HTTP協議介紹
設計HTTP(HyperText Transfer Protocol)是為了提供一種發布和接收HTML(HyperText Markup Language)頁面的方法,
Http組成
由兩部分組成:請求與回應
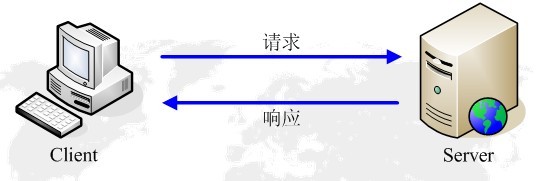
客戶端請求訊息
客戶端發送一個HTTP請求到服務器的請求訊息包括以下格式:請求行(request line)、請求頭部(header)、空行和請求資料四個部分組成,下圖給出了請求報文的一般格式,
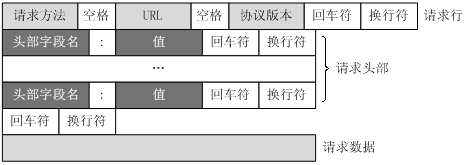
服務器回應訊息
HTTP回應也由四個部分組成,分別是:狀態行、訊息報頭、空行和回應正文,
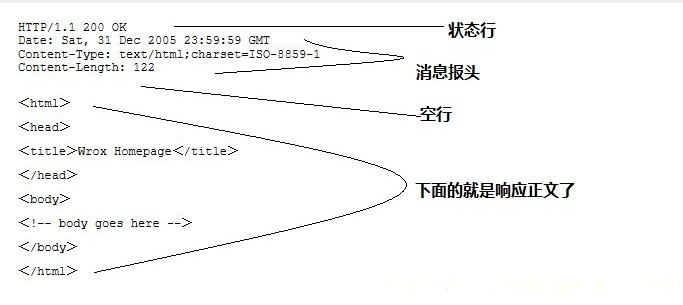
先看Request 訊息的結構, Request 訊息分為3部分,第一部分叫Request line, 第二部分叫Request header, 第三部分是body. header和body之間有個空行, 結構如下圖

抽象的東西,難以理解,老感覺是虛的, 所謂眼見為實, 實際見到的東西,我們才能理解和記憶, 我們今天用Fiddler,實際的看看Request和Response.
下面我們打開Fiddler 捕捉一個博客園登錄的Request 然后分析下它的結構, 在Inspectors tab下以Raw的方式可以看到完整的Request的訊息,
我們再看Response訊息的結構, 和Request訊息的結構基本一樣, 同樣也分為三部分,第一部分叫Response line, 第二部分叫Response header,第三部分是body. header和body之間也有個空行, 結構如下圖
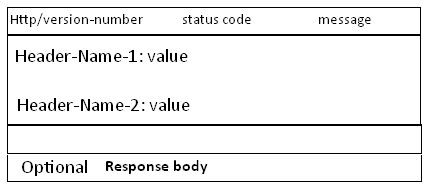
HTTP/version-number表示HTTP協議的版本號, status-code 和message 請看下節[狀態代碼]的詳細解釋.
我們用Fiddler 捕捉一個博客園首頁的Response然后分析下它的結構, 在Inspectors tab下以Raw的方式可以看到完整的Response的訊息, 如下圖

提出一個問題
服務器和客戶端的互動僅限于請求/回應程序,結束之后便斷開,在下一次請求服務器會認為新的客戶端;
為了維護他們之間的鏈接,讓服務器知道這是前一個用戶發送的請求,必須在一個地方保存客戶端的資訊,
- Cookie通過在客戶端記錄資訊確定用戶身份
- Session通過在服務器端記錄資訊確定用戶身份
HTTP 請求
- 請求方法
根據HTTP標準,HTTP請求可以使用多種請求方法,
HTTP1.0定義了三種請求方法: GET, POST 和 HEAD方法,
HTTP1.1新增了五種請求方法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT 方法,
| 序號 | 方法 | 描述 |
|---|---|---|
| 1 | GET | 請求指定的頁面資訊,并回傳物體主體, |
| 2 | HEAD | 類似于get請求,只不過回傳的回應中沒有具體的內容,用于獲取報頭 |
| 3 | POST | 向指定資源提交資料進行處理請求(例如提交表單或者上傳檔案),資料被包含在請求體中,POST請求可能會導致新的資源的建立和/或已有資源的修改, |
| 4 | PUT | 從客戶端向服務器傳送的資料取代指定的檔案的內容, |
| 5 | DELETE | 請求服務器洗掉指定的頁面, |
| 6 | CONNECT | HTTP/1.1協議中預留給能夠將連接改為管道方式的代理服務器, |
| 7 | OPTIONS | 允許客戶端查看服務器的性能, |
| 8 | TRACE | 回顯服務器收到的請求,主要用于測驗或診斷, |
GET和POST方法區別歸納如下幾點:
- GET是從服務器上獲取資料,POST是向服務器傳送資料,
- GET請求引數顯示,都顯示在瀏覽器網址上,POST請求引數在請求體當中,訊息長度沒有限制而且以隱式的方式進行發送
- 盡量避免使用Get方式提交表單,因為有可能會導致安全問題,比如說在登陸表單中用Get方式,用戶輸入的用戶名和密碼將在地址欄中暴露無遺,但是在分頁程式中,用Get方式就比用Post好,
Http協議定義了很多與服務器互動的方法,最基本的有4種,分別是GET,POST,PUT,DELETE. 一個URL地址用于描述一個網路上的資源,而HTTP中的GET, POST, PUT, DELETE就對應著對這個資源的查,改,增,刪4個操作, 我們最常見的就是GET和POST了,GET一般用于獲取/查詢資源資訊,而POST一般用于更新資源資訊.
我們看看GET和POST的區別
GET提交的資料會放在URL之后,以?分割URL和傳輸資料,引數之間以&相連,如EditPosts.aspx?name=test1&id=123456. POST方法是把提交的資料放在HTTP包的Body中.
GET提交的資料大小有限制(因為瀏覽器對URL的長度有限制),而POST方法提交的資料沒有限制.
GET方式需要使用Request.QueryString來取得變數的值,而POST方式通過Request.Form來獲取變數的值,
GET方式提交資料,會帶來安全問題,比如一個登錄頁面,通過GET方式提交資料時,用戶名和密碼將出現在URL上,如果頁面可以被快取或者其他人可以訪問這臺機器,就可以從歷史記錄獲得該用戶的賬號和密碼.
URL概述
統一資源定位符(URL,英語 Uniform / Universal Resource Locator的縮寫)是用于完整地描述Internet上網頁和其他資源的地址的一種標識方法,
URL格式:
基本格式如下schema://host[:port#]/path/…/[?query-string][#anchor]
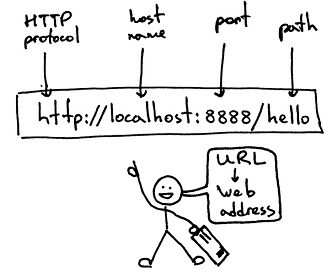
- schema 協議(例如:http, https, ftp)
- host 服務器的IP地址或者域名
- port# 服務器的埠(如果是走協議默認埠,預設埠80)
- path 訪問資源的路徑
- query-string 引數,發送給http服務器的資料
- anchor- 錨(跳轉到網頁的指定錨點位置)
例子:
- http://www.sina.com.cn/
- http://192.168.0.116:8080/index.jsp
- http://item.jd.com/11052214.html#product-detail
- http://www.website.com/test/test.aspx?name=sv&x=true#stuff一個URL的請求程序:
當你在瀏覽器輸入URL http://www.website.com 的時候,瀏覽器發送一個Request去獲取 http://www. website.com的html. 服務器把Response發送回給瀏覽器.瀏覽器分析Response中的 HTML,發現其中參考了很多其他檔案,比如圖片,CSS檔案,JS檔案,瀏覽器會自動再次發送Request去獲取圖片,CSS檔案,或者JS檔案,當所有的檔案都下載成功后, 網頁就被顯示出來了,
常用的請求報頭
- Host
Host初始URL中的主機和埠,用于指定被請求資源的Internet主機和埠號,它通常從HTTP URL中提取出來的
- Connection
表示客戶端與服務連接型別;
- client 發起一個包含Connection:keep-alive的請求
-
server收到請求后,如果server支持keepalive,回復一個包含Connection:keep-alive的回應,不關閉連接,否則回復一個包含Connection:close的回應,關閉連接,
-
如果client收到包含Connection:keep-alive的回應,向同一個連接發送下一個請求,直到一方主動關閉連接,Keep-alive在很多情況下能夠重用連接,減少資源消耗,縮短回應時間HTTP
- Accept
表示瀏覽器支持的 MIME 型別
MIME的英文全稱是 Multipurpose Internet Mail Extensions(多用途互聯網郵件擴展)
eg:
Accept:image/gif,表明客戶端希望接受GIF圖象格式的資源;
Accept:text/html,表明客戶端希望接受html文本,
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
意思:瀏覽器支持的 MIME 型別分別是 text/html、application/xhtml+xml、application/xml 和 */*,優先順序是它們從左到右的排列順序,
Text:用于標準化地表示的文本資訊,文本訊息可以是多種字符集和或者多種格式的;
Application:用于傳輸應用程式資料或者二進制資料;設定某種擴展名的檔案用一種應用程式來打開的方式型別,當該擴展名檔案被訪問的時候,瀏覽器會自動使用指定應用程式來打開
| Mime型別 | 擴展名 |
|---|---|
| text/html | .htm .html .shtml |
| text/plain | text/html是以html的形式輸出,比如<input type="text"/>就會在頁面上顯示一個文本框,而以plain形式就會在頁面上原樣顯示這段代碼 |
| application/xhtml+xml | .xhtml .xml |
| text/css | .css |
| application/msexcel | .xls .xla |
| application/msword | .doc .dot |
| application/octet-stream | .exe |
| application/pdf | |
| ….. | ….. |
q是權重系數,范圍 0 =< q <= 1,q 值越大,請求越傾向于獲得其“;”之前的型別表示的內容,若沒有指定 q 值越大,請求越傾向于獲得其“,則默認為1,若被賦值為0,則用于提醒服務器哪些是瀏覽器不接受的內容型別,
- Content-Type
POST 提交,application/x-www-form-urlencoded 提交的資料按照 key1=val1&key2=val2 的方式進行編碼,key 和 val 都進行了 URL 轉碼,
- User-Agent
瀏覽器型別
- Referer
請求來自哪個頁面,用戶是從該 Referer URL頁面訪問當前請求的頁面,
- Accept-Encoding
瀏覽器支持的壓縮編碼型別,比如gzip,支持gzip的瀏覽器回傳經gzip編碼的HTML頁面,
許多情形下這可以減少5到10倍的下載時間
eg:
Accept-Encoding:gzip;q=1.0, identity; q=0.5, *;q=0 // 按順序支持 gzip , identity
如果有多個Encoding同時匹配, 按照q值順序排列
如果請求訊息中沒有設定這個域服務器假定客戶端對各種內容編碼都可以接受,
- Accept-Language
瀏覽器所希望的語言種類,當服務器能夠提供一種以上的語言版本時要用到,
eg:Accept-Language:zh-cn
如果請求訊息中沒有設定這個報頭域,服務器假定客戶端對各種語言都可以接受,
- Accept-Charset
瀏覽器可接受的字符集,用于指定客戶端接受的字符集
eg:
Accept-Charset:iso-8859-1,gb2312
ISO8859-1,通常叫做Latin-1,Latin-1包括了書寫所有西方歐洲語言不可缺少的附加字符;
gb2312是標準中文字符集;
UTF-8 是 UNICODE 的一種變長字符編碼,可以解決多種語言文本顯示問題,從而實作應用國際化和本地化,
如果在請求訊息中沒有設定這個域,預設是任何字符集都可以接受,
HTTP 回應
學習目的
掌握常用的回應狀態碼
- 回應狀態碼
回應狀態代碼有三位數字組成,第一個數字定義了回應的類別,且有五種可能取值:
狀態碼
Response 訊息中的第一行叫做狀態行,由HTTP協議版本號, 狀態碼, 狀態訊息 三部分組成,
狀態碼用來告訴HTTP客戶端,HTTP服務器是否產生了預期的Response.
HTTP/1.1中定義了5類狀態碼, 狀態碼由三位數字組成,第一個數字定義了回應的類別
1XX 提示資訊 - 表示請求已被成功接收,繼續處理
2XX 成功 - 表示請求已被成功接收,理解,接受
3XX 重定向 - 要完成請求必須進行更進一步的處理
4XX 客戶端錯誤 - 請求有語法錯誤或請求無法實作
5XX 服務器端錯誤 - 服務器未能實作合法的請求
| 分類 | 分類描述 |
|---|---|
| 1 | 資訊,服務器收到請求,需要請求者繼續執行操作 |
| 2 | 成功,操作被成功接收并處理 |
| 3 | 重定向,需要進一步的操作以完成請求 |
| 4 | 客戶端錯誤,請求包含語法錯誤或無法完成請求 |
| 5** | 服務器錯誤,服務器在處理請求的程序中發生了錯誤 |
- 最常用的回應狀態碼
◆200 (OK): 找到了該資源,并且一切正常,
◆301(Moved Permanently): 客戶請求的檔案在其他地方,新的URL在Location頭中給出,瀏覽器應該自動地訪問新的URL,
◆302 (Found): 類似于301,但新的URL應該被視為臨時性的替代,而不是永久性的,
◆304 (NOT MODIFIED): 該資源在上次請求之后沒有任何修改,這通常用于瀏覽器的快取機制,
◆400 (Bad Request): 請求出現語法錯誤,
◆403 (FORBIDDEN): 客戶端未能獲得授權,這通常是在401之后輸入了不正確的用戶名或密碼,
◆404 (NOT FOUND): 在指定的位置不存在所申請的資源,
◆500 (Internal Server Error): 服務器遇到了意料不到的情況,不能完成客戶的請求
◆503 (Service Unavailable): 服務器由于維護或者負載過重未能應答,例如,Servlet可能在資料庫連接池已滿的情況下回傳503,服務器回傳503時可以提供一個Retry-After頭
看看一些常見的狀態碼
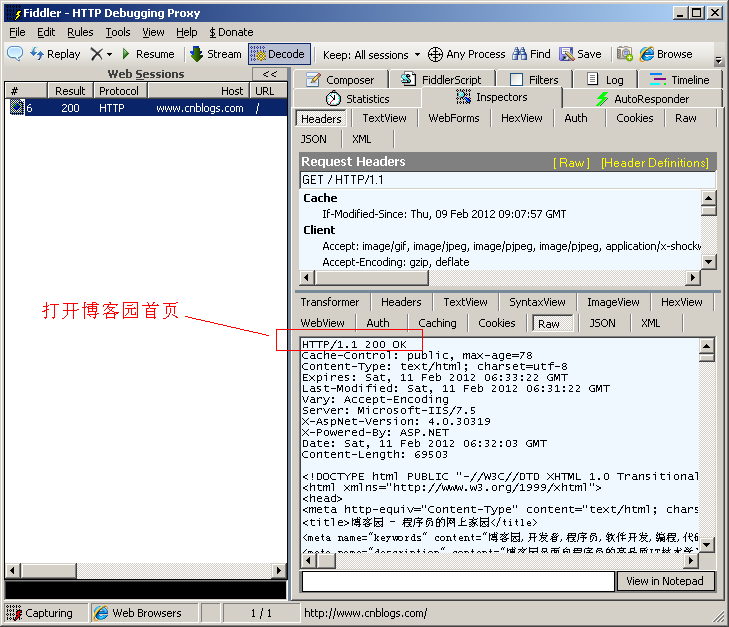
200 OK
最常見的就是成功回應狀態碼200了, 這表明該請求被成功地完成,所請求的資源發送回客戶端
如下圖, 打開博客園首頁
302 Found
重定向,新的URL會在response 中的Location中回傳,瀏覽器將會自動使用新的URL發出新的Request
例如在IE中輸入, http://www.google.com. HTTP服務器會回傳302, IE取到Response中Location header的新URL, 又重新發送了一個Request.
304 Not Modified
代表上次的檔案已經被快取了, 還可以繼續使用,
例如打開博客園首頁, 發現很多Response 的status code 都是304
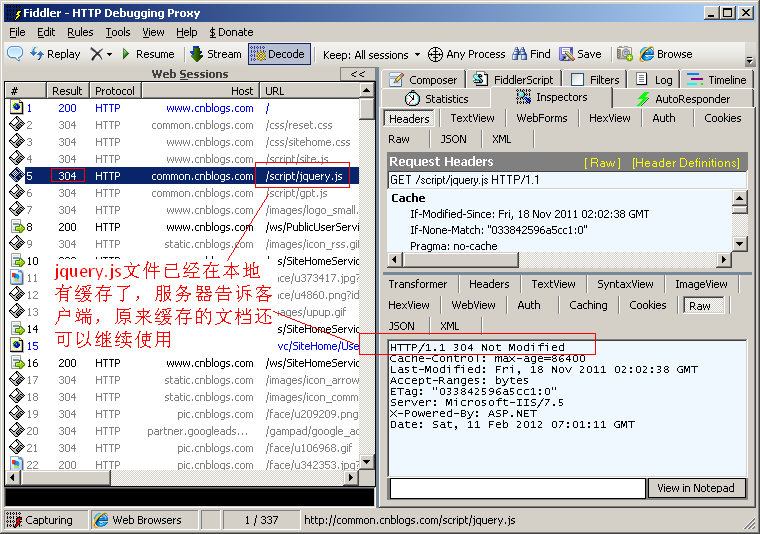
提示: 如果你不想使用本地快取可以用Ctrl+F5 強制重繪頁面
400 Bad Request 客戶端請求與語法錯誤,不能被服務器所理解
403 Forbidden 服務器收到請求,但是拒絕提供服務
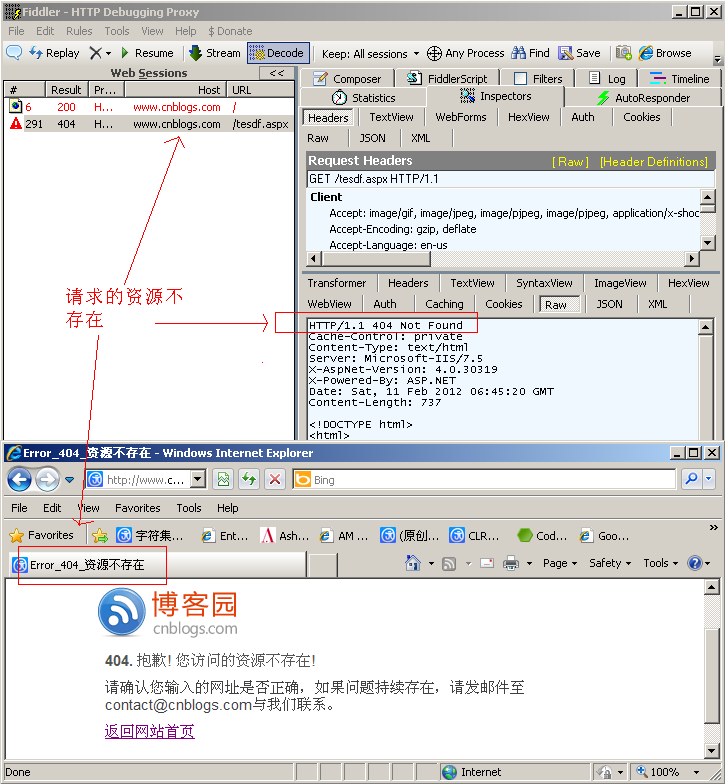
404 Not Found
請求資源不存在(輸錯了URL)
比如在IE中輸入一個錯誤的URL, http://www.cnblogs.com/tesdf.aspx
500 Internal Server Error 服務器發生了不可預期的錯誤
503 Server Unavailable 服務器當前不能處理客戶端的請求,一段時間后可能恢復正常
HTTP Request header
使用Fiddler 能很方便的查看Reques header, 點擊Inspectors tab ->Request tab-> headers 如下圖所示
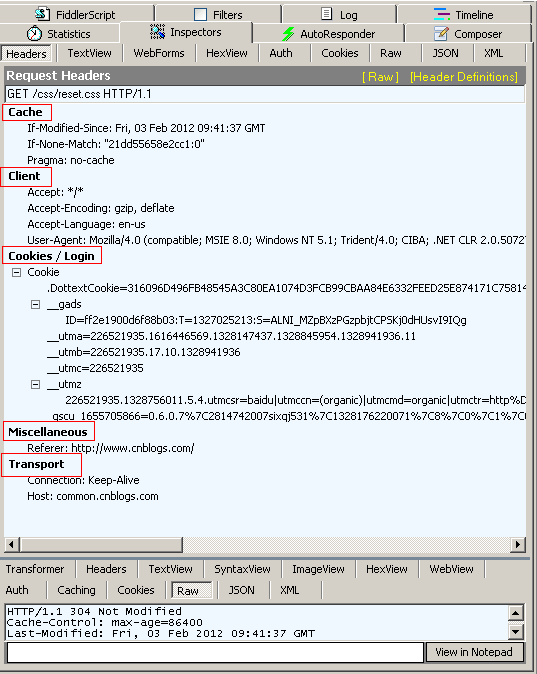
header 有很多,比較難以記憶,我們也按照Fiddler那樣把header 進行分類,這樣比較清晰也容易記憶,
>>>
Cache 頭域
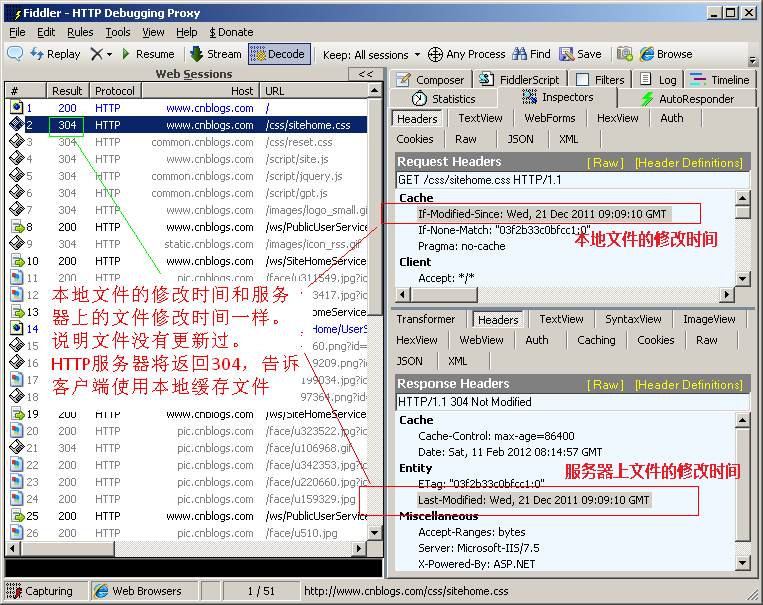
- If-Modified-Since
作用: 把瀏覽器端快取頁面的最后修改時間發送到服務器去,服務器會把這個時間與服務器上實際檔案的最后修改時間進行對比,如果時間一致,那么回傳304,客戶端就直接使用本地快取檔案,如果時間不一致,就會回傳200和新的檔案內容,客戶端接到之后,會丟棄舊檔案,把新檔案快取起來,并顯示在瀏覽器中.
例如:If-Modified-Since: Thu, 09 Feb 2012 09:07:57 GMT
實體如下圖
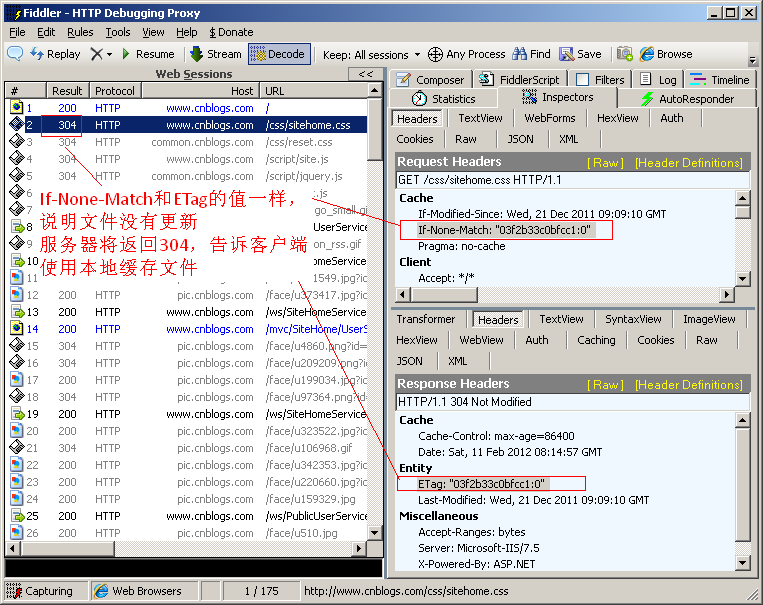
- If-None-Match
作用: If-None-Match和ETag一起作業,作業原理是在HTTP Response中添加ETag資訊, 當用戶再次請求該資源時,將在HTTP Request 中加入If-None-Match資訊(ETag的值),如果服務器驗證資源的ETag沒有改變(該資源沒有更新),將回傳一個304狀態告訴客戶端使用本地快取檔案,否則將回傳200狀態和新的資源和Etag. 使用這樣的機制將提高網站的性能
例如: If-None-Match: "03f2b33c0bfcc1:0"
實體如下圖
- Pragma
作用: 防止頁面被快取, 在HTTP/1.1版本中,它和Cache-Control:no-cache作用一模一樣
Pargma只有一個用法, 例如: Pragma: no-cache
注意: 在HTTP/1.0版本中,只實作了Pragema:no-cache, 沒有實作Cache-Control
- Cache-Control
作用: 這個是非常重要的規則, 這個用來指定Response-Request遵循的快取機制,各個指令含義如下
Cache-Control:Public 可以被任何快取所快取()
Cache-Control:Private 內容只快取到私有快取中
Cache-Control:no-cache 所有內容都不會被快取
還有其他的一些用法, 我沒搞懂其中的意思, 請大家參考其他的資料
Client 頭域
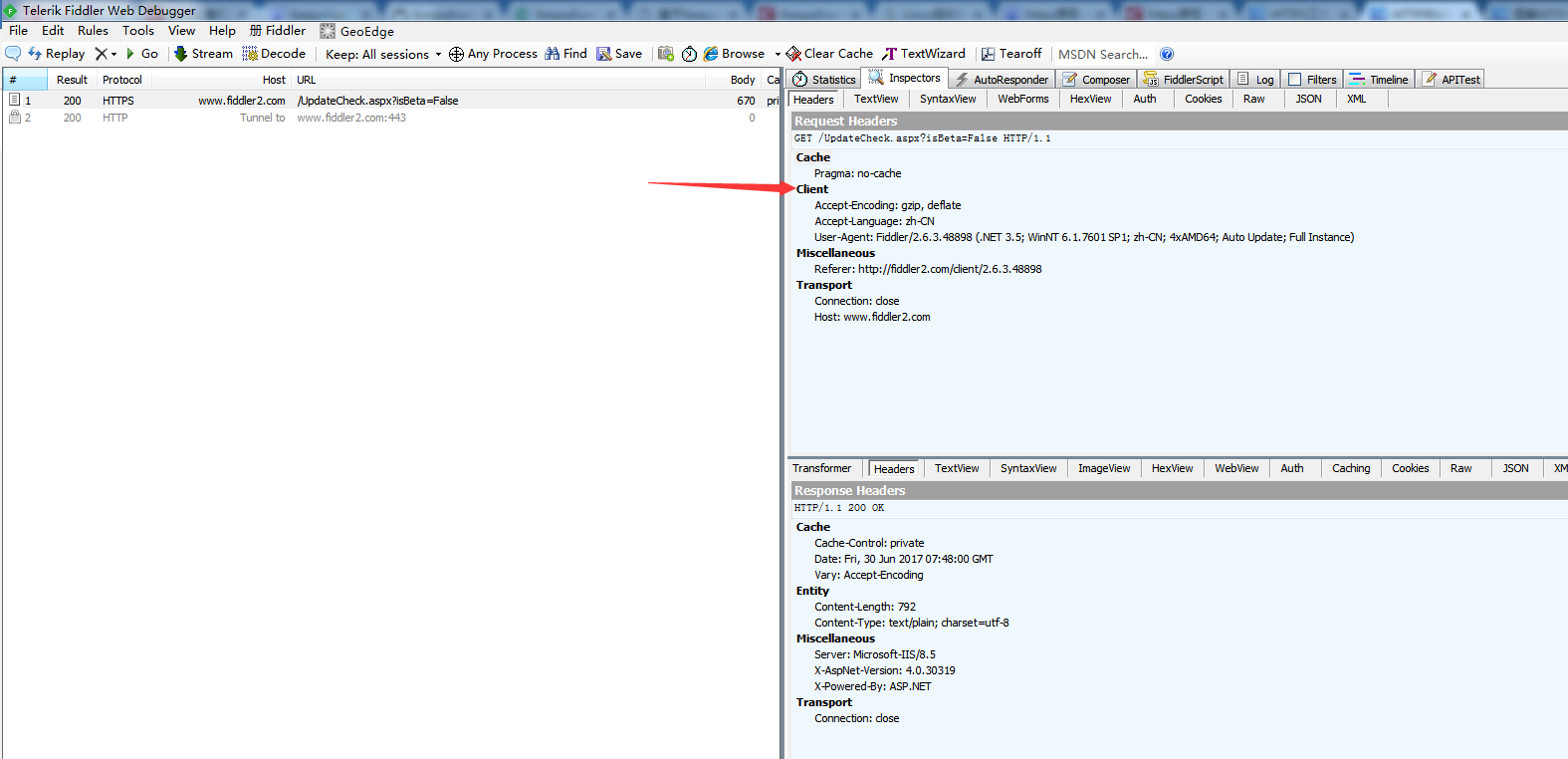
- Accept
作用: 瀏覽器端可以接受的媒體型別,
例如: Accept: text/html 代表瀏覽器可以接受服務器回發的型別為 text/html 也就是我們常說的html檔案,
如果服務器無法回傳text/html型別的資料,服務器應該回傳一個406錯誤(non acceptable)
通配符 代表任意型別
例如 Accept: /* 代表瀏覽器可以處理所有型別,(一般瀏覽器發給服務器都是發這個)
- Accept-Encoding:
作用: 瀏覽器申明自己接收的編碼方法,通常指定壓縮方法,是否支持壓縮,支持什么壓縮方法(gzip,deflate),(注意:這不是只字符編碼);
例如: Accept-Encoding: gzip, deflate
- Accept-Language
作用: 瀏覽器申明自己接收的語言,
語言跟字符集的區別:中文是語言,中文有多種字符集,比如big5,gb2312,gbk等等;
例如: Accept-Language: en-us
- User-Agent
作用:告訴HTTP服務器, 客戶端使用的作業系統和瀏覽器的名稱和版本.
我們上網登陸論壇的時候,往往會看到一些歡迎資訊,其中列出了你的作業系統的名稱和版本,你所使用的瀏覽器的名稱和版本,這往往讓很多人感到很神奇,實際上,服務器應用程式就是從User-Agent這個請求報頭域中獲取到這些資訊User-Agent請求報頭域允許客戶端將它的作業系統、瀏覽器和其它屬性告訴服務器,
例如:User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; CIBA; .NET CLR 2.0.50727; .NET CLR 3.0.4506.2152; .NET CLR 3.5.30729; .NET4.0C; InfoPath.2; .NET4.0E)
- Accept-Charset
作用:瀏覽器申明自己接收的字符集,這就是本文前面介紹的各種字符集和字符編碼,如gb2312,utf-8(通常我們說Charset包括了相應的字符編碼方案)
Cookie/Login 頭域
Cookie:
作用: 最重要的header, 將cookie的值發送給HTTP 服務器
Entity頭域
- Content-Length
作用:發送給HTTP服務器資料的長度,
例如: Content-Length: 38
- Content-Type
作用:
例如:Content-Type: application/x-www-form-urlencoded
Miscellaneous 頭域
- Referer:
作用: 提供了Request的背景關系資訊的服務器,告訴服務器我是從哪個鏈接過來的,比如從我主頁上鏈接到一個朋友那里,他的服務器就能夠從HTTP Referer中統計出每天有多少用戶點擊我主頁上的鏈接訪問他的網站,
例如: Referer:http://translate.google.cn/?hl=zh-cn&tab=wT
Transport 頭域
- Connection
例如: Connection: keep-alive 當一個網頁打開完成后,客戶端和服務器之間用于傳輸HTTP資料的TCP連接不會關閉,如果客戶端再次訪問這個服務器上的網頁,會繼續使用這一條已經建立的連接
例如: Connection: close 代表一個Request完成后,客戶端和服務器之間用于傳輸HTTP資料的TCP連接會關閉, 當客戶端再次發送Request,需要重新建立TCP連接,
- Host(發送請求時,該報頭域是必需的)
作用: 請求報頭域主要用于指定被請求資源的Internet主機和埠號,它通常從HTTP URL中提取出來的
例如: 我們在瀏覽器中輸入:http://www.guet.edu.cn/index.html
瀏覽器發送的請求訊息中,就會包含Host請求報頭域,如下:Host:http://www.guet.edu.cn 此處使用預設埠號80,若指定了埠號,則變成:Host:指定埠號
HTTP Response header
同樣使用Fiddler 查看Response header, 點擊Inspectors tab ->Response tab-> headers 如下圖所示
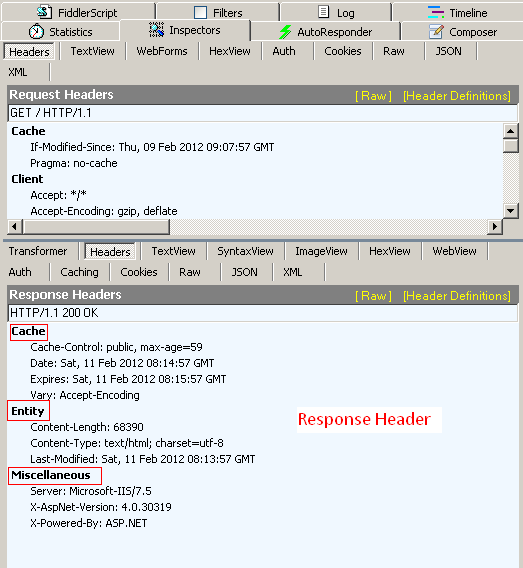
我們也按照Fiddler那樣把header 進行分類,這樣比較清晰也容易記憶,
Cache頭域
- Date
作用: 生成訊息的具體時間和日期
例如: Date: Sat, 11 Feb 2012 11:35:14 GMT
- Expires
作用: 瀏覽器會在指定過期時間內使用本地快取
例如: Expires: Tue, 08 Feb 2022 11:35:14 GMT
- Vary
作用:要了解 Vary 的作用,先得了解 HTTP 的內容協商機制,有時候,同一個 URL 可以提供多份不同的檔案,這就要求服務端和客戶端之間有一個選擇最合適版本的機制,這就是內容協商,
例如: Vary: Accept-Encoding
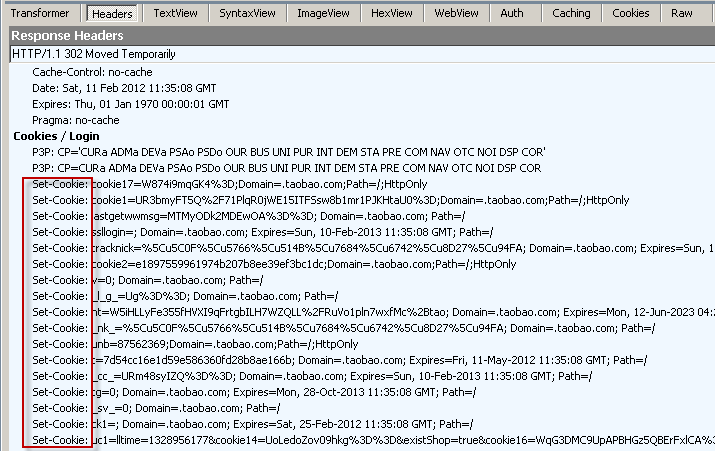
Cookie/Login 頭域
- P3P
作用: 用于跨域設定Cookie, 這樣可以解決iframe跨域訪問cookie的問題
例如: P3P: CP=CURa ADMa DEVa PSAo PSDo OUR BUS UNI PUR INT DEM STA PRE COM NAV OTC NOI DSP COR
- Set-Cookie
作用: 非常重要的header, 用于把cookie 發送到客戶端瀏覽器, 每一個寫入cookie都會生成一個Set-Cookie.
例如: Set-Cookie: sc=4c31523a; path=/; domain=.acookie.taobao.com
Entity頭域
- ETag
作用: 和If-None-Match 配合使用, (實體請看上節中If-None-Match的實體)
例如: ETag: "03f2b33c0bfcc1:0"
- Last-Modified:
作用: 用于指示資源的最后修改日期和時間,(實體請看上節的If-Modified-Since的實體)
例如: Last-Modified: Wed, 21 Dec 2011 09:09:10 GMT
- Content-Type
作用:WEB服務器告訴瀏覽器自己回應的物件的型別和字符集,
例如:
Content-Type: text/html; charset=utf-8
Content-Type:text/html;charset=GB2312
Content-Type: image/jpeg
- Content-Length
指明物體正文的長度,以位元組方式存盤的十進制數字來表示,在資料下行的程序中,Content-Length的方式要預先在服務器中快取所有資料,然后所有資料再一股腦兒地發給客戶端,
例如: Content-Length: 19847
- Content-Encoding
WEB服務器表明自己使用了什么壓縮方法(gzip,deflate)壓縮回應中的物件,
例如:Content-Encoding:gzip
- Content-Language
作用: WEB服務器告訴瀏覽器自己回應的物件的語言者
例如: Content-Language:da
Miscellaneous 頭域
- Server:
作用:指明HTTP服務器的軟體資訊
例如:Server: Microsoft-IIS/7.5
- X-AspNet-Version:
作用:如果網站是用ASP.NET開發的,這個header用來表示ASP.NET的版本
例如: X-AspNet-Version: 4.0.30319
- X-Powered-By:
作用:表示網站是用什么技術開發的
例如: X-Powered-By: ASP.NET
Transport頭域
- Connection
例如: Connection: keep-alive 當一個網頁打開完成后,客戶端和服務器之間用于傳輸HTTP資料的TCP連接不會關閉,如果客戶端再次訪問這個服務器上的網頁,會繼續使用這一條已經建立的連接
例如: Connection: close 代表一個Request完成后,客戶端和服務器之間用于傳輸HTTP資料的TCP連接會關閉, 當客戶端再次發送Request,需要重新建立TCP連接,
Location頭域
- Location
作用: 用于重定向一個新的位置, 包含新的URL地址
實體請看304狀態實體
HTTP協議是無狀態的和Connection: keep-alive的區別
無狀態是指協議對于事務處理沒有記憶能力,服務器不知道客戶端是什么狀態,從另一方面講,打開一個服務器上的網頁和你之前打開這個服務器上的網頁之間沒有任何聯系
HTTP是一個無狀態的面向連接的協議,無狀態不代表HTTP不能保持TCP連接,更不能代表HTTP使用的是UDP協議(無連接)
從HTTP/1.1起,默認都開啟了Keep-Alive,保持連接特性,簡單地說,當一個網頁打開完成后,客戶端和服務器之間用于傳輸HTTP資料的TCP連接不會關閉,如果客戶端再次訪問這個服務器上的網頁,會繼續使用這一條已經建立的連接
Keep-Alive不會永久保持連接,它有一個保持時間,可以在不同的服務器軟體(如Apache)中設定這個時間
|
IT入門 感謝關注 |
練習地址:www.520mg.com/it 0基礎python爬蟲系列教程
|

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/96749.html
標籤:AI
上一篇:04-爬蟲利器Fiddler