如果第二次看到我的文章,歡迎右側掃碼訂閱我喲~ ??
每周五11:45 按時送達,當然了,也會時不時加個餐~
我的第「124」篇原創敬上
?
大家好,我是Z哥,
好久沒寫技術文章了,最近正好有進行一些思考,順手寫出來分享給大家,
上了一定規模的系統,特別是To C的系統,性能優化或多或少都會被逼著去做一下,否則,系統便無法支撐業務的發展,技術成了拖后腿,不是引領業務了,
一旦線上出現了性能問題,就會很棘手,因為它和業務功能上的Bug不同,后者的分析和解決思路更清晰,只要日志記錄到位,沿著一條已知的業務邏輯線,很容易就能找到問題根源,
而性能問題就會復雜的多,導致的因素有很多,甚至會是多種因素共同作用下的結果,比如,代碼質量低下、業務發展太快、架構設計不合理等等,
而且一般情況下,性能問題處理起來比較耗時,涉及到的分析鏈路可能會很長,特別是自己小組之外的上下游系統,很多人不愿意干,或者說有心無力,最多采用一些臨時性的補救手段,碰碰運氣,比如,擴容增加機器、重啟大招、……,
有些臨時性的補救措施,有時候不但不能解決問題,還會埋下新的隱患,
比如,從表象上看到某個程式因為給的資源不足導致產生性能問題,臨時增加更多資源給它,可能從表面上看,問題是解決了,但是實則可能是因為程式內部對資源的使用上存在不合理的地方,增加資源只是延緩問題發作的時間,而且還可能會侵占其它程式的運行資源,
為了避免陷入如此的窘境,我們應當盡量提前進行性能優化,未雨綢繆,甚至最好是將它作為一個周期性的作業來進行,
接下去就來分享一下我對做性能優化的思路,
/01 明確優化目的/
很多人優化優化著慢慢變成了為了優化而優化,目的丟了,或者甚至一開始就沒考慮過,如此會陷入到無意義的性能黑洞中,無法自拔,只是不斷追求更好看的性能指標,
優化的目的可以是增強用戶體驗,比如消除一些有明顯卡頓的頁面和操作,還可以是節省服務器帶寬流量、減少服務器壓力這些,無論如何,你需要有一個目的,
/02 定標準,做到什么程度/
優化這事是永無止境的,為了避免陷入到前面說的無意義的性能黑洞中,我們最好能夠根據實際的業務情況定義出一個相對客觀的標準,代表優化到什么程度,
我自己慣用的標準是確保比預期高50%,如果條件允許則爭取到100%,
比如,根據當下的性能指標與業務量對比,發現最大并發數可能會超過當前的2倍,那么此時優化到爭取優化提升3倍,至少保證能提升2.5倍,是一個比較合理的標準,
之前專門寫過一篇關于容量預估的文章《做「容量預估」可沒有true和false》,可以在文末跳轉過去看下,這里就不展開了,
/03 找到瓶頸點/
很多人做優化的時候,逮著代碼就開始改,的確,只要有一定的知識積累,很容易就能從代碼中發現,寫法A不如寫法B這樣的代碼,
但其實大部分情況下,「流程上的優化遠勝于語法級別的優化」,比如將每一個字串拼接改成用StringBuilder來實作,大多數情況下帶來的成果其實很小,甚至在某些情況下還不如不改,
所以,我們最好還是能夠借助一些客觀資料,以獲得更多的運行環境相關的資訊,來找到整個“木桶”上最短的一塊“板”,如整個系統的總體架構、服務器的資訊等,便于定位到底性能的瓶頸點在哪,
「流程上的優化遠勝于語法級別的優化」中的“流程”除了業務流程之外,還包括技術層面的流程,比如資料在網路中的流轉程序,
/04 著手優化/
最后才是著手優化,
做優化的時候需要避免兩個常見的誤區,
第一,不要過度追求應用的單機性能,如果單機表現良好,還應該從整體的角度去思考,
第二,不要過度追求單一維度上的極致優化,比如過度追求 CPU 的性能而忽略了記憶體方面的瓶頸,
正確的思路一般符合下面兩個方向,
第一,空間換性能,一個節點頂不住就多復制一個節點出來,獨一份的資料導致資源競爭得厲害,就多復制一份資料出來,
第二,距離換性能,資料從服務端經過層層處理回傳到客戶端覺得慢的話,那么能不能直接保存在客戶端,或者至少是離客戶端盡可能近的地方,
好了,思路清楚了,具體在做的時候我建議你根據下面小標題的順序進行,不管是主動地性能優化,還是被動地排查性能問題都一樣,
/01 應用程式層面/
不管你愿不愿意承認,現實中的大部分性能問題皆是應用程式自身部分的代碼導致的,
我們總是不太愿意承認自己的錯誤,我見過太多程式員總是習慣性的將問題先歸結于硬體問題,網路問題等等,然后最終排查下來的根源往往還是在coding的應用程式上,
所以,我們更應該先從應用程式本身入手進行分析,而且,應用程式所處的位置更「上游」,可操作性更強,讓我們可以有更多的手段進行優化,
01 快取
首先,最常見的便是「快取」,這是用空間換性能的經典,
資料必然是存盤在非易失性的資料庫中的,但是一些會被高頻訪問的資料,將它從資料庫中復制一份,存盤在易失性的記憶體上做快取,可以大大提高被訪問的性能,這個道理大家都懂,就不多說了,
但是值得提醒的一點是,快取資料的資料結構設計很重要,沒有一種資料結構是萬能的,需要更多的權衡,因為資料結構設計的越簡單、單一,快取資料的二次運算就越多;反之,所有都存盤「結果資料」的話,需要冗余的資料量又過大(快取資料更新還麻煩),
還得提醒一點,如果快取的資料量不小,還得考慮增加一個快取淘汰演算法,否則快取命中率不堪入目,白白浪費大量記憶體資源,
之前的《分布式系統系列》中有幾篇快取相關的聊了很多細節,可以在文末跳過去查閱,
02 異步
舉個現實生活中的例子,如果你在手機上點了一杯奶茶,去店里拿的時候發現前面還有20個號,你會在這干等半小時么?
我想大部分人都不會吧,寧愿去別的地方溜溜,異步就是通過避免“干等著”來提升性能的手段,
做異步主要是以下兩種方式,
-
通過執行緒進行異步,這主要用于涉及到I/O的地方,像磁盤I/O和網路I/O,一旦產生I/O其實就意味著背后的操作是由另外一個程式在進行,此時CPU就不用空著了,讓它忙別的去吧,
-
通過中間件異步,比如MQ,這用于更大的場景里,比如在某些流程中、上下游系統的銜接中,如果有些結果并不需要實時收到,那么通過MQ進行異步就可以大大提高性能,畢竟MQ的性能更接近NoSQL,性能自然比關系型資料庫高的多,更何況,還將一些業務邏輯的預算給滯后了,當下的性能會更好,
03 多執行緒&分布式
這兩點都是「分治」思想的體現,一個快遞員送1000個包裹比較慢,那么讓10個快遞員同時各送100個自然就快了,
但是切勿分的太狠,畢竟,多起一個執行緒相當于多一個放養的娃,放出去太多的話,管理成本很高,可能反而會更慢,這就是執行緒切換的成本,分布式系統中也存在類似的管理成本,
不過,一個小建議送給你,不到迫不得已,能通過「單機多執行緒」應付的,就不要引入分布式了,因為,網路這個東西實在太不靠譜了,你得為它做大量的額外作業,
04 延后運算
這個和快取的思路相反,將一些運算盡可能的延后到用的時候,適用的場景也和快取相反,適用于一些低頻的、運算耗時的資料上,
延遲加載、插件化等等就是該思想的體現,
05 批量,合并
如果你需要在短時間內頻繁的傳遞多個資料給同一個目的地,那么盡量考慮將他們打包到一起,一次性傳輸,特別是涉及到I/O的場景,
如果手頭的系統還是一個單點系統,這招的性價比就非常高,在避開分布式系統的復雜性的前提下,獲得性能提升,
資料庫的bulk操作,前端的sprite圖,都是該思想的體現,
應用程式層面的其它優化方式還有很多,比如,用長鏈接代替頻繁打開關閉的短鏈接、壓縮、重用等等,這些相對比較簡單和好理解,就不多說了,
應用程式層面的事情做到位了之后,我們再來考慮組件層面的優化,
/02 組件層面/
組件是指那些非業務性的東西,比如一些中間件、資料庫、運行時的環境(JVM、WebServer)等,
資料庫的調優,總的來說分為以下三部分:
-
SQL陳述句,
-
索引,
-
連接池,
其它的一些,比如JVM的調優最主要的就是對「GC」相關的配置調優,WebServer的調優主要是針對「連接」相關的調優,這些細節就不贅述了,資料多到看不過來,
/03 系統層面/
系統層面的一些調優作業,涉及到運維工程師的一些作業,我不是很擅長就不誤人子弟了,但是我們可以借助系統層面的一些技術指標來觀測并判斷我們的程式是否正常,比如,CPU、執行緒、網路、磁盤、記憶體,
01 CPU
判斷CPU是否正常,大多數情況下關注這三個指標就夠了,CPU利用率、CPU平均負載、CPU背景關系切換,CPU利用率大家基本上都知道,就不多說了,那就說說后面兩個,
關注CPU平均負載的時候,特別需要注意趨勢的變化,如果 1 分鐘/5 分鐘/15 分鐘的三個值相差不大,那說明系統負載很平穩,則不用關注,如果這三個值逐漸降低,說明負載在漸漸升高,需要排查具體的原因,
CPU背景關系切換,背景關系切換的次數越多,就意味著更多的CPU時間消耗在暫存器、內核堆疊以及虛擬記憶體等資料的保存和恢復上,真正進行你所期望的運算作業的時間就越少,系統的整體性能自然就會下降,導致這個情況的原因主要有兩點,
-
程式內的磁盤I/O、網路I/O比較多,
-
程式內啟動的執行緒過多,
02 執行緒
執行緒方面除了關注執行緒數之外,還需要關注一下處于「掛起」狀態的執行緒數量有多少,
掛起狀態的執行緒數過多,意味著程式里鎖競爭激烈,需要考慮通過其它的方案來縮小鎖的粒度、級別,甚至是避免用鎖,
03 網路
通常在硬體層面內網帶寬會遠大于外網的帶寬,所以,外網帶寬被吃滿的情況更加常見,特別是多圖、多流媒體型別的可對外訪問系統,關于流量大小相關的問題一般大家都能想到,就不多說了,
但是,Z哥提醒你要特別關注埠的使用和每個埠上的連接狀態情況,比較常見的問題是,連接用完有沒有及時釋放,導致埠被占滿,后續新的網路請求無法建立連接通道,(可以通過netstat、ss獲取網路相關的資訊,)
04 磁盤
除非是規模非常大的系統,否則一般情況下,從磁盤的指標上看不出啥問題,
平時看的時候,除了看看利用率、吞吐量和請求數量之外,有兩個容易被忽略的點可以多關注下,
第一點,如果I/O利用率很高,但是吞吐量很小,則意味著存在較多的磁盤隨機讀寫,最好把隨機讀寫優化成順序讀寫,(可以通過 strace 或者 blktrace 觀察 I/O 是否連續判斷是否是順序的讀寫行為)
其次,如果I/O等待佇列的長度比較大,則該磁盤存在 I/O 性能問題,一般來說,如果佇列長度持續超過2就可以這么認為,
05 記憶體
關注記憶體的時候除了記憶體消耗之外,有一個Swap換入和換出的記憶體大小需要特別注意一下,因為Swap需要讀寫磁盤,所以性能不是很高,如果GC的時候遍歷到的物件恰巧被Swap 出去了,便會有磁盤I/O產生,性能自然會下降,所以這個指標不應該太高,
大多數記憶體問題,都和物件常駐記憶體不及時釋放有關,有很多工具可以觀察物件的記憶體分配情況,如,jmap、VisualVM、heap dump等,
如果你的程式部署在linux系統上的話,不得不錯過Brendan Gregg的大神整理的精華,下面就參考一張圖,給大家感受一下,具體可以去 http://www.brendangregg.com/linuxperf.html 自行查閱更多相關的內容,
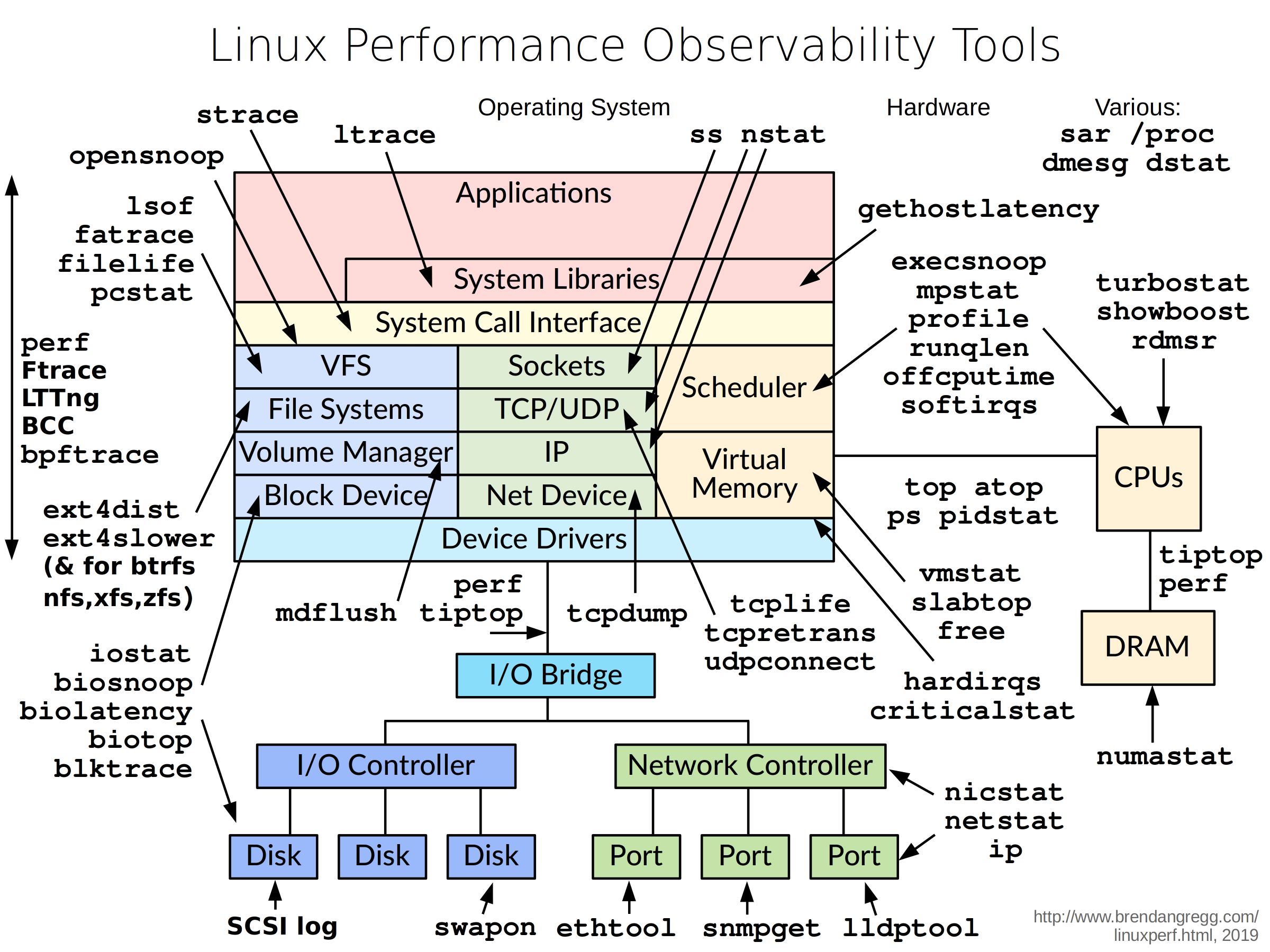
▲圖片來自于brendangregg.com
最后,雖然性能優化是一件大家都知道的好事,但是再好的事做起來都有成本,所以,如非必要,不要過早、過度進行性能優化哦,
好了,總結一下,
這篇呢,Z哥和你聊了一下非常讓程式員們頭疼的程式性能問題,想要避免受這個問題困擾的前提是事前做好性能優化作業,
做性能優化不能走一步算一步,事先需要做三件事「明確優化目的」、「定標準」、「找到瓶頸點」,
具體做優化的時候建議從應用程式層面開始,再到組件層面,最后才是系統層面,從上往下,層層深入,順帶分享了每個層面的常用一些方法和思路,
希望對你有所啟發,
在一個大系統中,資料就像水,整個系統就像是一個漏斗,漏斗的每一層代表每個子程式,上層的子程式對性能的損耗越低,能流下去的水就越多,直到最后一層「資料庫」處,也可以理解為是存盤,
所以,趕緊行動起來,開啟保衛資料庫之戰吧,
推薦閱讀:
-
8個月打磨,一份送給程式員的「分布式系統」合集
-
做「容量預估」可沒有true和false
作者:Zachary
出處:https://zacharyfan.com/archives/1051.html
如果你喜歡這篇文章,可以點一下右下角的「推薦」,
這樣可以給我一點反饋,: )
謝謝你的舉手之勞,
既然看到這了,送我一個「贊同」吧,支持我的創作,
想更進一步和我一起玩耍,歡迎「搜索微信公號:跨界架構師」或者在「右側掃描」,
內容包括:架構設計丨分布式系統丨產品丨運營丨個人深度思考,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/95230.html
標籤:其他