我正在嘗試尋找解決方案以改進字串搜索程序,因此我選擇了全文索引策略。
但是,在實作它之后,我仍然可以看到,在使用多個帶有 OR 子句的全文索引表使用多個字串進行搜索時,性能會受到影響。
(例WHERE CONTAINS(F.*,'%Gayan%') OR CONTAINS(P.FirstName,'%John%'))
作為一種解決方案,我正在嘗試使用CONTAINSTABLE期望性能改進。
現在,我在CONTAINSTABLE使用LEFT JOIN
請看下面的例子。
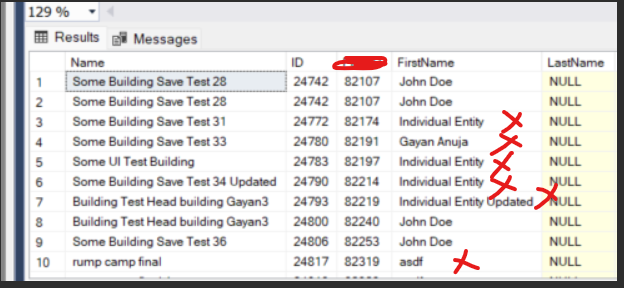
查詢 1
SELECT F.Name,p.*
FROM P.Role PR
INNER JOIN P.Building F ON PR.PID = F.PID
LEFT JOIN CONTAINSTABLE(P.Building,*,'%John%') AS FFTIndex ON F.ID = FFTIndex.[Key]
LEFT JOIN P.Relationship PRSHIP ON PR.id = prship.ToRoleID
LEFT JOIN P.Role PR2 ON PRSHIP.ToRoleID = PR2.ID
LEFT JOIN P.Person p ON pr2.ID = p.PID
LEFT JOIN CONTAINSTABLE(P.Person,FirstName,'%John%') AS PFTIndex ON P.ID = PFTIndex.[Key]
WHERE F.Name IS NOT NULL
這會產生以下結果。
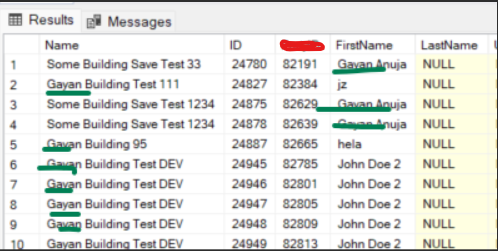
查詢 2
SELECT F.Name,p.*
FROM P.Role PR
INNER JOIN P.Building F ON PR.PID = F.PID
INNER JOIN P.Relationship PRSHIP ON PR.id = prship.ToRoleID
INNER JOIN P.Role PR2 ON PRSHIP.ToRoleID = PR2.ID
INNER JOIN P.Person p ON pr2.ID = p.PID
WHERE CONTAINS(F.*,'%Gayan%') OR CONTAINS(P.FirstName,'%John%')
AND F.Name IS NOT NULL
結果
Expectation
To use query 1 in a way that works as the behavior of an SQL SERVER OR clause. As I can understand Query 1's CONTAINSTABLE, joins the data with the building table, and the rest of the results are going to ignore so that the CONTAINSTABLE of the Person table gets data that already contains the keyword filtered from the building table.
If the keyword = Building, I want to match the keyword in both the tables regardless of searching a saved record in both the tables. Having a record in each table is enough.
Summary
Query 2 performs well but is creates a slowness when the words in the indexes are growing. Query 1 seems optimized(When it comes to multiple online resources and MS Documentation), however, it does not give me the expected output.
Is there any way to solve this problem?
我并不嚴格依附于CONTAINSTABLE. 建議另一種優化方法也很重要。
謝謝你。
uj5u.com熱心網友回復:
如果沒有完整的資料集,很難明確地說出,但有幾個可供探索的選項
洗掉無效的 % 通配符
你為什么用'%SearchTerm%'?如果您使用不帶通配符 (%) 的搜索詞,性能會提高嗎?如果您想要一個與前綴匹配的單詞,請嘗試類似
WHERE CONTAINS (String,'"SearchTerm*"')
試試臨時表
我的猜測是 CONTAINS 比 CONTAINSTABLE 略快,因為它不計算排名,但我不知道是否有人嘗試過對其進行基準測驗。無論哪種方式,在加入其余表之前,我都會嘗試將匹配項保存到臨時表中。這將允許優化器創建更好的執行計劃
SELECT ID INTO #Temp
FROM YourTable
WHERE CONTAINS (String,'"SearchTerm"')
SELECT *
FROM #Temp
INNER JOIN...
通過去除嘈雜的詞優化全文索引
你可能會發現你有一些嘈雜的詞,也就是在你的資料中重復出現很多次的詞,這些詞沒有意義,比如“the”或者一些商業術語。將這些添加到您的停止串列將意味著您的全文索引將忽略它們,從而使您的索引更小從而更快
下面的查詢將在頂部列出最常見的索引詞
Select *
From sys.dm_fts_index_keywords(Db_Id(),Object_Id('dbo.YourTable') /*Replace with your table name*/)
Order By document_count Desc
這個或那個標準
對于您WHERE CONTAINS(F.*,'%Gayan%') OR CONTAINS(P.FirstName,'%John%')想要這個或那個的標準,這很棘手。即使在使用簡單的相等運算子時,OR 子句通常也會執行。我會嘗試做兩個查詢并合并結果,例如:
SELECT * FROM Table1 F
/*Other joins and stuff*/
WHERE CONTAINS(F.*,'%Gayan%')
UNION
SELECT * FROM Table2 P
/*Other joins and stuff*/
WHERE CONTAINS(P.FirstName,'%John%')
或者這是更多的作業,但您可以將所有資料加載到包含所有列的巨型非規范化表中。然后將全文索引應用于該表并以這種方式調整您的搜索條件。這可能是最快的搜索方法,但是您必須確保資料在非規范化表和基礎規范化表之間同步
SELECT B.*,P.* INTO DenormalizedTable
FROM Building AS B
INNER JOIN People AS P
CREATE FULL TEXT INDEX ft ON DenormalizedTable
etc...
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/435015.html