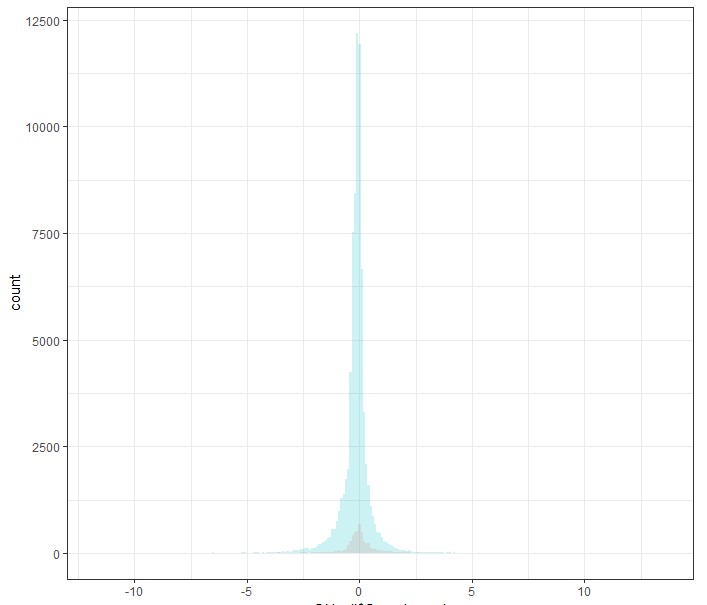
我使用以下方法創建了圖:
ggplot(data_all, aes(x = data_all$Speed, fill = data_all$Season))
theme_bw()
geom_histogram(position = "identity", alpha = 0.2, binwidth=0.1)
如您所見,可用資料量的差異非常大。有沒有辦法只看分布而不看總資料量?
uj5u.com熱心網友回復:
您可以使用以前可能見過的符號從 stat 函式中參考其他一些計算值:..value... 我不確定這些的正確名稱或在哪里可以找到記錄的串列,但有時這些被稱為“特殊變數”或“計算美學”。
在這種情況下,y 軸上的默認計算美學geom_histogram()是..count..。在比較不同總N大小的分布時,使用..density... 您可以通過直接在函式中將其..density..傳遞給美學來訪問。ygeom_histogram()
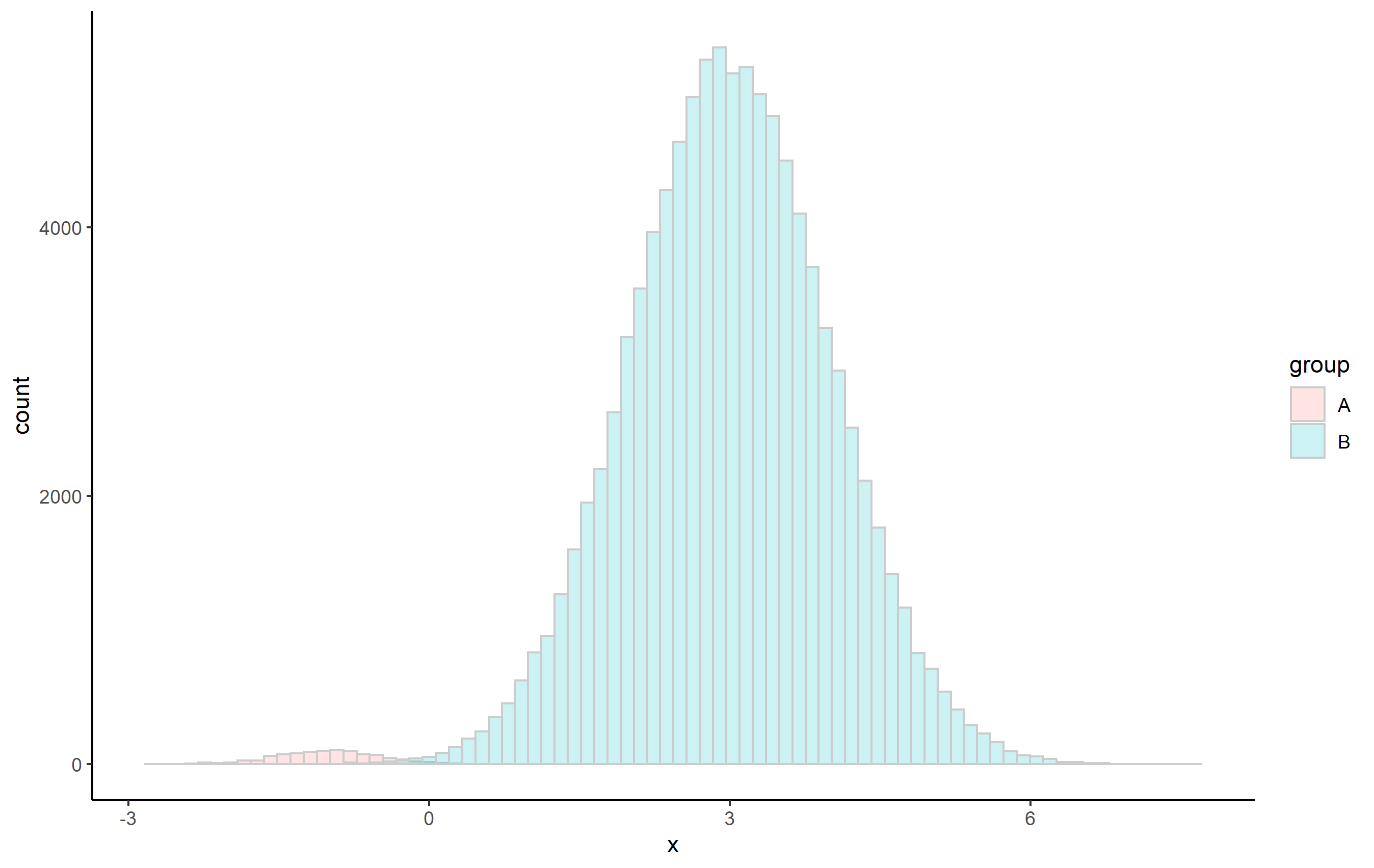
首先,這是兩個大小差異很大的直方圖的示例(類似于 OP 的問題):
library(ggplot2)
set.seed(8675309)
df <- data.frame(
x = c(rnorm(1000, -1, 0.5), rnorm(100000, 3, 1)),
group = c(rep("A", 1000), rep("B", 100000))
)
ggplot(df, aes(x, fill=group)) theme_classic()
geom_histogram(
alpha=0.2, color='gray80',
position="identity", bins=80)
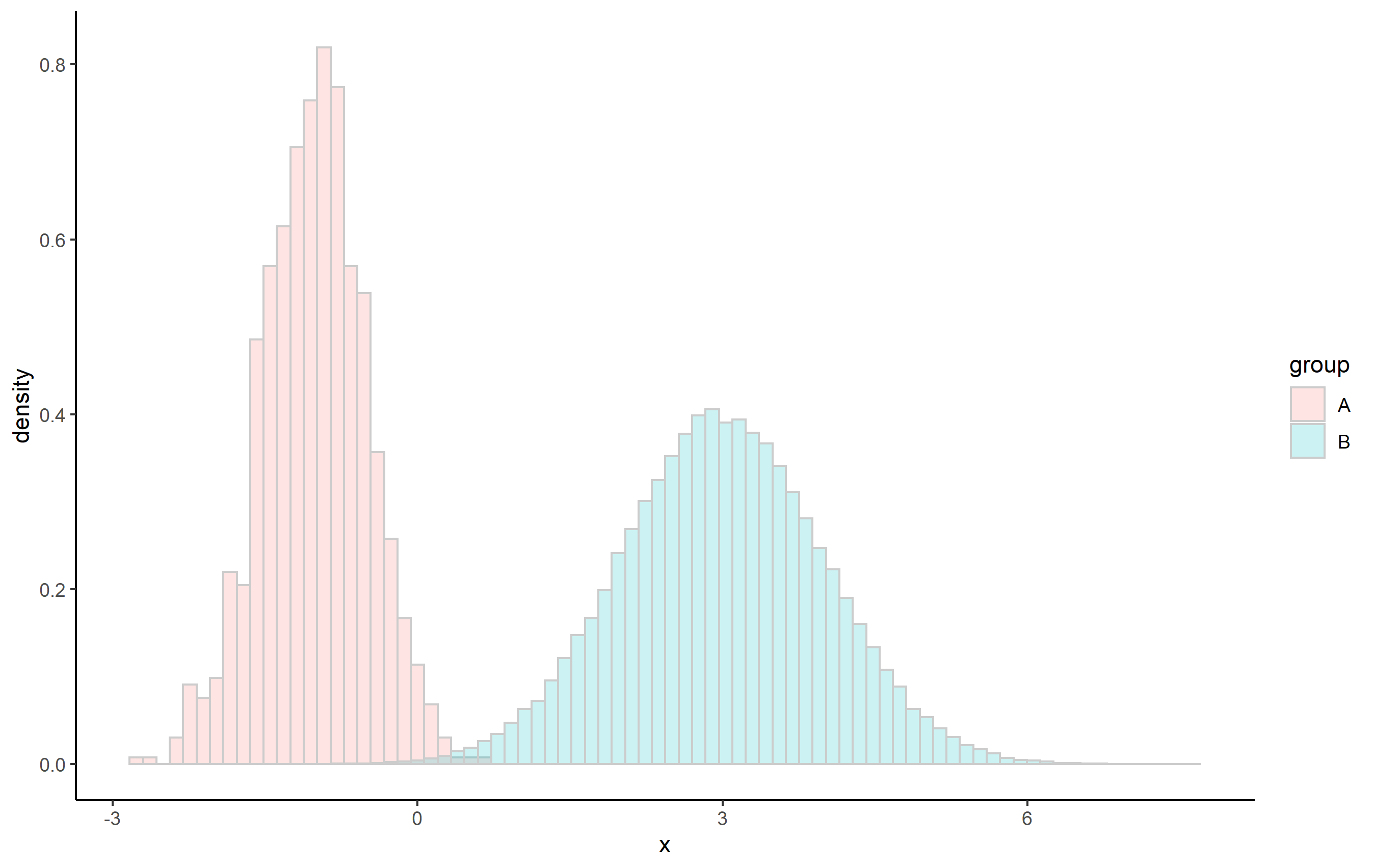
這是使用相同的情節..density..:
ggplot(df, aes(x, fill=group)) theme_classic()
geom_histogram(
aes(y=..density..), alpha=0.2, color='gray80',
position="identity", bins=80)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/420138.html
標籤:
上一篇:散點餅圖:圓圈未正確定位在地圖上