的一個功能,關鍵詞提示,除此之外,一般搜索引擎為了優化用戶的體驗,還有個拼寫糾錯的功能,
當你在搜索框中,不小心輸入錯單詞時,搜索引擎就會非常智能地檢測出你的拼寫錯誤,并且用對應的正確單詞來進行搜索,那么,這個功能是如何實作的呢?

Ⅱ 字串相似度的量化
要實作拼寫糾錯功能,首先要能識別兩個字串,但是計算機只認識數字,兩個字串之間的相似度要如何量化呢?有一個非常著名的量化方法,那就是 編輯距離(Edit Distance),
顧名思義,編輯距離指 的就是,將一個字串轉化成另一個字串,需要的最少編輯操作次數(比如增加一個字符,洗掉一個字符,替換一個字符),編輯距離越大,說明兩個字串的相似程度越小;相反,編輯距離越小,說明兩個字串的相似程度越大,對于兩個完全相同的字串來說,編輯距離就是 0,
根據所包含的編輯操作種類的不同,編輯距離有多種不同的計算方式,比較著名的有 萊文斯坦距離(Levenshtein distance) 和 最長公共子串長度(Longest common substring length),其中,萊溫斯坦距離允許增加、洗掉、替換字符這三種編輯操作,最長公共子串長度只允許增加、洗掉字符這兩個編輯操作,
而且,萊文斯坦距離和最長公共子串,是從兩個相反的角度來分析字串的相似程度,萊文斯坦距離的大小,表示兩個字串差異的大小;最長公共子串的大小,表示兩個字串相似程度的大小,
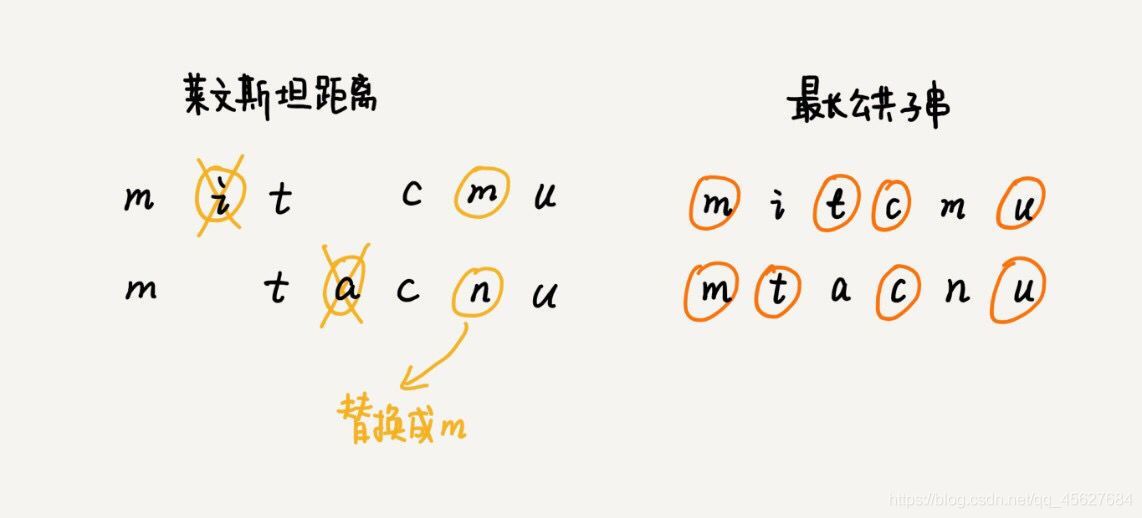
關于這兩個計算方法,我舉個例子來說明,下圖中兩個字串,mitcum 和 mtacnu 的萊文斯坦距離是 3,最長公共子串長度是 4,
了解了編輯距離的概念之后,我們來看,如何快速計算兩個字串之間的編輯距離,
Ⅲ 萊文斯坦距離的計算
這個問題是求把一個字串變成另一個字串,需要的最少編輯次數,整個求解程序涉及到多個決策階段,我們需要依次考察一個字串中的每個字符,跟另一個字串中的字符是否匹配,匹配的話如何處理,不匹配的話又如何處理,所以,這個問題符合多階決策最優模型,
在上一篇文章中的總結里,我們說貪心、回溯、動態規劃可以解決的問題,都可以抽象成這樣一個模型,要解決這個問題,我們可以先用最簡單的回溯演算法試試,
回溯是一個遞回處理的程序,如果 a[i] 與 b[j] 匹配,我們遞回考察 a[i+1] 和 b[j+1],如果 a[i] 與 b[j] 不匹配,那我們有很多種處理方式可選:
- 可以洗掉 a[i],然后遞回考察 a[i+1] 和 b[j];
- 可以洗掉 b[j],然后遞回考察 a[i] 和 b[j+1];
- 可以在 a[i] 前面添加一個跟 b[j] 相同的字符,然后遞回考察 a[i] 和 b[j+1];
- 可以在 b[j] 前面添加一個跟 a[i] 相同的字符,然后遞回考察 a[i+1] 和 b[j];
- 可以將 a[i] 替換成 b[j],或者將 b[j] 替換成 a[i],然后遞回考察 a[i+1] 和 b[j+1];
我們用Java實作就是下面這樣👇
package com.tyz.third.core;
/**
* 萊文斯坦距離的計算
* @author Tong
*/
public class LevenshteinDistance {
private char[] strOne = "mitcmu".toCharArray();
private char[] strTwo = "mtacnu".toCharArray();
private int lengthOne = strOne.length;
private int lengthTwo = strTwo.length;
private int minDist = Integer.MAX_VALUE; //存盤結果
/**
* 回溯法計算萊文斯坦距離
* @param i 第一個字串的遍歷索引
* @param j 第二個字串的遍歷索引
* @param edist 編輯次數
*/
public void lvstBT(int i, int j, int edist) {
//一個字串已經遍歷完了,另一個字串剩下的字符數就是需要編輯的次數
if (i == lengthOne || j == lengthTwo) {
if (i < lengthOne) {
edist += (lengthOne - i);
}
if (j < lengthTwo) {
edist += (lengthTwo - j);
}
if (edist < minDist) {
minDist = edist;
}
return;
}
if (strOne[i] == strTwo[j]) { //兩個字符匹配
lvstBT(i+1, j+1, edist);
} else { //兩個字符不匹配
lvstBT(i + 1, j, edist + 1); //洗掉a[i]或者b[j]前添加一個字符
lvstBT(i, j + 1, edist + 1); //洗掉b[j]或者a[i]前添加一個字符
lvstBT(i + 1, j + 1, edist + 1); //將a[i]和b[j]替換為相同字符
}
}
}
根據回溯演算法的實作,我們可以畫出遞回樹,看是否存在重復子問題,如果存在重復子問題,那我們就可以考慮用動態規劃來解決;如果不存在重復子問題,那回溯法就是最好的解決方法,
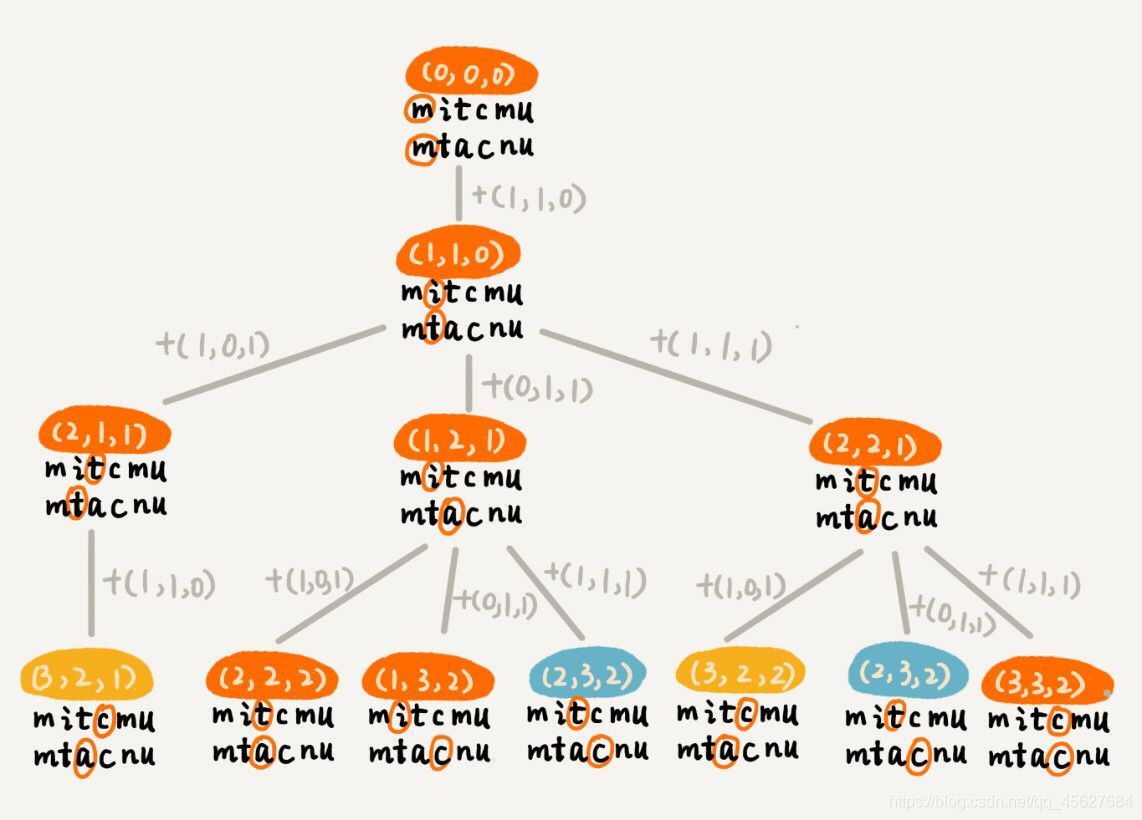
在遞回樹中,每個節點代表一個狀態,狀態包含三個變數 (i, j, edist) ,其中,edist 表示處理到 a[i] 和 b[j] 時,已經執行的編輯次數,
在遞回樹中,(i, j) 兩個變數重復的節點很多,比如 (3, 2) 和 (2, 3),對于 (i, j) 相同的節點,我們只需要保留 edist 最小的,繼續遞回處理就可以了,剩下的節點都可以舍棄,所以,狀態就從 (i, j, edist) 變成了 (i, j, min_edist),其中 min_edist 表示處理到 a[i] 和 b[j],已經執行的最少編輯次數,
到這里我們就發現了,這就是典型的動態規劃的例子啊,不過,這個問題的狀態轉移方式,要比我在動態規劃前兩篇文章里說的還要復雜,我們求二維矩陣的最短路徑,到達狀態 (i, j) 只能通過 (i-1, j) 或 (i, j-1) 兩個狀態轉移過來,但是今天這個問題,狀態可能從 (i-1, j), (i, j-1) 或 (i-1, j-1) 三個狀態中的任意一個遷移過來,

基于上面的分析,我們可以把狀態轉移的程序,用公式寫出來,

了解了狀態與狀態之間的遞推關系,我們畫出一個二維的狀態圖,按行依次填充狀態表中的每個值,
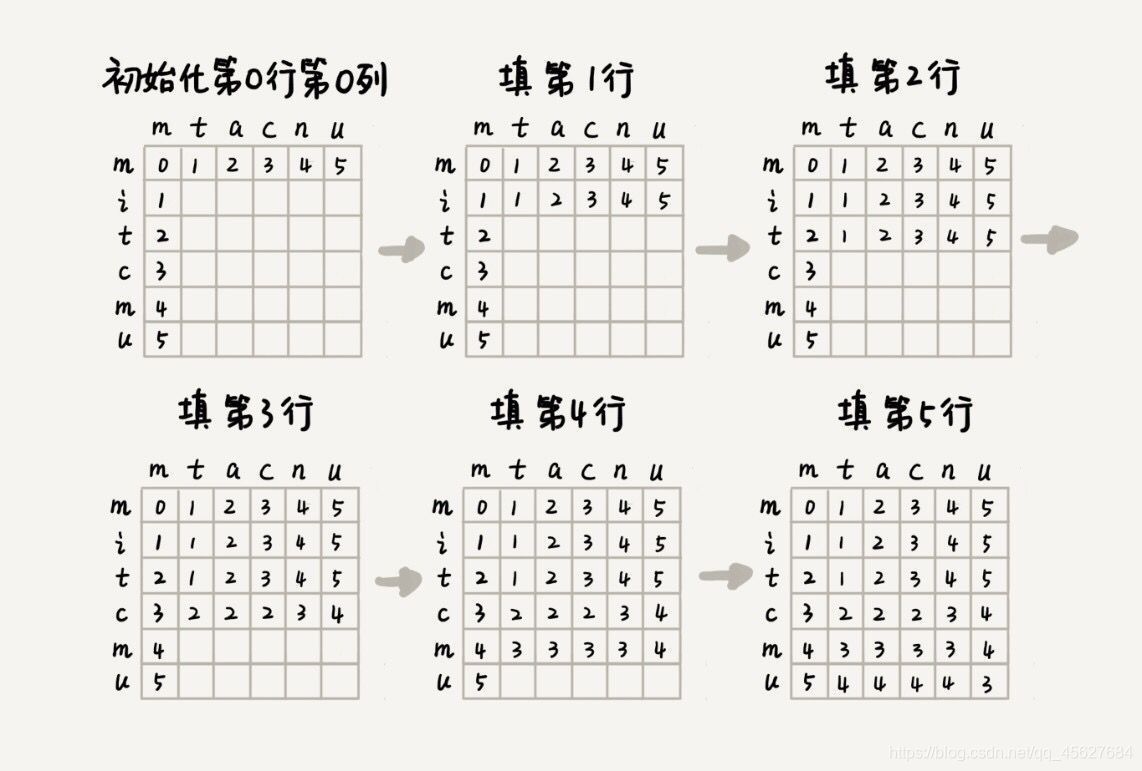
我們現在既有狀態轉移方程,又理清了完整的填表程序,代碼的實作就非常簡單了,
/**
* 動態規劃求萊文斯坦距離
* 萊文斯坦距離的計算
* 如果: a[i] != b[j], 那么: min_edist(i, j) 就等于
* min(min_edist(i-1, j)+1, min_edist(i-1, j-1)+1)
* 如果: a[i] == b[j], 那么: min_edist(i, j) 就等于
* min(min_edist(i-1, j)+1, min_edist(i-1, j-1)+1, min_edist(i-1, j-1))
* 其中, min表示求三個數中的最小值
*/
public int lvstDB(char[] strOne, int lengthOne, char[] strTwo, int lengthTwo) {
int[][] minDist = new int[lengthOne][lengthTwo];
//初始化第0列:a[0...i]到b[0...0]的編輯距離
for (int i = 0; i < lengthOne; i++) {
if (strOne[i] == strTwo[0]) {
minDist[i][0] = i; //在第一個字符匹配之前, 前面的全是不匹配的, 所以編輯距離等于i
} else if (i != 0) { //只要不是第一行的, 下一行的編輯距離就等于上一行的加1
minDist[i][0] = minDist[i-1][0] + 1;
} else {
minDist[i][0] = 1; //a(0, 0)出現不匹配,編輯距離為1
}
}
//初始化第0行:a[0...0]到b[0...j]的編輯距離
for (int j = 0; j < lengthTwo; j++) {
if (strOne[0] == strTwo[j]) {
minDist[0][j] = j;
} else if (j != 0) {
minDist[0][j] = minDist[0][j-1] + 1;
} else {
minDist[0][j] = 1;
}
}
for (int i = 1; i < lengthOne; i++) {
for (int j = 1; j < lengthTwo; j++) {
if (strOne[i] == strTwo[j]) {
minDist[i][j] = min(minDist[i-1][j]+1,
minDist[i][j-1]+1, minDist[i-1][j-1]);
} else {
minDist[i][j] = min(minDist[i-1][j]+1,
minDist[i][j-1]+1, minDist[i-1][j-1]+1);
}
}
}
return minDist[lengthOne-1][lengthTwo-1];
}
/**
* 求x,y,z中的最小值
* @param x
* @param y
* @param z
* @return
*/
private int min(int x, int y, int z) {
int minValue = Integer.MAX_VALUE;
if (x < minValue) {
minValue = x;
}
if (y < minValue) {
minValue = y;
}
if (z < minValue) {
minValue = z;
}
return minValue;
}
Ⅳ 最長公共子串長度的計算
這個問題的解決思路和萊文斯坦距離的解決思路非常相似,也可以用動態規劃解決,我們前面已經詳細描述了萊文斯坦距離的動態規劃解決思路,所以針對最長公共子串的計算,我直接定義狀態,然后寫狀態轉移方程,
每個狀態還是包括三個變數 (i, j, max_lcs),max_lcs 表示 a[0…i] 和 b[0…j] 的最長公共子串長度,那 (i, j) 這個狀態都是由哪些狀態轉移過來的呢?
我們先來看回溯的處理思路,我們從 a[0] 和 b[0] 開始,依次考察兩個字串中的字符是否匹配,注意我們前面說的,最長公共子串長度只允許增加、洗掉字符這兩個編輯操作,
- 如果 a[i] 與 b[j] 互相匹配,我們將最大公共子串長度加 1,并且繼續考察 a[i+1] 和 b[j+1],
- 如果 a[i] 與 b[j] 不匹配,最長公共子串長度不變,這時候,有兩個不同的決策路線,
- 洗掉 a[i],或者在 b[j] 前面加上一個字符 a[i],然后繼續考察 a[i+1] 和 b[j];
- 洗掉 b[j],或者在 a[i] 前面加上一個字符 b[j],然后繼續考察 a[i] 和 b[j+1],
反過來也就是說,如果我們要求 a[0…i] 和 b[0…j] 的公共長度 max_lcs(i, j),我們只有可能通過下面這個三個狀態轉移過來:
- (i-1, j-1, max_lcs),其中 max_lcs 表示 a[0…i-1] 和 b[0…j-1] 的最長公共子串長度;
- (i-1, j, max_lcs),其中 max_lcs 表示 a[0…i-1] 和 b[0…j] 的最長公共子串長度;
- (i, j-1, max_lcs),其中 max_lcs 表示 a[0…i] 和 b[0…j-1] 的最長公共子串長度;
如果我們把這個轉移程序,用狀態轉移方程寫出來,就是下面的樣子:

有了狀態轉移方程,我們將可以實作代碼了,大家可以對照著講解做一個參考,
package com.tyz.third.core;
/**
* 動態規劃計算最長公共子串長度
* 如果: a[i] == b[j], 那么: max_lcs(i, j)就等于:
* max(max_lcs(i-1, j-1)+1, max_lcs(i-1, j), max_lcs(i, j-1));
* 如果: a[i] != b[j], 那么: max_lcs(i, j)就等于:
* max(max_lcs(i-1, j-1), max_lcs(i, j-1));
* 其中max表示求三個數中的最大值
* @author Tong
*/
public class LongestCommonSubstring {
public int lcs(char[] strOne, int lengthOne, char[] strTwo, int lengthTwo) {
int[][] maxlcs = new int[lengthOne][lengthTwo];
//初始化第0行: a[0...0]與b[0...j]的maxlcs
for (int j = 0; j < lengthTwo; j++) {
if (strOne[0] == strTwo[j]) {
maxlcs[0][j] = 1;
} else if (j != 0) {
maxlcs[0][j] = maxlcs[0][j-1];
} else {
maxlcs[0][j] = 0;
}
}
//初始化第0列: a[0...i]與b[0...0]的maxlcs
for (int i = 0; i < lengthOne; i++) {
if (strOne[i] == strTwo[0]) {
maxlcs[i][0] = 1;
} else if (i != 0) {
maxlcs[i][0] = maxlcs[i-1][0];
} else {
maxlcs[i][0] = 0;
}
}
for (int i = 1; i < lengthOne; i++) {
for (int j = 1; j < lengthTwo; j++) {
if (strOne[i] == strTwo[j]) {
maxlcs[i][j] = max(maxlcs[i-1][j],
maxlcs[i][j-1], maxlcs[i-1][j-1]+1);
} else {
maxlcs[i][j] = max(maxlcs[i-1][j],
maxlcs[i][j-1], maxlcs[i-1][j-1]);
}
}
}
return maxlcs[lengthOne-1][lengthTwo-1];
}
private int max(int x, int y, int z) {
int maxValue = Integer.MIN_VALUE;
if (x > maxValue) {
maxValue = x;
}
if (y > maxValue) {
maxValue = y;
}
if (z > maxValue) {
maxValue = z;
}
return maxValue;
}
}
Ⅴ 如何實作搜索引擎的拼寫糾錯
當用戶在搜索框內,輸入一個拼寫錯誤的單詞時,我們就拿這個單詞跟詞庫里的單詞一 一進行比較,計算編輯距離,將編輯距離最小的單詞,作為糾正之后的單詞,提示給用戶,
這就是拼寫糾錯最基本的原理,不過,真正用于商用的搜索引擎,拼寫糾錯功能顯然不會就這么簡單,一方面,單純利用編輯距離來糾錯,效果并不一定好;另一方面,詞庫中的資料量可能非常大,搜索引擎每天要支持海量的搜索,所以對糾錯的性能要求很高,
針對糾錯效果不好的問題,我們有很多種優化思路,我這里介紹幾種,
- 我們并不僅僅取出編輯距離最小的那個單詞,而是取出編輯距離最小的 TOP 10,然后根據其他引數,決策選擇哪個單詞作為拼寫糾錯單詞,比如使用搜索熱門程度來決定哪個單詞作為拼寫糾錯單詞,
- 我們還可以用多種編輯距離計算方法,比如這篇文章里講的兩種,然后分別編輯距離最小的 TOP 10,然后求交集,用交集的結果,再繼續優化處理,
- 我們還可以通過統計用戶的搜索日志,得到最常被拼錯的單詞串列,以及對應的拼寫正確的單詞,搜索引擎在拼寫糾錯的時候,首先在這個最常被拼錯單詞串列中查找,如果一旦找到,直接回傳對應的正確的單詞,這樣糾錯的效果非常好,
- 我們還有更加高級一點的做法,引入個性化因素,針對每個用戶,維護這個用戶特有的搜索偏好,也就是常用的搜索詞,當用戶輸入錯誤的單詞的時候,我們首先在這個用戶常用的搜索關鍵詞中,計算編輯距離,查找編輯距離最小的單詞,
針對糾錯性能方面,我們也有相應的優化方式,我在這里講兩種分治的優化思路,
- 如果糾錯功能的 TPS 不高,我們可以部署多臺機器,每臺機器運行一個獨立的糾錯功能,當有一個糾錯請求的時候,我們通過負載均衡,分配到其中一臺機器,來計算編輯距離,得到糾錯單詞,
- 如果糾錯系統的回應時間太長,也就是,每個糾錯請求處理時間太長,我們可以將糾錯的詞庫,分配到很多臺機器,當有一個糾錯請求的時候,我們就將這個拼寫錯誤的單詞,同時發送到多臺機器,讓多臺機器并行處理,分別得到編輯距離最小的單詞,然后再對比合并,最終決定出一個最優的糾錯單詞,
真正的搜索引擎的拼寫糾錯優化,肯定不會這么簡單,但是萬變不離其宗,我們搞清楚了核心原理,就能更好地去理解它,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/94575.html
標籤:其他