我的資料框的組由兩個索引列 (cat1和cat2)定義。對于第三個非索引變數 ,var我想找到索引cat2,對于 的var每個值的最大值cat1。當我使用idxmax(),我得到兩個總指數值cat1和cat2對應的最大值的var是(B,dog)。我希望每個級別的cat1.
df = pd.DataFrame({
'cat1': ['A'] * 4 ['B'] * 4 ['C'] * 4,
'cat2': ['cat', 'dog', 'mouse', 'bear'] * 3,
'var': [23, 33, 45, 66, 77, 88, 44, 55, 33, 22, 11, 44],
}).set_index(['cat1', 'cat2'])
var
cat1 cat2
A cat 23
dog 33
mouse 45
bear 66
B cat 77
dog 88
mouse 44
bear 55
C cat 33
dog 22
mouse 11
bear 44
這是產生的結果:
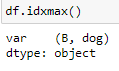
預期結果:

我不在乎格式。
uj5u.com熱心網友回復:
有無數種方法可以創建此代碼的輸出。我演示了以下 3 種方式:
MaxEachcat1 = df[df['var'] == df.groupby(level=[0])['var'].transform(max)]
print(MaxEachcat1)
print(MaxEachcat1.index)
print(MaxEachcat1.index[0])
輸出:
# way 1
var
cat1 cat2
A bear 66
B dog 88
C bear 44
# way 2
MultiIndex([('A', 'bear'),
('B', 'dog'),
('C', 'bear')],
names=['cat1', 'cat2'])
# way 3
('A', 'bear')
uj5u.com熱心網友回復:
使用groupby.idxmax:
df.groupby('cat1').idxmax() # or df.groupby(level=0).idxmax()
# var
# cat1
# A (A, bear)
# B (B, dog)
# C (C, bear)
- 您當前的代碼使用
DataFrame.idxmax,它回傳全域最大值的索引。 - 但是,您只需要每個組的最大值的索引,因此請使用
groupby.idxmax.
(在未來,請像 sammywemmy 所說的那樣,將示例資料幀作為可復制粘貼的代碼而不是影像提供。)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/374975.html