import PyPDF2
#分別建立pdfreader和PdfWriter
pdffile1=open('論文.pdf','rb')
pdffile2=open('paper.pdf','wb')
pdfreader=PyPDF2.PdfFileReader(pdffile1)
pdfwriter=PyPDF2.PdfFileWriter()
#獲取該pdf檔案的頁碼總數
numpages=pdfreader.numPages
#開始復制Page物件
for page in range(numpages):
pageobj=pdfreader.getPage(page)
pdfwriter.addPage(pageobj)
pdfwriter.write(pdffile2)
pdffile2.close()
pdffile1.close()
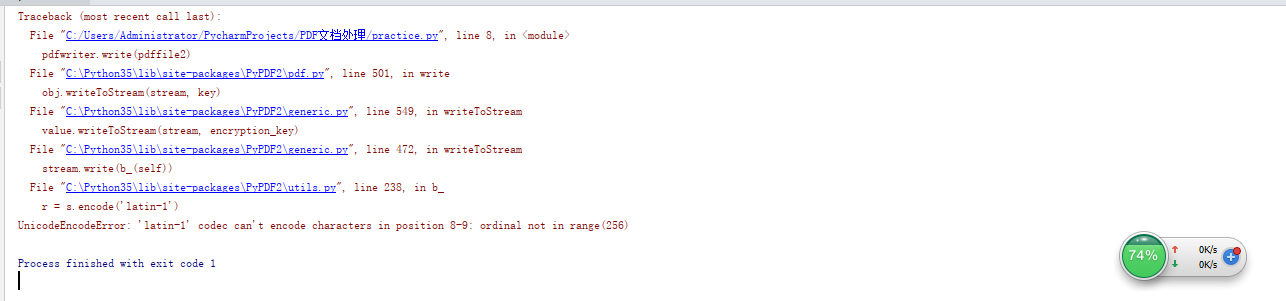
是這樣的,我想要拷貝這份pdf檔案,里面是中文字符,然后運行后就出現了這樣的報錯,想問各位前輩一下這種情況怎樣解決?
uj5u.com熱心網友回復:
pdf文字編碼問題 設定下對應編碼uj5u.com熱心網友回復:
您好,您是說修改pdf檔案的編碼嗎還是?
uj5u.com熱心網友回復:
我已經解決了,我直接修改了PyPDF2庫里的utils模塊的第238行的那個編碼,把latin-1改成了'utf-8'轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/98072.html
上一篇:優化代碼檔案