import pandas as pd
nameBank = ["John Doe", "Jane Doe", "Patrick Star", "Spongebob Squarepants"]
phoneList = []
nameList = []
list1 = ["1234567890", "John doe", "Not a NAME/USELESS FILLERINFO", "2345678901", "jane doe", "Not a NAME/USELESS FILLERINFO", "Not a NAME/USELESS FILLERINFO", "3456789012", "4567890123", "5678901234", "patrick star", "6789012345"]
df = pd.DataFrame({'Phone Number': phoneList, 'Name': nameList})
df.to_csv('results.csv', index=False, encoding='utf-8')
print(df)
我想要做的是從這個 list1 中檢索每個電話號碼并將其放入phoneList.
從那里我想查看nameBank串列中當前電話號碼之后和串列中下一個電話號碼之前的名稱。
如果電話號碼后面有一個名字,那么我希望能夠將它nameList附加到nameList. 所以它基本上可以對應一個excel圖表。
即電話號碼1234567890在兩個串列之間具有與其對應的姓名 John Doe。第二個電話號碼附加了 Jane Doe 的名字,因此當您使用這兩個串列創建使用 Pandas 的表時,它們將對應。第三個電話號碼3456789012與串列中的下一個電話號碼之間沒有名稱,因此我希望 nameList 的附加值是"no name found".
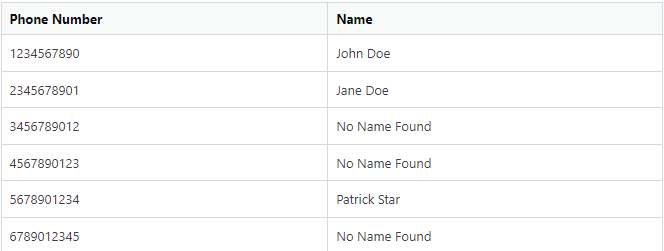
基本上輸出表的樣子:
uj5u.com熱心網友回復:
所以,你想把 list1 決議成一個系列:
list1 = ["1234567890", "John doe", "Not a NAME/USELESS FILLERINFO", "2345678901", "jane doe", "Not a NAME/USELESS FILLERINFO", "Not a NAME/USELESS FILLERINFO", "3456789012", "4567890123", "5678901234", "patrick star", "6789012345"]
import re
num = re.compile('\d{10}')
output = {}
i = 0
while i < len(list1):
if not num.match(list1[i]):
i = 1
continue
output[list1[i]] = list1[i 1] if i 1<len(list1) and not num.match(list1[i 1]) else 'not found'
i = 1
series = pd.Series(output)
輸出:
1234567890 John doe
2345678901 jane doe
3456789012 not found
4567890123 not found
5678901234 patrick star
6789012345 not found
dtype: object
uj5u.com熱心網友回復:
import pandas as pd
nameBank = ["John Doe", "Jane Doe", "Patrick Star", "Spongebob Squarepants"]
list1 = ["1234567890", "John doe", "Not a NAME/USELESS FILLERINFO", "2345678901", "jane doe", "Not a NAME/USELESS FILLERINFO", "Not a NAME/USELESS FILLERINFO", "3456789012", "4567890123", "5678901234", "patrick star", "6789012345"]
data = []
for index, elem in enumerate(list1):
if elem.isnumeric():
if (len(list1) - 1) > index:
if list1[index 1].casefold() in map(str.casefold, nameBank):
data.append([elem,list1[index 1].title()])
else:
data.append([elem, 'No Name Found'])
else:
data.append([elem, 'No Name Found'])
df = pd.DataFrame(data, columns=['Phone Number', 'Name'])
# df.to_csv('results.csv', index=False, encoding='utf-8'
print(df)
輸出:
Phone Number Name
0 1234567890 John Doe
1 2345678901 Jane Doe
2 3456789012 No Name Found
3 4567890123 No Name Found
4 5678901234 Patrick Star
5 6789012345 No Name Found
uj5u.com熱心網友回復:
import re
import pandas as pd
list1 = ["1234567890", "John doe", "Not a NAME/USELESS FILLERINFO", "2345678901", "jane doe", "Not a NAME/USELESS FILLERINFO", "Not a NAME/USELESS FILLERINFO", "3456789012", "4567890123", "5678901234", "patrick star", "6789012345"]
nameBank = ["John Doe", "Jane Doe", "Patrick Star", "Spongebob Squarepants"]
def mapList(list1):
output = []
for index, item in enumerate(list1, start=0):
if re.match("^\d{10}", item):
# Use any one condition
# if index < len(list1) - 1 and list1[index 1] in nameBank:
if index < len(list1) - 1 and not re.match("^\d{10}", list1[index 1]):
output.append([list1[index], list1[index 1]]);
else:
output.append([list1[index],'No Name Found']);
return output;
df = pd.DataFrame(mapList(list1), columns=['Phone Number', 'Name'])
print(df)
輸出:
Phone Number Name
0 1234567890 John doe
1 2345678901 jane doe
2 3456789012 No Name Found
3 4567890123 No Name Found
4 5678901234 patrick star
5 6789012345 No Name Found
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/374976.html
上一篇:如何回傳與python中列的最大值相對應的多索引的每個級別的索引
下一篇:在特定行的特定列上向前填充