使用 Databricks 的 Apache Spark 中的流式轉換通常用 Scala 或 Python 編碼。但是,有人可以告訴我是否也可以在 Delta 上的 SQL 中撰寫 Streaming 代碼?
例如,對于以下示例代碼,使用 PySpark 進行結構化流式傳輸,您能告訴我 spark.SQL 中的等價物嗎?
simpleTransform = streaming.withColumn(" stairs", expr(" gt like '% stairs%'"))\
.where(" stairs")\
.where(" gt is not null")\
.select(" gt", "model", "arrival_time", "creation_time")\
.writeStream\
.queryName(" simple_transform")\
.format(" memory")\
.outputMode("update")\
.start()
uj5u.com熱心網友回復:
您可以將該流式 DF 注冊為臨時視圖,并對其執行查詢。例如(rate為了簡單起見,使用source ):
df=spark.readStream.format("rate").load()
df.createOrReplaceTempView("my_stream")
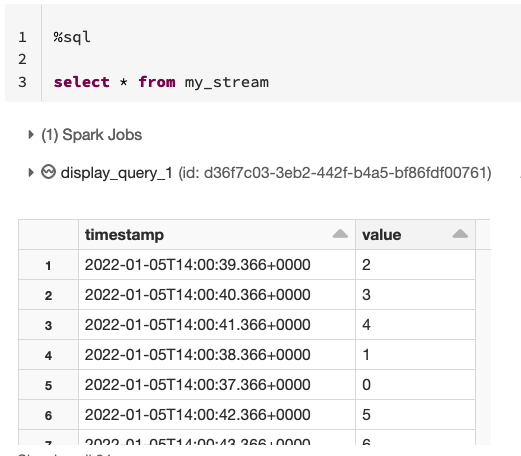
那么您可以直接在該視圖上執行 SQL 查詢,例如select * from my_stream:
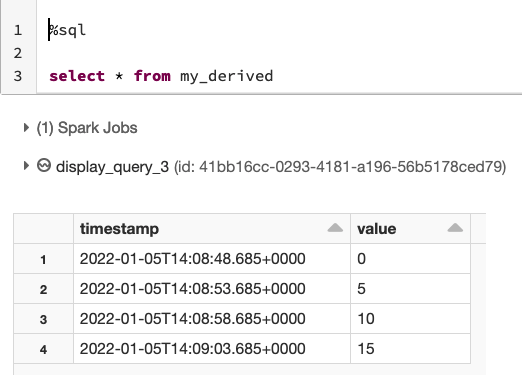
或者您可以創建另一個視圖,應用您需要的任何轉換。例如,如果我們使用以下 SQL 陳述句,我們只能選擇每 5 個值:
create or replace temp view my_derived as
select * from my_stream where (value % 5) == 0
然后使用以下命令查詢該視圖select * from my_derived:
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/405139.html
標籤: