本文首發于 vivo互聯網技術 微信公眾號
鏈接:https://mp.weixin.qq.com/s/7lCK9cHmunvYlbm7Xi7JxQ
作者:楊昆
一千個讀者,有一千個哈姆雷特,
此系列文章將會從函式的執行機制、魯棒性、函式式編程、設計模式等方面,全面闡述如何通過 JavaScript 撰寫高質量的函式,
一、引言
如何通過 JavaScript 撰寫高質量的函式,這是一個很難回答的問題,不同人心中對高質量有自己的看法,這里我將全面的闡述我個人對如何撰寫高質量函式的一些看法,看法可能不夠全面,也可能會有一些錯誤的見解,歡迎一起討論,就像過日子的人,小吵小鬧總會不經意的出現,一顆包容的心莫過于是最好的 best practice ,
我打算用幾篇文章來完成《如何撰寫高質量的 JS 函式》 這個系列,
主要從以下幾個方面進行闡述:
-
函式(一切皆有可能)
-
函式的命名
-
函式的注釋
-
函式的復雜度
-
函式的魯棒性(防御性編程)
-
函式的入參和出參(回傳)
-
如何用函式式編程打通函式的任督二脈
-
如何用設計模式讓函式如虎添翼
-
撰寫對 V8 友好的函式是一種什么 style
-
前端工程師的函式狂想錄
本篇只說第一節 函式 ,擒賊先擒王,下面我們來盤一盤函式的七七八八,
二、函式(一切皆有可能)
函式二字,代表著一切皆有可能,
我們想一下:我們用的函式究竟離我們有多遠,就像打麻將一樣,你覺得你能像雀神那樣,想摸啥就來啥么(夸張修辭手法),
天天和函式打交道,函式出現的目的是什么?再深入想,函式的執行機制是什么?下面我們就來簡單的分析一下,
1、函式出現的目的
函式是迄今為止發明出來的用于節約空間和提高性能的最重要的手段,
PS: 注意,沒有之一,
2、函式的執行機制
有句話說的好,知己知彼,百戰不殆,想要勝利,一定要非常的了解敵人,JS 肯定不是敵人啦,但是要想掌握 JS 的函式,要更輕松的撰寫高質量的函式,那就要掌握在 JS 中函式的執行機制,
怎么去解釋函式的執行機制呢?
先來模仿一道前端面試題:輸入一個 url 后,會發生什么?
執行一個函式,會發生什么?
參考下面代碼:
function say() {
let str = 'hello world'
console.log(str)
}這道面試題要是交給你,你能答出多少呢?
如果讓我來答,我大致會這樣說:
首先我會創建一個函式,如果你學過 C++ ,可能會說我要先開辟一個堆記憶體,
所以,我會從創建函式到執行函式以及其底層實作,這三個層次進行分析,
(1)創建函式
函式不是平白無故產生的,需要創建,創建函式時會發生什么呢?
第一步:開辟一個新的堆記憶體
每個字母都是要存盤空間的,只要有資料,就一定得有存盤資料的地方,而計算機組成原理中,堆允許程式在運行時動態地申請某個大小的記憶體空間,所以你可以在程式運行的時候,為函式申請記憶體,
第二步:創建一個函式 say ,把這個函式體中的代碼放在這個堆記憶體中,
函式體是以字串的形式放在堆記憶體中的,
為什么呢?我們來看一下 say 函式體的代碼:
let str = 'hello world'
console.log(str)這些陳述句以字串的形式放在堆記憶體中比較好,因為沒有規律,如果是物件,由于有規律,可以按照鍵值對的形式存盤在堆記憶體中,而沒規律的通常都是變成字串的形式,
第三步:在當前背景關系中宣告 say 函式(變數),函式宣告和定義會提升到最前面
注意,當前背景關系,我們可以理解為背景關系堆疊(堆疊),say 是放在堆疊(堆疊)中的,同時它的右邊還有一個堆記憶體地址,用來指向堆中的函式體的,
PS: 建議去學習一下資料結構,堆疊中的一塊一塊的,我們稱為幀,你可以把堆疊理解中 DOM 樹,幀理解為節點,每一幀( 節點 )都有自己的名字和內容,
第四步:把開辟的堆記憶體地址賦值給函式名 say
這里關鍵是把堆記憶體地址賦值給函式名 say ,
下面我畫了一個簡單的示意圖:
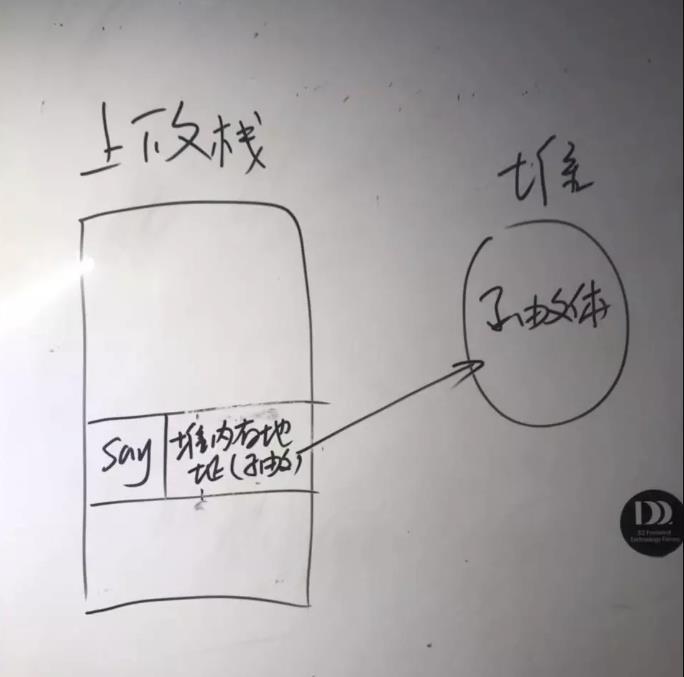
結合上圖 say 右邊的存盤,再去理解上面的四個步驟,是不是有點感悟了呢,
(2)你真的懂賦值這個操作嗎?
這里提到賦值操作,我把堆記憶體地址賦值給函式名 say 意味著什么呢?
賦值操作是從計算機組成原理角度看,記憶體分為好幾個區域,比如代碼區域,堆疊區域,堆區域等,
這幾個區域每一個存盤空間的記憶體地址都是不一樣,也就是說,賦值(參考型別)的操作就是將堆區域的某一個地址,通過總線管道流入(復制)到對應堆疊區域的某一個地址中,從而使堆疊區域的某一個地址內的存盤空間中有了參考堆區域資料的地址,業界叫句柄,也就是指標,只不過在高級語言中,把指標隱藏了,直接用變數代替指標,
所以一個簡單的賦值,其在計算機底層實作上,都是很復雜的,這里,也許通過匯編語言,可以更好的去理解賦值的真正含義,比如 1 + 1 用匯編語言撰寫,就是下面代碼:
start:
mov ax, 1
mov bx, 1
add ax, bx
end start;從上面代碼中,我們可以看到,把 1 賦值給 ax ,使用到了 mov 指令,而 mov 是 move 移動的縮寫,這也證明了,在賦值這個操作上,本質上是資料或者資料的句柄在一張地址表中的流動,
PS: 所以如果是值型別,那就是直接把資料,流(移動)到指定記憶體地址的存盤空間中,
以上是我從計算機底層去解釋一些創建函式方面最基礎的現象,先闡述到這里,
(3)執行函式
執行函式程序也非常重要,我用個人的總結去解釋執行這個程序,
思考一個點,
我們知道,函式體的代碼是以字串形式的保存在堆記憶體中的,如果我們要執行堆記憶體中的代碼,首先要將字串變成真正的 JS 代碼,就像資料傳輸中的序列化和反序列化,
思考題一:為什么會存在序列化和反序列化?大家可以自行思考一下,有些越簡單的道理,背后越是有著非凡的思想,
(4)將字串變成真正的 JS 代碼
每一個函式呼叫,都會在函式背景關系堆疊中創建幀,堆疊是一個基本的資料結構,
為什么函式執行要在堆疊中執行呢?
堆疊是先進后出的資料結構,也就意味著可以很好的保存和恢復呼叫現場,
來看一段代碼:
function f1() {
let b = 1;
function f2() {
cnsole.log(b)
}
return f2
}
let fun = f1()
fun()函式背景關系堆疊是什么?
函式背景關系堆疊是一個資料結構,如果學過 C++ 或者 C 的,可以理解成是一個 struct (結構體),這個結構體負責管理函式執行已經關閉變數作用域,函式背景關系堆疊在程式運行時產生,并且一開始加入到堆疊里面的是全域背景關系幀,位于堆疊底,
(5)開始執行函式
首先要明白一點:執行函式(函式呼叫)是在堆疊上完成的 ,
這也就是為什么 JS 函式可以遞回,因為堆疊先進后出的資料結構,賦予了其遞回能力,
繼續往下看,函式執行大致有以下四個步驟:
第一步:形成一個供代碼執行的環境,也是一個堆疊記憶體,
這里,我們先思考幾個問題:
這個供代碼執行的環境是什么?
這個堆疊記憶體是怎么分配出來的?
這個堆疊記憶體的內部是一種什么樣的樣子?
第二步:將存盤的字串復制一份到新開辟的堆疊記憶體中,使其變為真正的 JS 代碼,
第三步:先對形參進行賦值,再進行變數提升,比如將 var function 變數提升,
第四步:在這個新開辟的作用域中自上而下執行,
思考題:為什么是自上而下執行呢?
將執行結果回傳給當前呼叫的函式
思考題:將執行結果回傳給當前呼叫的函式,其背后是如何實作的呢?
三、談談底層實作
1、計算機中最本質的閉包解釋
函式在執行的時候,都會形成一個全新的私有作用域,也叫私有堆疊記憶體,
目的有如下兩點:
- 第一點:把原有堆記憶體中存盤的字串變成真正的 JS 代碼,
- 第二點:保護該堆疊記憶體的私有變數不受外界的干擾,
函式執行的這種保護機制,在計算機中稱之為 閉包 ,
可能有人不明白,咋就私有了呢?
沒問題,我們可以反推,假設不是私有堆疊記憶體的,那么在執行一個遞回時,基本就結束了,因為一個函式背景關系堆疊中,有很多相同的 JS 代碼,比如區域變數等,如果不私有化,那豈不亂套了?所以假設矛盾,私有堆疊記憶體成立,
2、堆疊記憶體是怎么分配出來?
JS 的堆疊記憶體是系統自動分配的,大小固定,如果自動適應的話,那就基本不存在除死回圈這種情況之外的堆疊溢位了,
3、這個堆疊記憶體的內部是一種什么樣的樣子?
舉個例子,每天寫 return 陳述句,那你知道 return 的底層是如何實作的嗎?每天寫子程式,那你知道子程式底層的一些真相嗎?
我們來看一張圖:
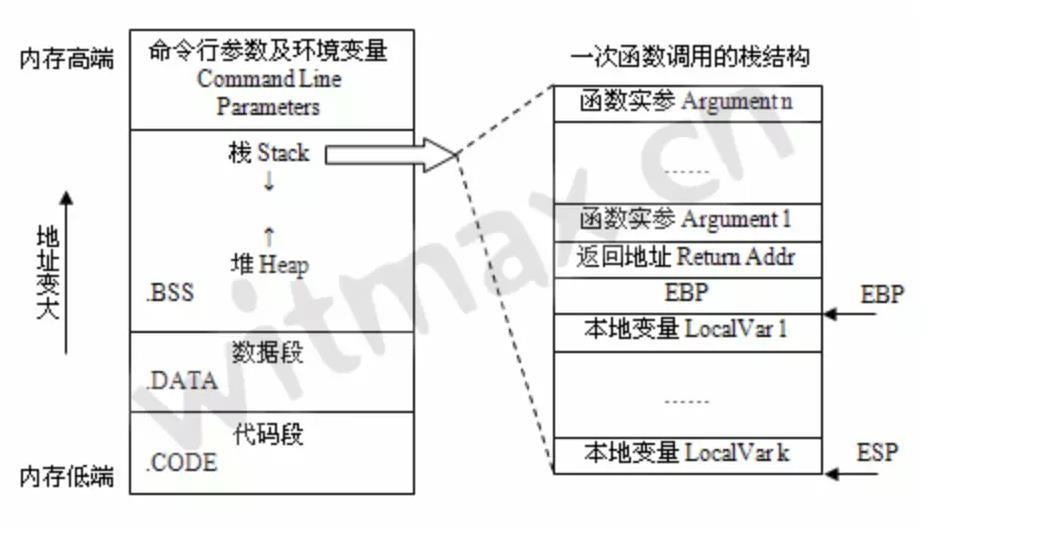
上圖顯示了一次函式呼叫的堆疊結構,從結構中可以看到,內部的組成部分,比如實參,區域變數,回傳地址,
看下面代碼:
function f1() {
return 'hello godkun'
}
let result = f1()
f2(result)上面這行代碼的底層含義就是,f() 函式在私有堆疊記憶體中執行完后,使用 return 后,將執行結果傳遞給 EAX (累加暫存器),常用于函式回傳值,
這里說一下 Return Addr ,Addr 主要目的是讓子程式能夠多次被呼叫,
看下面代碼:
function main() {
say()
// TODO:
say()
}如上,在 main 函式中進行多次呼叫子程式 say ,在底層實作上面,是通過在堆疊結構中保存一個 Addr 用來保存函式的起始運行地址,當第一個 say 函式運行完以后,Addr 就會指向起始運行地址,以備后面多次呼叫子程式,
四、JS 引擎是如何執行函式
上面從很多方面分析了函式執行的機制,現在來簡要分析一下,JS 引擎是如何執行函式的,
推薦一篇博客《探索JS引擎作業原理》,我將在此篇博客的基礎上分析一些很重要的細節,
代碼如下:
//定義一個全域變數 x
var x = 1
function A(y) {
//定義一個區域變數 x
var x = 2
function B(z) {
//定義一個內部函式 B
console.log(x + y + z)
}
//回傳函式B的參考
return B
}
//執行A,回傳B
var C = A(1)
//執行函式B
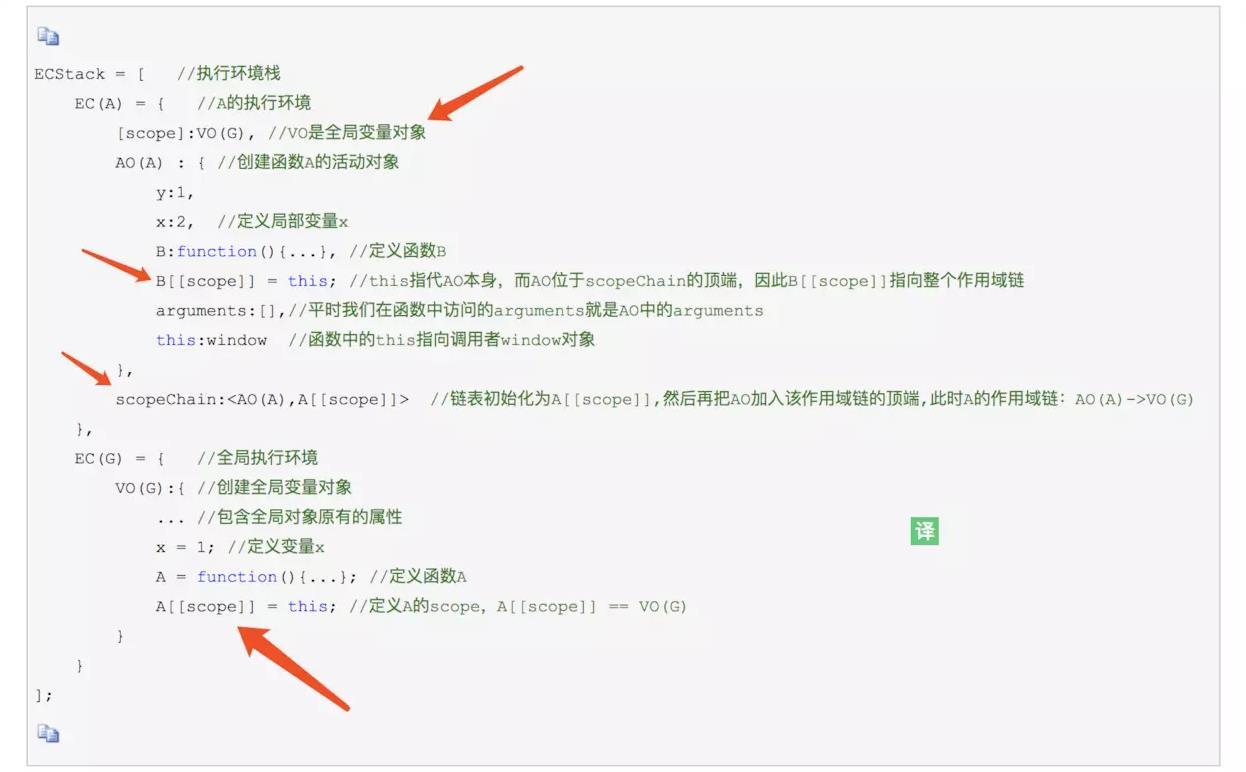
C(1)執行 A 函式時
JS 引擎構造的 ESCstack 結構如下:
簡稱 A 圖:
執行 B 函式時
JS 引擎構造的 ESCstack 結構如下:
簡稱 B 圖:

1、區域變數是如何被保存起來的
核心代碼:
EC(B) = {
[scope]:AO(A),
var AO(B) = {
z:1,
arguments:[],
this:window
},
scopeChain:<AO(B),B[[scope]]>
}這是在執行 B 函式 時,創建的 B 函式的執行環境(一個物件結構),里面有一個 AO(B) ,這是 B 函式的活動物件,
那 AO(B) 的目的是什么?其實 AO(B) 就是每個鏈表的節點其指向的內容,
同時,這里還定義了 [scope] 屬性,我們可以理解為指標,[scope] 指向了 AO(A) ,而 AO(A) 就是函式 A 的活動物件,
函式活動物件保存著 區域變數、引數陣列、this 屬性,這也是為什么可以在函式內部使用 this 和 arguments 的原因,
scopeChain 是作用域鏈,熟悉資料結構的同學肯定知道我函式作用域鏈本質就是鏈表,執行哪個函式,那鏈表就初始化為哪個函式的作用域,然后把當前指向的函式活動物件放到 scopeChain 鏈表的表頭中,
比如執行 B 函式,那 B 的鏈表看起來就是 AO(B) --> AO(A)
同時,A 函式也是有自己的鏈表的,為 AO(A) --> VO(G) ,所以整個鏈表就串起來來,B 的鏈表(作用域)就是:AO(B) --> AO(A) --> VO(G)
鏈表是一個倍訓,因為查了一圈,回到自己的時候,如果還沒找到,那就回傳 undefined ,
思考題:[scope] 和 [[scope]] 為什么以這種形式命名?
2、通過 A 函式的 ECS 我們能看到什么
我們能看到,JS 語言是靜態作用域語言,在執行函式之前,整個程式的作用域鏈就確定了,從 A 圖中的函式 B 的 B[[scope]] 就可以看到作用域鏈已經確定,不像 lisp 那種在運行時才能確定作用域,
3、執行環境,背景關系環境是一種什么樣的存在
執行環境的資料結構是堆疊結構,其實本質上是給一個陣列增加一些屬性和方法,
執行環境可以用 ECStack 表示,可以理解成 ECSack = [] 這種形式,
堆疊(執行環境)專門用來存放各種資料,比如最經典的就是保存函式執行時的各種子資料結構,比如 A 函式的執行環境是 EC(A),當執行函式 A 的時候,相當于 ECStack.push[A] ,當屬于 A 的東西被放入到堆疊中,都會被包裹成一個私有堆疊記憶體,
私有堆疊是怎么形成的?從匯編語言角度去看,一個堆疊的記憶體分配,堆疊結構的各種變換,都是有底層標準去控制的,
4、開啟上帝模式看穿 this
this 為什么在運行時才能確定
上面兩張圖中的紅色箭頭,箭頭處的資訊非常非常重要,
看 A 圖,執行 A 函式時,只有 A 函式有 this 屬性,執行 B 函式時,只有 B 函式有 this 屬性,這也就證實了 this 只有在運行時才會存在,
this 的指向真相
看一下 this 的指向,A 函式呼叫的時候,屬性 this 的屬性是 window ,而 通過 var C = A(1) 呼叫 A 函式后,A 函式的執行環境已經 pop 出堆疊了,此時執行 C() 就是在執行 B 函式,EC(B) 已經在堆疊頂了,this 屬性值是 window 全域變數,
通過 A 圖 和 B 圖的比較,直接展示 this 的本質,
5、作用域的本質是鏈表中的一個節點
通過 A 圖 和 B 圖的比較,直接秒殺 作用域 的所有用法
看 A 圖,執行 A 函式時,B 函式的作用域是創建 A 函式的活動物件 AO(A) ,作用域就是一個屬性,一個屬于 A 函式的執行環境中的屬性,它的名字叫做 [scope] ,
[scope] 指向的是一個函式活動物件,核心點是把這個函式物件當成一個作用域,最好理解成一個鏈表節點,
PS: B 執行 B 函式時,只有 B 函式有 this 屬性,這也就交叉證實了 this 只有在運行時才會存在,
6、作用域鏈的本質就是鏈表
通過比較 A 圖和 B 圖的 scopeChain ,可以確定的是:
作用域鏈本質就是鏈表,執行哪個函式,鏈表就初始化為哪個函式的作用域,然后將該函式的 [scope] 放在表頭,形成倍訓鏈表,作用域鏈是通過鏈表查找的,如果走了一圈還沒找到,那就回傳 undefined ,
五、用一道面試題讓你更上一層樓(走火入魔)
再舉一個例子,這是一道經常被問的面試題,看下面代碼:
第一個程式如下:
function kun() {
var result = []
for (var i = 0; i < 10; i++) {
result[i] = function() {
return i
}
}
return result
}
let r = kun()
r.forEach(fn => {
console.log('fn',fn())
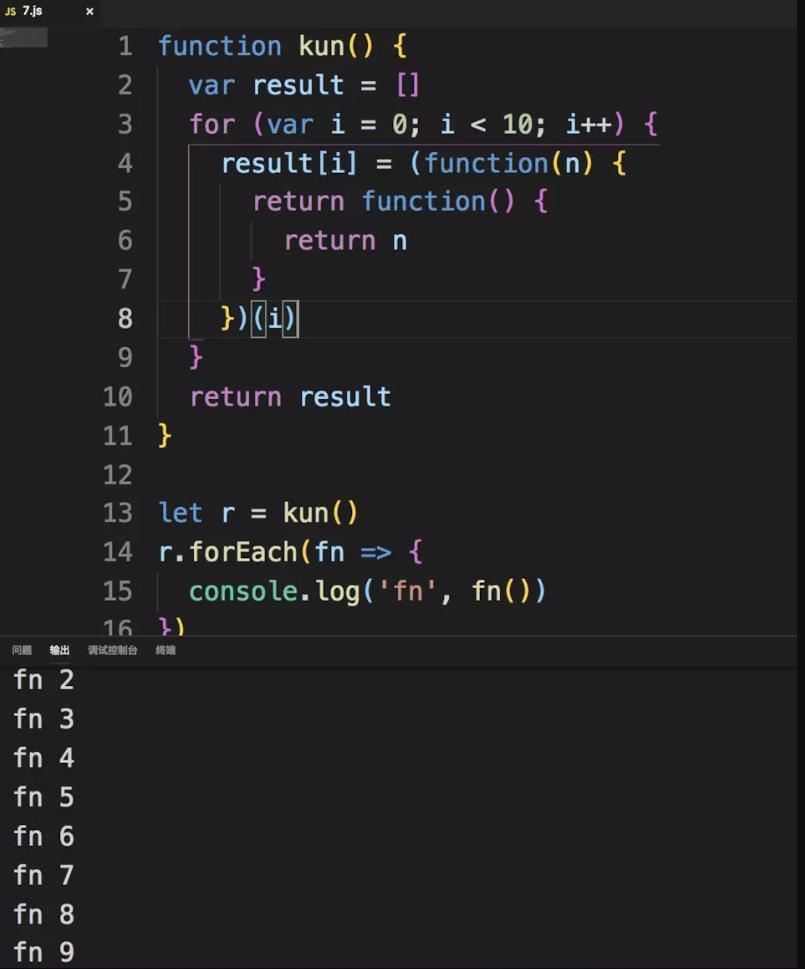
})第二個程式如下:
function kun() {
var result = []
for (var i = 0; i < 10; i++) {
result[i] = (function(n) {
return function() {
return n
}
})(i)
}
return result
}
let r = kun()
r.forEach(fn => {
console.log('fn', fn())
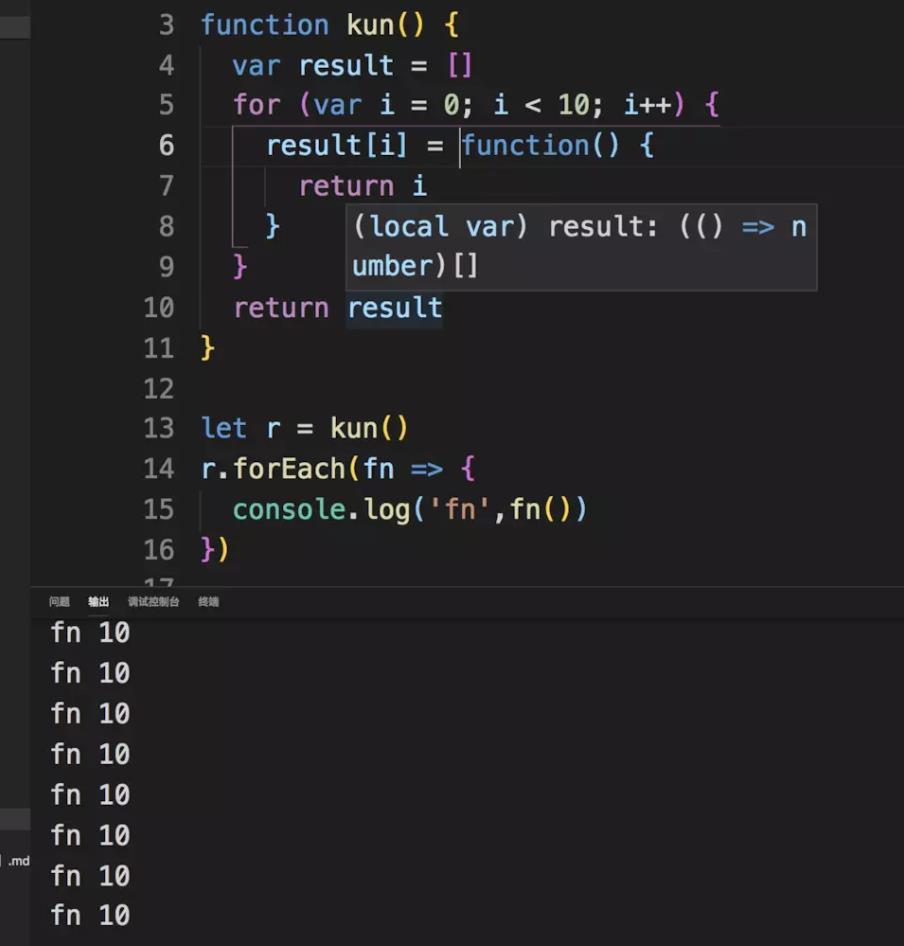
})輸出結果大家應該都知道了,結果分別是如下截圖:
第一個程式,輸出 10 個 10 :
第二個程式,輸出 0 到 9 :
那么問題來了,其內部的原理機制是什么呢?
-
一部分 coder 只能答到立即呼叫,閉包,
-
大多數 coder 可以答到作用域相關知識,
-
極少部分 coder (大佬級別) 可以從核心底層原因來分析,
下面從核心底層原因來分析 ,
1、分析輸出10個10
代碼如下:
function kun() {
var result = []
for (var i = 0; i < 10; i++) {
result[i] = function() {
return i
}
}
return result
}
let r = kun()
r.forEach(fn => {
console.log('fn',fn())
})只有函式在執行的時候,函式的執行環境才會生成,依據這個規則,在完成 r = kun() 的時候,kun 函式只執行了一次,生成了對應的 AO(kun) ,如下:
AO(kun):{
i = 10;
kun = function(){...};
kun[[scope]] = this;
}這時,在執行 kun() 之后,i 的值已經是 10 了,請注意,kun 函式只執行了一次,也就意味著:
在 kun 函式的 AO(kun) 中的 i 屬性是 10 ,
繼續分享, kun 函式的作用域鏈如下:
AO(kun) --> VO(G)而且 kun 函式已經從堆疊頂被洗掉了,只留下 AO(kun) ,
注意:這里的 AO(kun) 表示一個節點,這個節點有指標和資料,其中指標指向了 VO(G) ,資料就是 kun 函式的活動物件,
那么,當一次執行 result 中的陣列的時候,會發生什么現象?
注意:result 陣列中的每一個函式其作用域都已經確定了,而 JS 是靜態作用域語言,其在程式宣告階段,所有的作用域都將確定,
那么 ,result 陣列中每一個函式其作用域鏈如下:
AO(result[i]) --> AO(kun) --> VO(G)因此 result 中的每一個函式執行時,其 i 的值都是沿著這條作用域鏈去查找的,而且由于 kun 函式只執行了一次,導致了 i 值是最后的結果,也就是 10 ,所以輸出結果就是 10 個 10 ,
總結一下,就是 result 陣列中的 10 個函式在宣告后,總共擁有了 10 個鏈表(作用域鏈),都是 AO(result[i]) --> AO(kun) --> VO(G)這種形式,但是 10 個作用域鏈中的 AO(kun) 都是一樣的,所以導致了,輸出結果是 10 個 10 ,
下面我們來分析輸出 0 到 9 的結果,
2、分析輸出0到9
代碼如下:
function kun() {
var result = []
for (var i = 0; i < 10; i++) {
result[i] = (function(n) {
return function() {
return n
}
})(i)
}
return result
}
let r = kun()
r.forEach(fn => {
console.log('fn', fn())
})首先,在宣告函式 kun 的時候,就已經執行了 10 次匿名函式,函式在執行時將生成執行環境,也就意味著,在 ECS 堆疊中,有 10 個 EC(kun) 執行環境,分別對應result 陣列中的 10 個函式,
下面通過偽代碼來展示:
ECSack = [
EC(kun) = {
[scope]: VO(G)
AO(kun) = {
i: 0,
result[0] = function() {...// return i},
arguments:[],
this: window
},
scopeChain:<AO(kun), kun[[scope]]>
},
// .....
EC(kun) = [
[scope]: VO(G)
AO(kun) = {
i: 9,
result[9] = function() {...// return i},
arguments:[],
this: window
},
scopeChain:<AO(kun), kun[[scope]]>
]
]上面簡單的用結構化的語言表示了 kun 函式在宣告時的內部情況,需要注意一下兩點:
第一點:每一個 EC(kun) 中的 AO(kun) 中的 i 屬性值都是不一樣的,比如通過上面結構化表示,可以看到:
-
result[0] 函式的父執行環境是 EC(kun) ,這個 VO(kun) 里面的 i 值 是 0 ,
-
result[9] 函式的父執行環境是 EC(kun) ,這個 VO(kun) 里面的 i 值 是 9 ,
記住 AO(kun) 是一段存盤空間,
第二點:關于作用域鏈,也就是 scopeChain ,result 中的函式的 鏈表形式仍然是下面這種形式:
AO(result[i]) --> AO(kun) --> VO(G)但不一樣的是,對應節點的存盤地址不一樣,相當于是 10 個新的 AO(kun) ,而每一個 AO(kun) 的節點內容中的 i 值是不一樣的,
所以總結就是:執行 result 陣列中的 10 個函式時,運行10 個不同的鏈表,同時每個鏈表的 AO(kun) 節點是不一樣的,每個 AO(kun) 節點中的 i 值也是不一樣的,
所以輸出的結果最后顯示為 0 到 9 ,
六、總結
通過對底層實作原理的分析,我們可以更加深刻的去理解函式的執行機制,從而寫出高質量的函式,
如何減少作用域鏈(鏈表)的查找
比如很多庫,像JQ 等,都會在立即執行函式的最外面傳一個 window 引數,這樣做的目的是因為,window 是全域物件,通過傳參,避免了查找整個作用域鏈,提高了函式的執行效率,
如何防止堆疊溢位?每一次執行函式,都會創建函式的執行環境,也就意味著占用一些堆疊記憶體,而堆疊記憶體大小是固定的,如果寫了很大的遞回函式,就會造成堆疊記憶體溢出,引發錯誤,
我覺得,我們要去努力的達成這樣一個成就:
做到當我在手寫一個函式時,我心中非常清楚的知道我正在寫的每一行代碼,其在記憶體中是怎么表現的,或者說其在底層是如何執行的,從而達到** 眼中有碼,心中無碼** 的境界,
如果能做到這樣的話,那還怕寫不出高質量的函式嗎?
七、參考檔案
-
JS 函式的創建和執行機制
-
探索JS引擎作業原理
-
程式記憶體空間(代碼段、資料段、堆疊段)
-
函式呼叫–函式堆疊
-
堆疊向上增長和向下增長的深入理解
更多內容敬請關注 vivo 互聯網技術 微信公眾號

注:轉載文章請先與微信號:labs2020 聯系,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/95209.html
標籤:其他