新手小白,嘗試爬58同城關于計算機類的崗位資訊,找了一份原始碼,最后href爬取了公司介紹的網址,我想改成崗位資訊的網址,就不成功了
爬取公司網址代碼:
import requests
from bs4 import BeautifulSoup
url = "https://dt.58.com/tech/pn{}"
def spider():
for i in range(5):
req = requests.get(url.format(str(i + 1)))
req.encoding = "utf-8"
soup = BeautifulSoup(req.text, "html.parser")
items = soup.select("li.job_item")
for item in items:
address = item.select("div.item_con span.address")[0].text#select()回傳的是list型別
name = item.select("div.item_con span.name")[0].text
href = item.select("div.item_con div.comp_name a.fl")[0].get("href")
print("%s\t%s\t%s"%(address, name,href))
if __name__ == '__main__':
spider()
爬取崗位網址代碼:
import requests
from bs4 import BeautifulSoup
url = "https://dt.58.com/tech/pn{}"
def spider():
for i in range(5):
req = requests.get(url.format(str(i + 1)))
req.encoding = "utf-8"
soup = BeautifulSoup(req.text, "html.parser")
items = soup.select("li.job_item")
for item in items:
address = item.select("div.item_con span.address")[0].text
name = item.select("div.item_con span.name")[0].text
href = item.select("div.item_con div.job_name clearfix a")[0].get("href")
print("%s\t%s\t%s"%(address, name,href))
if __name__ == '__main__':
spider()
這是爬取網址的源代碼
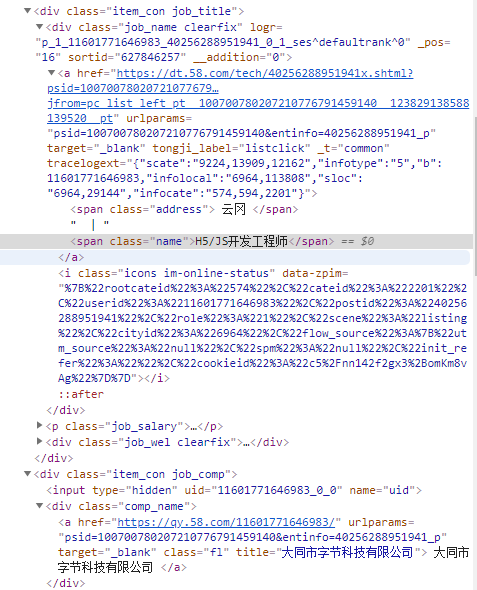
順便問一下能通過對爬取到的崗位資訊網址再進行第二級網頁的爬取,爬崗位的職位介紹嗎
謝謝各位大佬了(第一次發帖問,有啥不對的請指教)
uj5u.com熱心網友回復:
爬取崗位資訊網址代碼錯位為IndexError: list index out of range但是兩個不都是網址嗎?是因為崗位資訊網址太長了嗎?
uj5u.com熱心網友回復:
二級頁面爬取,再添加一個for回圈即可(在崗位資訊下面)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/98074.html