我有一個資料集,我需要從中提取用戶和用戶資料,這些資料是在 1 月和 2 月兩個月內購買的。您能幫我提供代碼嗎?
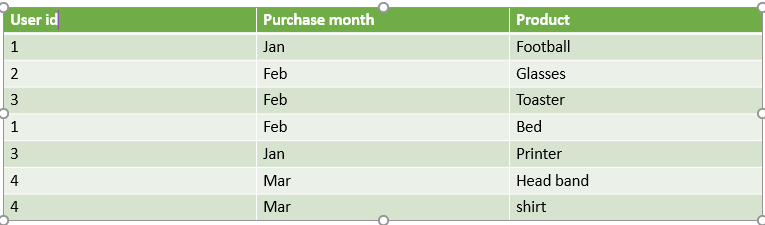
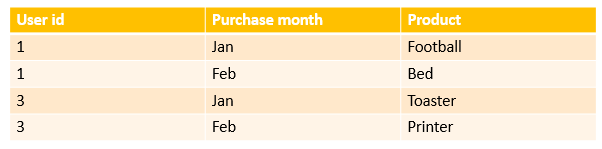
所需的輸出應如下所示
uj5u.com熱心網友回復:
篩選:
df[(df["Purchase month"]=="Jan") | (df["Purchase month"]=="Feb")]
種類:
df.sort_values(by=["user_id"])
uj5u.com熱心網友回復:
首先,我們可以使用 agroupby來讓客戶在至少 2 個不同的月份購買:
>>> df_grouped = df.groupby(['user_id'], as_index=False)['purchase_month'].nunique()
>>> valid_users = df_grouped[df_grouped['purchase_month']>=2]['user_id'].tolist()
>>> valid_users
[1, 3]
然后我們可以用這些用戶過濾第一個 DataFrame 以獲得預期的結果:
>>> df[df["user_id"].isin(valid_users)].sort_values(by=["user_id"])
user_id purchase_month product
0 1 jan football
3 1 feb bed
2 3 feb toaster
4 3 jan printer
uj5u.com熱心網友回復:
嘗試:
groupby并為每個用戶 ID 創建一個月份串列- 僅保留月份包括 Jan 和 Feb 的行,即該集合
{"Jan", "Feb"}是月份的子集
months = df.groupby("User id")["Purchase month"].agg(list)
output = df[df["User id"].isin(months[months.map({"Jan", "Feb"}.issubset)].index)]
>>> output
User id Purchase month Product
0 1 Jan Football
2 3 Feb Toaster
3 1 Feb Bed
4 3 Jan Printer
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/370793.html
上一篇:如何向列索引添加級別?