Optimism Rollup是目前最流行的以太坊L2解決方案,本文將解釋Optimism Rollup每個設計決策背后的動機,剖析Optimism的系統實作,并提供指向每個分析組件的相應代碼的鏈接,適用于希望了解Optimism解決方案的作業原理并評估所提議系統的性能和安全性的開發人員,
區塊鏈開發教程鏈接:以太坊 | 位元幣 | EOS | Tendermint | Hyperledger Fabric | Omni/USDT | Ripple | Tron
1、軟體重用原則在Optimism Rollup中的重要性
以太坊已經圍繞其開發者生態系統發展了護城河,開發人員的技術堆疊包括:
- Solidity/ Vyper:這是兩種最流行的智能合約編程語言,有很多工具鏈圍繞它們構建,例如
Ethers、Hardhat、 dapp、slither等, - 以太坊虛擬機:最流行的區塊鏈虛擬機,其內部設計比任何其他區塊鏈VM都要好得多,
- Go-ethereum:主流以太坊協議實作,采用率 > 75%,經過了廣泛的測驗,
由于Optimism Rollup將以太坊作為其第1層,因此如果我們可以無需修改即可重用現有工具,那就太好了,這將改善開發人員的體驗,因為開發人員無需學習新技術,雖然已經多次提出,但是我想強調軟體重用的另一個含義:安全性,
2、Optimistic虛擬機
Optimism Rollup依賴于使用欺詐證明來防止發生無效的狀態轉換,這需要在以太坊上執行Optimsim交易,簡而言之,如果交易結果存在爭議,例如修改了Alice的ETH余額,Alice將嘗試在以太坊上重放該確切的交易,以證明那里的結果是正確的,但是,如果某些EVM操作碼依賴于系統范圍內的引數,這些引數可能隨時都會改變,例如加載或存盤狀態或獲取當前時間戳,則它們在L1和L2上的行為將不同,
因此,Optimsim的第一個技術,就是處理L1上的L2爭端的機制,該機制保證可以重現在L1上執行L2事務時存在的任何“背景關系”,并且在理想情況下不引入太多開銷,
目標是實作一個沙盒環境,可確保在L1和L2之間確定性地執行智能合約,
Optimism的解決方案是Optimistic虛擬機,OVM是通過將背景關系相關的EVM操作碼替換為其對應的OVM操作碼來實作的,
一個簡單的例子是:
- L2交易呼叫TIMESTAMP操作碼,例如回傳1610889676
- 一個小時后,由于某種原因,交易都必須在以太坊L1上重放
- 如果要在EVM中正常執行該交易,則TIMESTAMP操作碼將回傳1610889676 +3600,這不是我們希望的,因為這將導致交易執行背景關系的變化,
- 在OVM中,在L2上執行交易時,TIMESTAMP操作碼將替換為ovmTIMESTAMP,因此將顯示正確值的操作碼,
所有與背景關系相關的EVM操作碼在OVM核心合約在ExecutionManager中都有一個對應的ovm{OPCODE},合約的執行是從EM的入口點run函式開始的,這些操作碼也已修改為可以與可插拔狀態資料庫互動,其作用我們將在“欺詐證明”部分中進行介紹,
某些在OVM中“無意義”的操作碼會通過Optimism的SafetyChecker合約禁用,Optimism合約采用靜態分析技術,可以有效地判斷合約是否OVM安全并回傳1或0,
請查閱附錄部分以了解每個被修改/禁用的EVM操作碼,
Optimism Rollup看起來像這樣:
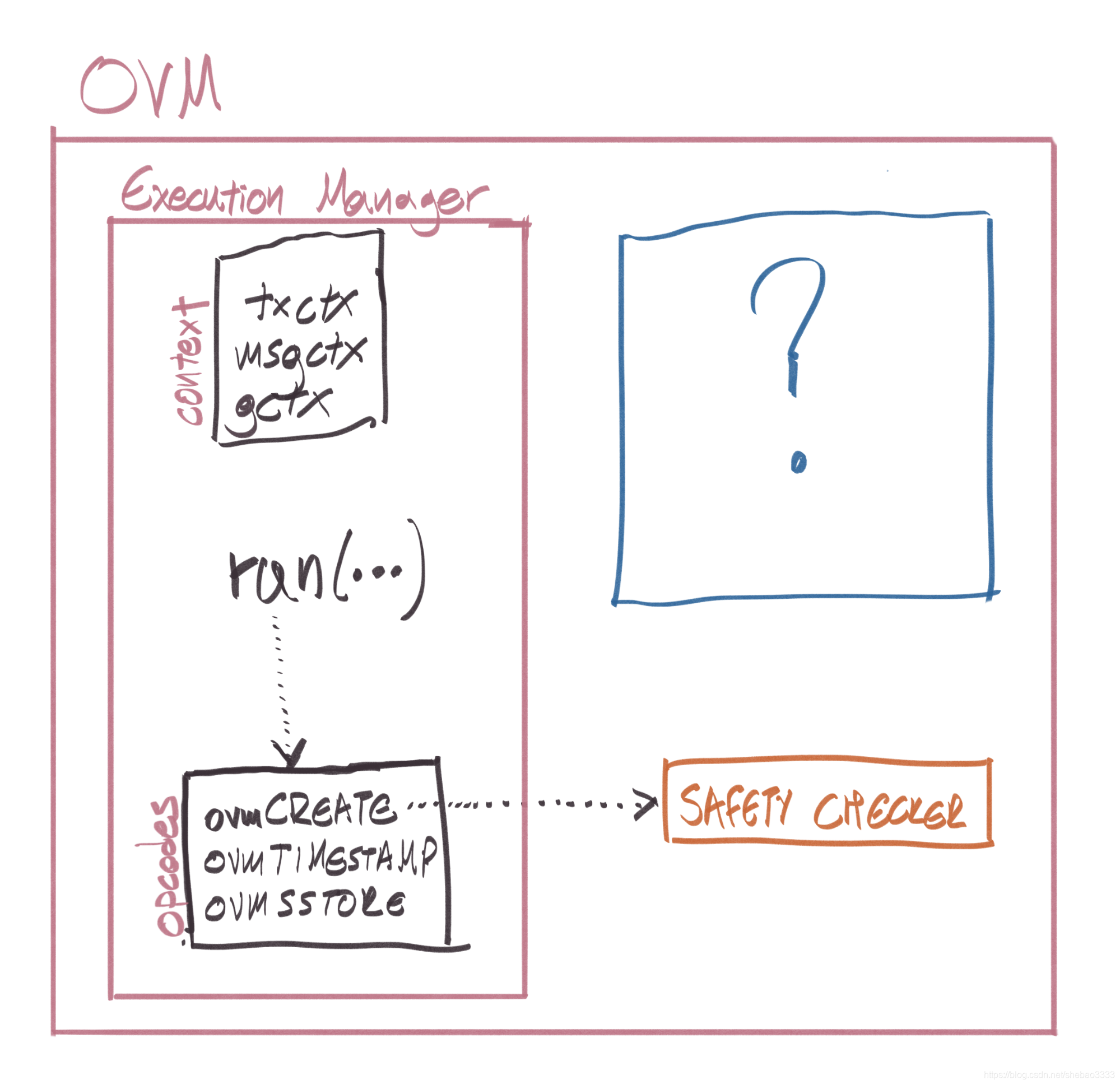
上圖中問號標注的組件將在下面的欺詐證明部分說明,但在此之前,我們需要進一步解釋一些基礎知識,
3、Optimisitic Solidity編譯器
現在我們有了OVM沙箱,接下來要做的就是將智能合約編譯為OVM位元組碼,下面是一些可選的方案:
- 發明一種新的可以編譯為OVM的智能合約語言:這個思路很容易被放棄,因為它需要從頭開始重新做所有事情,而且
我們已經就這一點達成一致,即盡可能重用已有的技術堆疊, - 將EVM位元組碼轉換為OVM位元組碼:已嘗試但由于復雜性而被放棄,
- 修改Solidity和Vyper編譯器以生成OVM位元組碼,
Optimism當前使用的方法是第三種,Optimsim更改了socl大約500行代碼,
Solidity編譯器的作業原理是將Solidity轉換為Yul,然后轉換為EVM指令,最后轉換為位元組碼,Optimism所做的更改既簡單又優雅:對于每個操作碼,在編譯為EVM匯編后,如有必要,嘗試以ovm變體“重寫”它(如果被禁止則拋出錯誤),
解釋起來有點復雜,下面讓我們比較一個簡單合約的EVM和OVM位元組碼:

用solc編譯一下:
$ solc C.sol --bin-runtime --optimize --optimize-runs 200
6080604052348015600f57600080fd5b506004361060285760003560e01c8063c298557814602d575b600080fd5b60336035565b005b60008054600101905556fea264697066735822122001fa42ea2b3ac80487c9556a210c5bbbbc1b849ea597dd6c99fafbc988e2a9a164736f6c634300060c0033
我們可以反匯編此代碼看一下得到的匯編代碼,括號內表示Program Counter:
...
[025] 35 CALLDATALOAD
...
[030] 63 PUSH4 0xc2985578 // id("foo()")
[035] 14 EQ
[036] 60 PUSH1 0x2d // int: 45
[038] 57 JUMPI // jump to PC 45
...
[045] 60 PUSH1 0x33
[047] 60 PUSH1 0x35 // int: 53
[049] 56 JUMP // jump to PC 53
...
[053] 60 PUSH1 0x00
[055] 80 DUP1
[056] 54 SLOAD // load the 0th storage slot
[057] 60 PUSH1 0x01
[059] 01 ADD // add 1 to it
[060] 90 SWAP1
[061] 55 SSTORE // store it back
[062] 56 JUMP
...
上述匯編代碼的意思是,如果calldata匹配函式foo()的選擇器,則使用SLOAD操作碼載入0x00處的存盤變數,加上0x01,最后將結果使用SSTORE操作碼存回去,聽起來不錯!
在OVM中看起來如何?首先用修改后的solc編譯:
$ osolc C.sol --bin-runtime --optimize --optimize-runs 200
60806040523480156100195760008061001661006e565b50505b50600436106100345760003560e01c8063c298557814610042575b60008061003f61006e565b50505b61004a61004c565b005b6001600080828261005b6100d9565b019250508190610069610134565b505050565b632a2a7adb598160e01b8152600481016020815285602082015260005b868110156100a657808601518282016040015260200161008b565b506020828760640184336000905af158601d01573d60011458600c01573d6000803e3d621234565260ea61109c52505050565b6303daa959598160e01b8152836004820152602081602483336000905af158601d01573d60011458600c01573d6000803e3d621234565260ea61109c528051935060005b60408110156100695760008282015260200161011d565b6322bd64c0598160e01b8152836004820152846024820152600081604483336000905af158601d01573d60011458600c01573d6000803e3d621234565260ea61109c5260008152602061011d56
得到的位元組碼更長了,讓我們再次反匯編一下,看看有什么變化:
...
[036] 35 CALLDATALOAD
...
[041] 63 PUSH4 0xc2985578 // id("foo()")
[046] 14 EQ
[047] 61 PUSH2 0x0042
[050] 57 JUMPI // jump to PC 66
...
[066] 61 PUSH2 0x004a
[069] 61 PUSH2 0x004c // int: 76
[072] 56 JUMP // jump to PC 76
這一部分還是檢查是否匹配指定的函式選擇器,讓我們看看之后會發生什么,
...
[076] 60 PUSH1 0x01 // Push 1 to the stack (to be used for the addition later)
[078] 60 PUSH1 0x00
[080] 80 DUP1
[081] 82 DUP3
[082] 82 DUP3
[083] 61 PUSH2 0x005b
[086] 61 PUSH2 0x00d9 (int: 217)
[089] 56 JUMP // jump to PC 217
...
[217] 63 PUSH4 0x03daa959 // <---| id("ovmSLOAD(bytes32)")
[222] 59 MSIZE // |
[223] 81 DUP2 // |
[224] 60 PUSH1 0xe0 // |
[226] 1b SHL // |
[227] 81 DUP2 // |
[228] 52 MSTORE // |
[229] 83 DUP4 // |
[230] 60 PUSH1 0x04 // | CALL to the CALLER's ovmSLOAD
[232] 82 DUP3 // |
[233] 01 ADD // |
[234] 52 MSTORE // |
[235] 60 PUSH1 0x20 // |
[237] 81 DUP2 // |
[238] 60 PUSH1 0x24 // |
[240] 83 DUP4 // |
[241] 33 CALLER // |
[242] 60 PUSH1 0x00 // |
[244] 90 SWAP1 // |
[245] 5a GAS // |
[246] f1 CALL // <---|
[247] 58 PC // <---|
[248] 60 PUSH1 0x1d // |
[250] 01 ADD // |
[251] 57 JUMPI // |
[252] 3d RETURNDATASIZE // |
[253] 60 PUSH1 0x01 // |
[255] 14 EQ // |
[256] 58 PC // |
[257] 60 PUSH1 0x0c // |
[259] 01 ADD // |
[260] 57 JUMPI // | Handle the returned data
[261] 3d RETURNDATASIZE // |
[262] 60 PUSH1 0x00 // |
[264] 80 DUP1 // |
[265] 3e RETURNDATACOPY // |
[266] 3d RETURNDATASIZE // |
[267] 62 PUSH3 0x123456 // |
[271] 52 MSTORE // |
[272] 60 PUSH1 0xea // |
[274] 61 PUSH2 0x109c // |
[277] 52 MSTORE // <---|
上面代碼包含很多操作,要點在于這里不是使用SLOAD操作碼,而是構造一個堆疊以便執行CALL操作碼,呼叫的接收者通過CALLER操作碼被壓入堆疊,每一個呼叫都是來自EM,因此實際上CALLER是呼叫EM的有效方法,呼叫的資料以ovmSLOAD(bytes32)函式的選擇器開頭,接下來是引數(在這個示例中,就是占用32位元組的字),之后,將處理回傳的資料并將其添加到記憶體中,
讓我們繼續:
...
[297] 82 DUP3
[298] 01 ADD // Adds the 3rd item on the stack to the ovmSLOAD value
[299] 52 MSTORE
[308] 63 PUSH4 0x22bd64c0 // <---| id("ovmSSTORE(bytes32,bytes32)")
[313] 59 MSIZE // |
[314] 81 DUP2 // |
[315] 60 PUSH1 0xe0 // |
[317] 1b SHL // |
[318] 81 DUP2 // |
[319] 52 MSTORE // |
[320] 83 DUP4 // |
[321] 60 PUSH1 0x04 // |
[323] 82 DUP3 // |
[324] 01 ADD // | CALL to the CALLER's ovmSSTORE
[325] 52 MSTORE // | (RETURNDATA handling is omited
[326] 84 DUP5 // | because it is identical to ovmSSLOAD)
[327] 60 PUSH1 0x24 // |
[329] 82 DUP3 // |
[330] 01 ADD // |
[331] 52 MSTORE // |
[332] 60 PUSH1 0x00 // |
[334] 81 DUP2 // |
[335] 60 PUSH1 0x44 // |
[337] 83 DUP4 // |
[338] 33 CALLER // |
[339] 60 PUSH1 0x00 // |
[341] 90 SWAP1 // |
[342] 5a GAS // |
[343] f1 CALL // <---|
...
類似于將SLOAD調整到外部呼叫ovmSLOAD,SSTORE也調整到外部呼叫ovmSSTORE,呼叫的資料不同,因為ovmSSTORE需要兩個引數,即存盤插槽和要存盤的值,下面是兩者的比較:
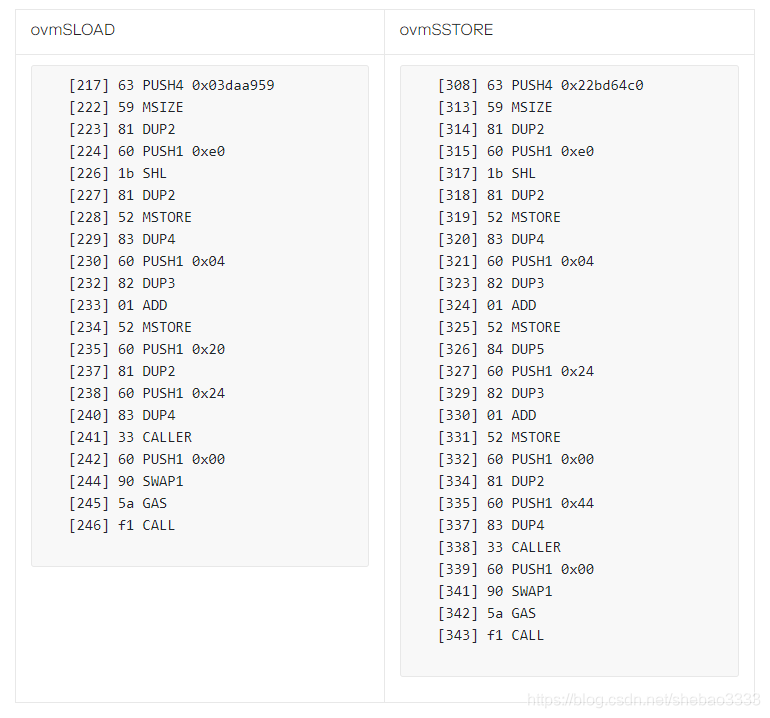
實際上,我們先呼叫Execution Manager的ovmSLOAD方法,然后再呼叫其ovmSTORE方法,而不是SLOAD和SSTORE,
通過比較EVM與OVM的執行(我們僅顯示執行的SLOAD一部分),我們可以看到通過Execution Manager進行的虛擬化:
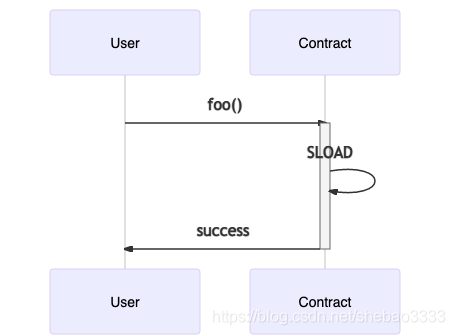
這種虛擬化技術有一個“陷阱”:
會導致更快達到合約大小上限 :通常,以太坊合約的位元組碼最大24KB ,使用Optimistic Solidity Compiler編譯的合約最終比原來大,這意味著必須重構接近24KB限制的合約,以便其OVM大小仍適合24KB限制,因為它們需要在以太坊主網上執行,
4、Optimistic Geth
以太坊最流行的實作是go-ethereum(即geth),讓我們看看通常如何在Geth中執行交易,
在每個塊上,呼叫狀態處理器的Process方法,該方法對每個交易執行ApplyTransaction方法,在內部,交易被轉換為
訊息,訊息被應用于當前狀態,最后將新產生的狀態存盤回資料庫中,
此核心資料流在Optimistic Geth上保持不變,但進行了一些修改以保持交易“對OVM友好”:
修改1:通過Sequencer入口點的OVM訊息
交易被轉換為OVM訊息,由于除去了訊息的簽名,因此訊息資料被修改為包括交易簽名以及原始交易的其余欄位,to欄位將替換為“Sequencer入口點”合約的地址,這樣做是為了使交易格式緊湊,因為它將被發布到以太坊,并且我們已經確定,越緊湊伸縮性就越好,
修改2:通過執行管理器的OVM沙箱
為了通過OVM沙箱運行交易,必須將它們發送到Execution Manager的run 功能,不要求用戶僅提交符合該限制的交易,所有訊息都被修改為在內部發送到Execution Manager,這里很簡單:訊息的to欄位被替換為執行管理器的地址,并且訊息的原始資料被打包為引數傳入run,
這可能有點不直觀,因此我們提供了代碼以給出一個具體示例,
修改3:攔截對狀態管理器的呼叫
StateManager是一個特殊的合約,在Optimistic Geth 上并不存在,僅在欺詐證明期間部署它,細心的讀者會注意到當打包引數以進行run呼叫時,Optimism的geth還將打包一個硬編碼的State Manager地址,這就是最終被用作任何ovmSSTORE或ovmSLOAD(或類似)呼叫的最終目的地的原因,在L2上運行時,以State Manager合約為目標的所有訊息都將被攔截,并且它們被連接為直接與Geth的StateDB對話(或不執行任何操作),
對于尋求整體代碼更改的人們來說,最好的方法是搜索UsingOVM并比較geth 1.9.10的差異,
修改4:基于epoch的批次而不是塊
OVM沒有塊,它僅維護交易的有序串列,因此,沒有區塊gas限制的概念;取而代之的是,根據時間段(稱為epoch)限制總的gas消耗率,在執行交易之前,要檢查是否需要啟動一個新的epoch,在執行之后,將其gas小號添加到該epoch所使用的累積gas用量上,對于Equenecer提交的交易和“ L1至L2”交易,每個epoch都有單獨的gas限制,任何超過gas限值的交易將提前回傳,這意味著操作員可以在一個鏈上批次中發布多個具有不同時間戳的交易(時間戳由Sequencer定義,但有一些限制,我們將在“資料可用性批處理”部分中說明),
修改5:Rollup同步服務
該同步服務是一個新的行程運行,它與“正常” GETH同時運行,Rollup同步服務負責監視以太坊日志,對其進行處理,并通過geth的worker注入要在L2狀態下應用的相應L2交易,
5、Optimistic Rollup
Optimistic Rollup的主要特性包括:
- OVM作為其運行時/狀態遷移函式
- 擁有單個Sequencer的Optimistic Geth作為L2客戶端
- 在以太坊上部署的Solidity智能合約用于:
- 資料可用性
- 爭議解決和欺詐證明,我們將深入研究實作資料可用性層的智能合約,并探索端到端的欺詐證明流程,
資料可用性批次
如前所述,交易資料被壓縮,然后發送到L2上的Sequencer Entrypoint合約,然后,Sequencer負責“匯總”這些交易,并在以太坊上發布資料,提供資料可用性,以便即使Sequencer消失了,也可以啟動新的Sequencer以從中斷的地方繼續,
依靠以太坊實作該邏輯的智能合約稱為權威交易鏈(CTC:Canonical Transaction Chain),權威交易鏈是一個追加型日志,它代表Rollup鏈的“正式歷史”(所有交易以及其順序),交易可以由Sequencer等提交給CTC,為了保留L1的抗審查能力,任何人都可以將交易提交到此佇列,并在一定滯后期之后將其包括在CTC中,
CTC為每批發布的L2交易提供資料可用性,可以通過兩種方式創建批處理:
- 預計每隔幾秒鐘,Sequencer就會檢查接收到的新交易,將它們分批匯總,以及所需的任何其他元資料,然后,他們 利用appendSequencerBatch將該資料發布到以太坊,這是由批處理提交者服務自動完成的,
- 當Sequencer審查其用戶或當用戶執行從L1到L2的交易,用戶需要呼叫enqueue和appendQueueBatch,這會強制在CTC中 包含交易
這里的一個極端情況是:如果Sequencer廣播了一個批次,則用戶可以強制包含涉及與該批次沖突的狀態的交易,從而可能使該批次的某些交易無效,為了避免這種情況,我們引入了時間延遲,在此延遲之后可以由非Sequencer帳戶將批處理追加到佇列中,對此進行考慮的另一種方法是,給利用appendeSequencerBatcher 添加的交易一個“寬限期”,否則用戶使用appendQueueBatch,
鑒于大多數交易預計將通過Sequencer提交,因此有必要深入研究批處理結構和執行流程,
你可能會注意到,appendSequencerBatch沒有任何引數,批次以緊密打包的格式提交,而使用ABI編碼和解碼則效率要低得多,它使用行內匯編來對calldata進行切片,并以預期的格式將其解壓縮,
一個批次由以下部分組成:
- 批次頭
- 批處理背景關系(> = 1,請注意:此背景關系與我們在上面的“ OVM”部分中提到的訊息/交易/全域背景關系不同)
- 交易(> = 1)
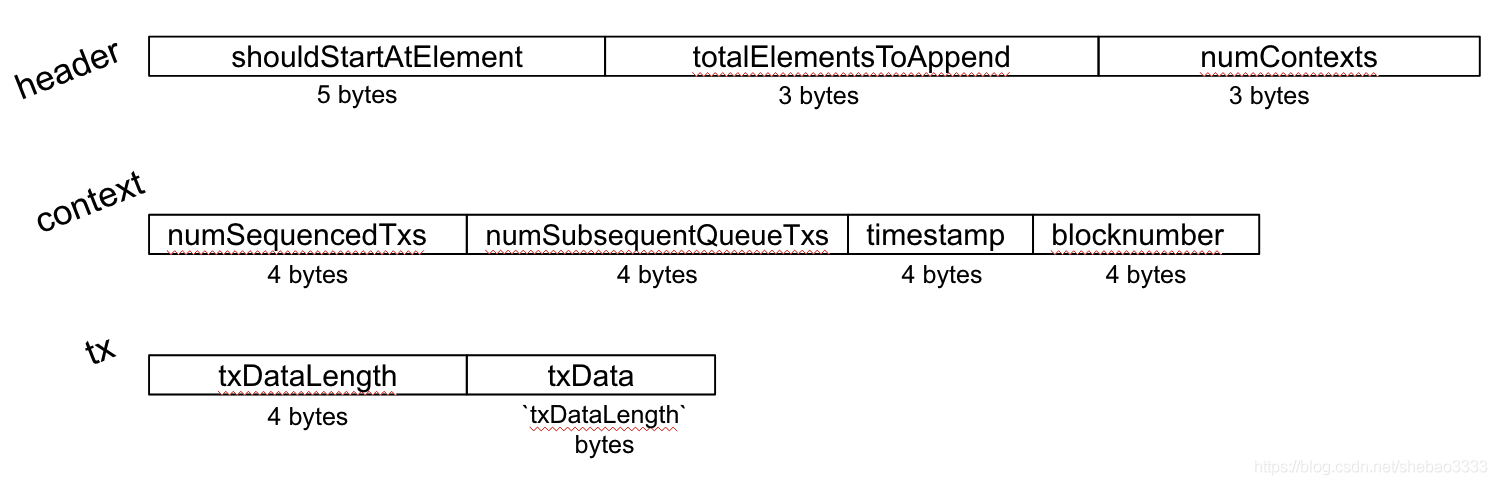
批次頭指定了背景關系的數量,因此序列化的批處理看起來像是 [header, context1, context2, …, tx1, tx2, … ]
該函式繼續執行以下兩項操作:
- 驗證所有與背景關系相關的不變數是否適用
- 根據已發布的交易資料創建默克爾樹
如果通過了背景關系驗證,則該批次將轉換為OVM鏈批次頭,然后將其存盤在CTC中,
存盤的批次頭包含該批次的merkle根,這意味著證明已包含交易是提供針對針對CTC中存盤的merkle根進行驗證的merkle證明的簡單問題,
這里的自然問題是:這似乎太復雜了!為什么需要背景關系?
背景關系對于Sequencer來說是必要的,以便知道是否應在已排序交易之前或之后執行已排隊的交易,讓我們來看一個例子:
在時間T1,Sequencer已接收到2個交易,它們將包括在其批次中,在T2(> T1)用戶也排隊的交易時,將它添加到L1到L2交易佇列(但不將其添加到批次!),在T2,Sequencer又接收到1個交易,另外2個交易也入佇列,換句話說,待處理交易的批處理看起來像:
[(sequencer, T1), (sequencer, T1), (queue, T2), (sequencer, T2), (queue, T3), (queue, T4)]
為了保持時間戳和塊號資訊,同時又保持序列化格式的緊湊性,我們使用了“背景關系”,即Sequencer和排隊交易之間的共享資訊集合,背景關系必須嚴格增加塊數和時間戳,在背景關系中,所有Sequencer交易共享相同的塊號和時間戳,對于“佇列交易”,將時間戳和塊號設定為呼叫佇列時的值,在這種情況下,該批交易的背景關系為:
[{ numSequencedTransactions: 2, numSubsequentQueueTransactions: 1, timestamp: T1}, {numSequencedTransactions: 1, numSubsequentQueueTransactions: 2, timestamp: T2}]
狀態承諾
在以太坊中,每個交易都會導致對狀態以及全域狀態根的修改,通過在某個區塊提供狀態根并通過默克爾證明來證明某個帳戶在某個區塊擁有一些ETH,以證明該賬戶的狀態與所宣告的值匹配,因為每個塊包含多個交易,并且我們只能訪問狀態根,所以這意味著我們只能在執行整個塊后才宣告狀態,
一段歷史:
在EIP98和Byzantium分叉之前,以太坊交易在每次執行后產生中間狀態根,這些根通過交易收據提供給用戶洗掉中間狀態根能夠提高性能,雖然有一點小缺陷,因此很快就采用了它,EIP PR658中提供的其他動機解決了該問題:收據的PostState欄位(指示與tx執行后的狀態相對應的狀態根)被布爾狀態欄位(指示交易的成功狀態)替換,
事實證明,警告并非無關緊要,EIP98寫道:
所做的更改確實意味著,如果礦工創建了一個區塊,其中一個狀態轉換的處理不正確,那么就不可能針對該交易 提供欺詐證明;相反,欺詐證明必須包含整個區塊,
此更改的含義是,如果一個區塊有1000個交易,并且你在第988個交易中檢測到欺詐,則在實際執行你感興趣的交易之前,需要在前一個區塊的狀態之上運行987個交易,這會使欺詐證明效率極低,以太坊本身沒有欺詐證明,所以沒關系!
另一方面,Optimism的欺詐證據是至關重要的,在前面,我們提到Optimism沒有區塊,那只是個小謊言:Optimism有區塊,但是每個區塊只有1個交易,我們稱之為“微區塊”,由于每個微塊包含1個交易,因此每個塊的狀態根實際上是單個交易產生的狀態根,烏拉!我們已經重新引入了中間狀態根,而不必對協議進行任何重大更改,當然,由于微塊在技術上仍然是塊并且包含冗余的其他資訊,因此當前當然具有恒定的性能開銷,但是這種冗余可以在將來洗掉(例如,使所有微塊都具有0x0作為塊哈希,并且僅填充RPC中的修剪欄位以便向后兼容),
現在,我們可以介紹狀態承諾鏈(SCC:State Commitment Chain),SCC包含狀態根串列,在樂觀情況下,該串列對應于針對先前狀態在CTC中應用每個交易的結果,如果不是這種情況,則欺詐驗證程序將洗掉無效的狀態根,然后洗掉所有無效的狀態根,以便可以為這些交易提出正確的狀態根,
與CTC相反,SCC沒有任何酷炫的資料表示形式,它的目的很簡單:給定狀態根串列,它會對其進行存盤并保存批處理中包含的中間狀態根的merkle根,以供以后通過appendStateBatch用作欺詐證明,
欺詐證明
既然我們了解了OVM的基本概念以及將其狀態錨定在以太坊上的支持功能,那么讓我們深入探討爭端解決程式,也就是欺詐證明,
Sequencer執行3件事:
- 接收用戶提交的交易
- 批量匯總這些交易并將其發布在權威交易鏈中
- 在狀態承諾鏈中將交易產生的中間狀態根發布為狀態批,
例如,如果在CTC中發布了8個交易,則對于每個狀態從S1到S8的轉換,在SCC中都會有8個狀態根,
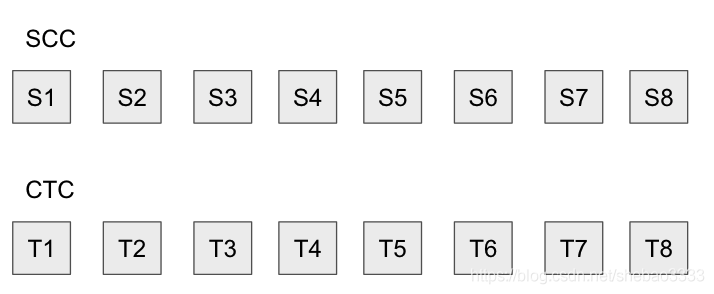
但是,如果Sequencer是惡意的,他們可以在狀態Trie中將其帳戶余額設定為1000萬個ETH,這顯然是非法的操作,從而使狀態根及其后面的所有狀態根均無效,他們可以通過發布看起來像這樣的資料來做到這一點:
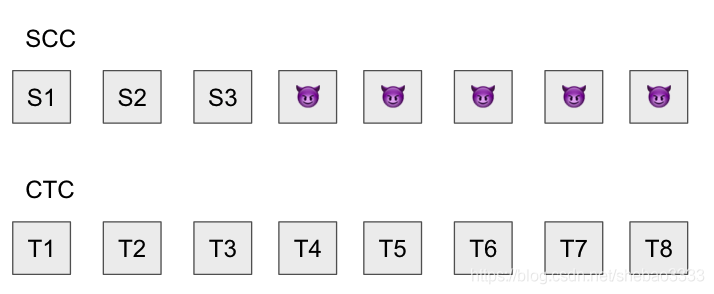
我們注定要失敗嗎?我們必須做點什么!
眾所周知,Optimistic Rollup假定存在驗證者:對于Sequencer發布的每個交易,驗證者負責下載該交易并將其應用于本地狀態,如果一切都匹配,它們什么也不做,但是如果不匹配,那就有問題了!為了解決該問題,他們將嘗試在以太坊上重新執行T4以產生S4,然后,將修剪所有在S4之后發布的狀態根,因為無法保證它對應于有效狀態:
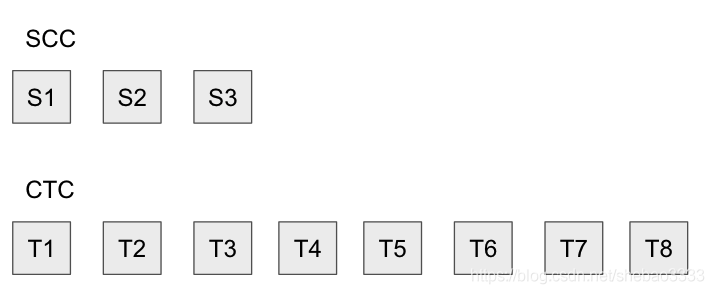
從較高層面來說,欺詐證明是“以S3作為我的開始狀態,我想證明在S3上應用T4會導致S4,這與Sequencer發布的內容不同(😈),結果,我希望洗掉S4及其之后的所有內容,”
如何實施?
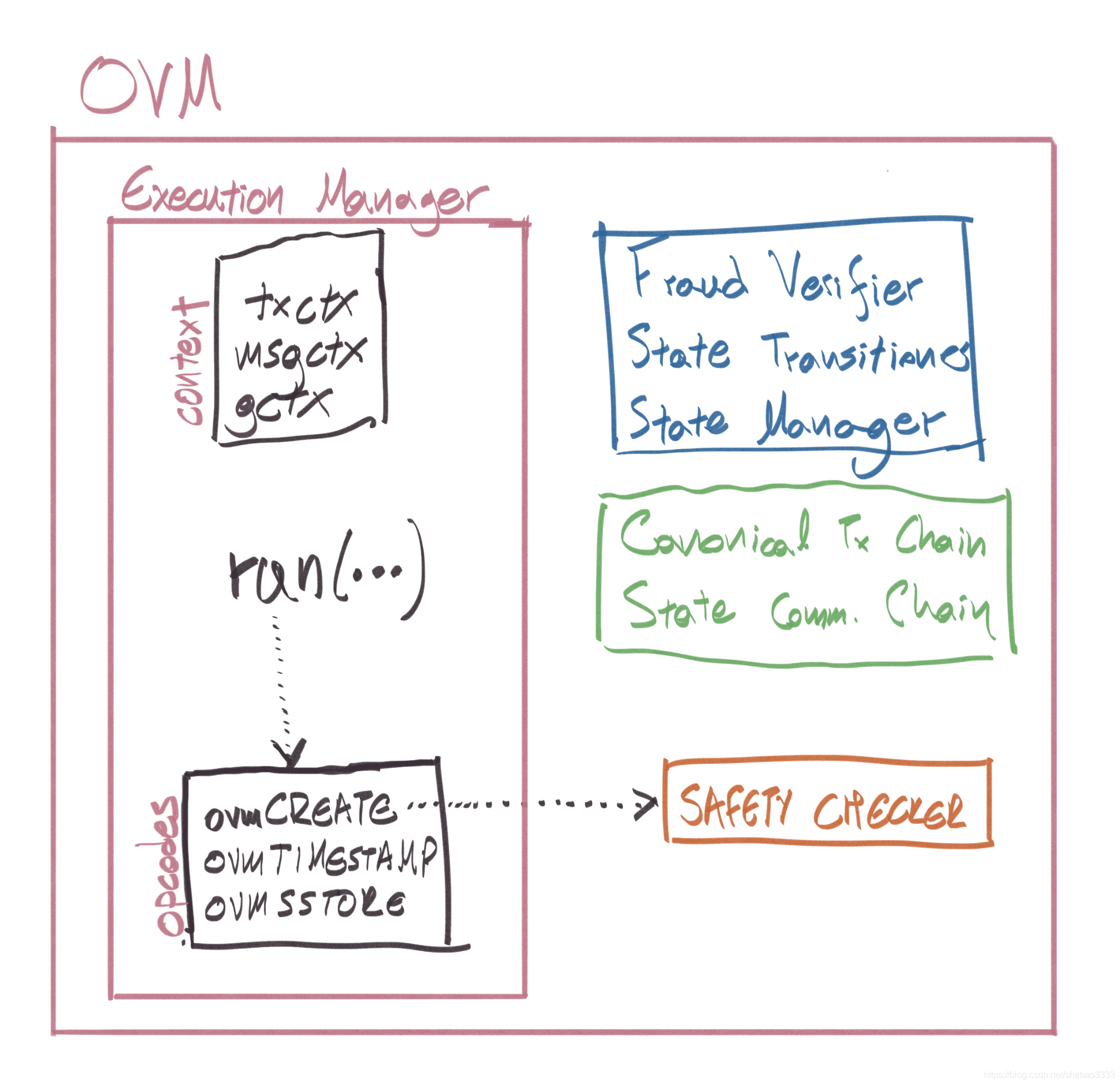
在圖1中看到的是OVM在L2中以其“簡單”執行模式運行,在L1上運行時,OVM處于防欺詐模式,并且啟用了它的更多組件(在L1和L2上都部署了Execution Manager和Safety Checker ):
- 欺詐驗證者:負責協調整個欺詐證明驗證程序的合約,它呼叫的狀態遷移工廠來初始化一個新的欺詐證據, 如果證據造假成功,它將修剪這是從狀態承諾鏈的爭議點之后發布的任何批次,
- State Transitioner(狀態轉換程式):當使用前置狀態的根創建爭議并且有爭議的交易時,由欺詐驗證程式部署, 其職責是調出執行管理器,并根據規則忠實地執行鏈上交易,以為有爭議的交易產生正確的事后狀態根源,成功 執行的欺詐證明將導致狀態轉移器中的后狀態根與狀態承諾鏈中的狀態根不匹配,狀態轉換器可以處于以下3種狀態 中的任何一種:PRE EXECUTION, POST EXECUTION, COMPLETE,
- 狀態管理器:用戶提供的任何資料都存盤在此處,這是一個“臨時”狀態管理器,區域署用于欺詐證明,并且僅包含 有關有爭議的交易涉及的狀態的資訊,
在防欺詐模式下運行的OVM如下所示:
欺詐證明分為幾個步驟:
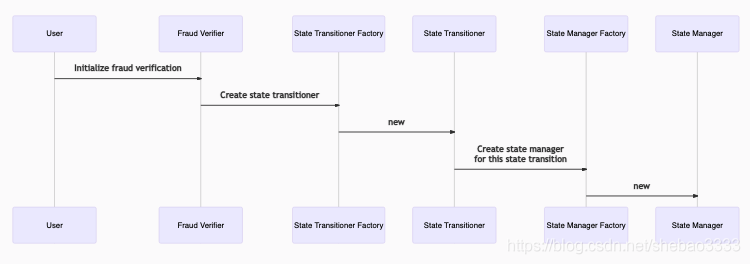
步驟1:宣告您要爭議的狀態轉換
- 用戶呼叫欺詐驗證者的initializeFraudVerification,提供狀態前的根(及其在狀態承諾鏈中的證明)和有爭議的 交易(及其在交易鏈中的證明),
- State Transitioner合約是通過State Transitioner工廠部署的,
- 通過狀態管理工廠部署狀態管理合約,它不會包含整個L2狀態,而是僅填充交易所需的部分;你可以將其視為“部分狀態管理員”,
State Transitioner現在處于PRE EXECUTION階段,
步驟2:上傳所有交易狀態
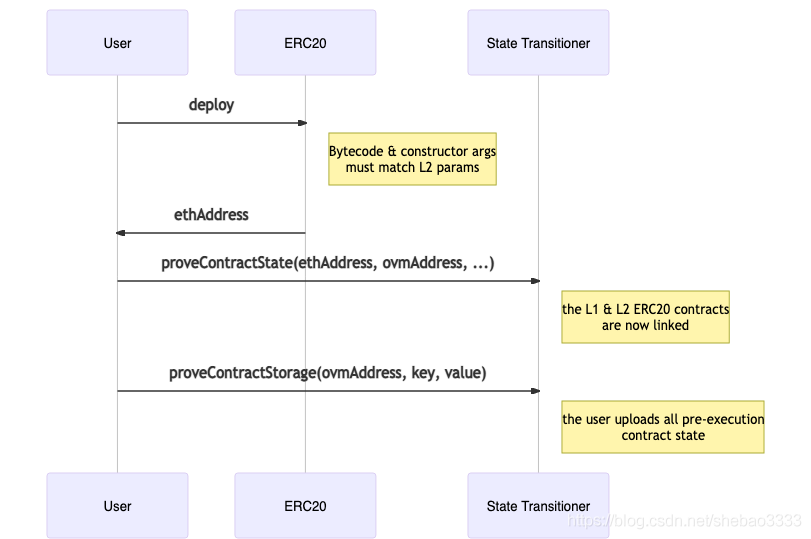
如果我們嘗試直接執行有爭議的交易,則該交易將立即失敗,并顯示INVALID_STATE_ACCESS錯誤,因為從步驟1開始,在剛部署的L1狀態管理器上未加載任何涉及的L2狀態,OVM沙箱將檢測是否SM尚未填充某些觸摸狀態,并強制首先加載所有觸摸狀態需求,
例如,如果有爭議的交易是簡單的ERC20代筆轉移,則初始步驟為:
- 在L1、L2上部署ERC20 :L2和L1合約的位元組代碼必須匹配,才能在L1和L2之間執行相同的操作,我們保證在位元組碼 前加一個“魔術”前綴,將其復制到記憶體中并存盤在指定地址,
- 呼叫proveContractState:這會將L2 OVM合約與新部署的L1 OVM合同鏈接在一起(合約已部署并鏈接,但仍未加載存盤),鏈接是指將OVM地址用作映射中的鍵,其中值是包含合同帳戶狀態的結構,
- 呼叫proveStorageSlot:標準ERC20轉賬會減少發送者余額,增加接收者的余額,這將在執行交易之前上載接收方和發送方 的余額,對于ERC20,余額通常存盤在映射中,因此根據Solidity的存盤布局,鍵將為keccak256(slot + address),
步驟3:一旦提供所有預狀態,請運行交易
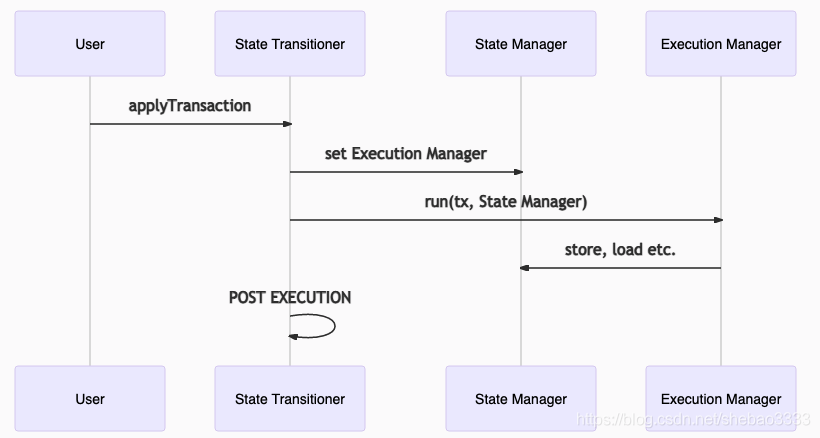
然后,用戶必須通過呼叫State Transitioner的applyTransaction來觸發交易的執行,在此步驟中,執行管理器開始使用欺詐證明的狀態管理器執行交易,執行完成后,狀態轉換程式過渡到該POST EXECUTION階段,
步驟4:提供后期狀態
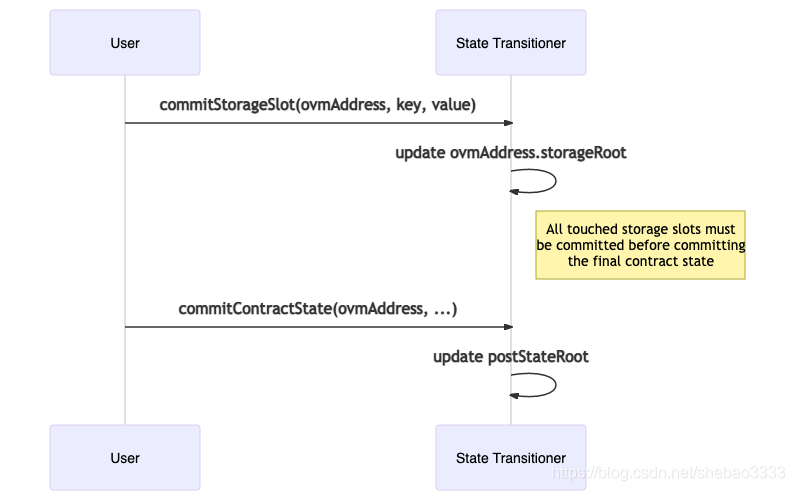
在L1上執行期間(步驟3),合同存盤位或帳戶狀態(例如,亂數)中的值將更改,這將導致狀態轉換程式的后狀態根更改,但是,由于狀態轉換器/狀態管理器對不知道整個L2狀態,因此它們無法自動計算新的后狀態根,
為了避免這種情況,如果存盤插槽或帳戶狀態的值發生更改,則將存盤插槽或帳戶標記為“ changed”,并增加未提交的存盤插槽或帳戶的計數器,我們要求對于每個更改的專案,用戶還必須提供L2狀態的防彎證明,表明這確實是所觀察到的值,每次“提交”存盤插槽更改時,都會更新合約帳戶的存盤根目錄,在提交所有更改的存盤插槽后,合約的狀態也將提交從而更新過渡器的后狀態root,對于發布的每個后期狀態資料,該計數器相應地遞減,
因此,可以預期,在交易中涉及的所有合約的狀態更改都已提交之后,結果后的狀態根是正確的,
步驟5:完成狀態轉換并最終確定欺詐證明
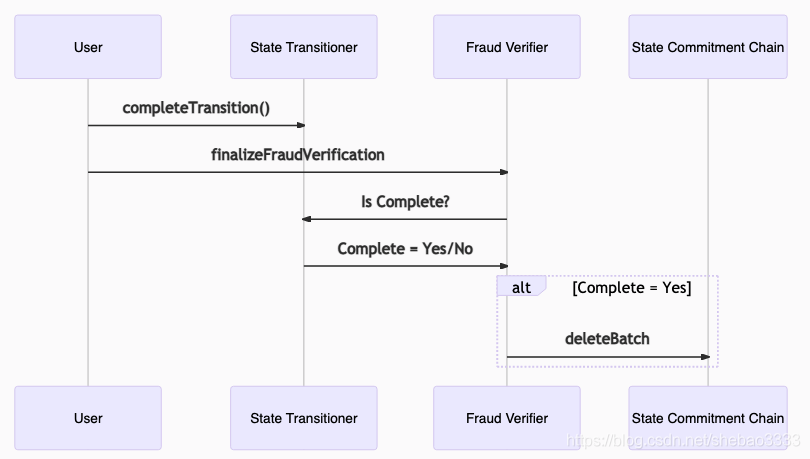
完成狀態轉換是一個簡單的completeTransition呼叫程序,它要求步驟4中的所有帳戶和存盤插槽都已提交(通過檢查未提交狀態的計數器等于0來進行),
最后,在Fraud Verifier合約上呼叫finalizeFraudVerification,該合約檢查狀態轉換程式是否完成,如果是,則呼叫deleteStateBatch,該方法它繼續從SCC洗掉(包括)有爭議的交易之后的所有狀態根批處理,CTC保持不變,因此原始交易將以相同順序重新執行,
激勵+債券
為了使系統保持開放并無需許可,SCC旨在允許任何人成為Sequencer并發布狀態批,為避免SCC被垃圾資料淹沒,我們引入了1個限制:
Sequencer必須由債券管理器智能合約標記為抵押品,你需要存入固定金額的抵押品,并且可以在7天后提取該金額,
但是,在抵押后,惡意的提議者可以反復創建欺詐性的狀態根源,希望沒有人對此提出異議,從而使他們有錢,如果忽略用戶從Rollup和惡意Sequencer社交協調遷移的場景,那么這里的攻擊成本極低,
該解決方案在L2系統設計中是非常標準的:如果成功證明了欺詐,則X%的提議者的保證金會被燒掉13,剩余的(1-X)%會按比例分配給每個為第2步和第4步提供資料的用戶,現在,Sequencer的背叛成本要高得多,并且假設它們的行為合理,則有望創造足夠的誘因來防止它們惡意行為,即使有爭議狀態沒有直接影響他們,這也為用戶提供了一個誘人的誘因,使他們提交資料以證明欺詐行為,
nuisance gas
有一個單獨的gas維度,稱為“有害gas”,用于限制欺詐證明的凈gas成本,特別是,L2 EVM gas成本表中未反映欺詐證明建立階段的證人資料(例如,默克爾證明),ovmOPCODES針對nuisance gas需要另外付費,每當觸摸一個新的存盤槽或帳戶時,都會收取費用,如果訊息嘗試使用超出訊息背景關系允許范圍的nuisance gas,則執行恢復,
原文鏈接:Optimism Rollup原理詳解 — 匯智網
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/259534.html
標籤:區塊鏈
上一篇:ZILD 2.0即將上線,有望成為DeFi借貸板塊的引領者
下一篇:微信支付寶簽名邏輯鑒賞