@@DBTS在 SQL Server中,是否有一種合法或巧妙的方式來覆寫或“快進”的值?我能夠做到這一點的唯一方法是對回圈中具有timestamp/rowversion列的表進行一些虛擬更新,其中一個回圈步驟如下:
SELECT @@DBTS -- original value
-- no-op update that increments @@DBTS nevertheless
UPDATE Table_with_a_rowversion_column SET any_other_column = any_other_column
SELECT @@DBTS -- value has incremented by a number of rows in Table_with_a_rowversion_column
我不喜歡這個,因為它很慢并且需要資源。我想將@@DBTS 增加數十億并快速完成 - 多達 16 ^ 9。我的回圈腳本在 30 分鐘內完成了少于 16^8 的增量,因此至少需要 8 小時。
背景/為什么有人想這樣做?
我正在將資料從資料庫 1 遷移到資料庫 2。它們具有不同的模式,但 1 和 2 都有一個“狀態”表(大約一百萬行)和一個“state_history”表(數百萬行)。
state表有一rowversion列。表上的觸發器state將更新前的資料插入state_history表中(受某些過濾) - 包括捕獲的 rowversion 值(另存為binary(8))
rowversion/binary(8) 列的并集state和state_history排序是按實際發生的順序對最新和歷史值進行排序的唯一可靠方法(捕獲的系統時鐘并不總是可靠的)。
我想在目標資料庫 2 中保持相同的單調遞增 rowversion 不變數,系統的少數部分依賴于這個不變數。我確實可以控制歷史行版本,因為它的binary(8)范圍從 16^5 到 16^9 不等,即沒有大的基值要減去,所以我必須保持原樣。
但我對主目標表沒有任何控制權state- SQL 根據目標資料庫的@@DBTS. 我希望我可以簡單地告訴它將其覆寫為 16^9,然后運行我的遷移腳本。
uj5u.com熱心網友回復:
有一種輕松的勝利。@@DBTS 將針對 INSERT 進行更新,并且它不是真實表所獨有的。以下代碼創建了一個虛擬表,然后在 3 分鐘內在我的筆記本電腦上插入了(二進制)十億行。要將值更改為 16^9,將需要 64 次 Truncate/Insert 部分的迭代,而 64*3.2 “僅”是 204.8 分鐘 (3.413) 小時,完成后,您的日志檔案仍然很小,您的PRIMARY 檔案組根本不會增長。
請注意,當您運行此程式時,您需要處于 BULK_LOGGED 或 SIMPLE 恢復模型中,否則它將嚴重破壞您的 T-Log 檔案。生成的 HEAP 大小為 18.75GB,但它僅使用 450MB(不是印刷錯誤......兆位元組)的 T-LOG。
詳細資訊在評論中。閱讀評論!他們很重要!
--===== IMPORTANT! CHANGE ALL OCCURANCES OF THE WORD "SCRATCH" TO THE NAME OF THE DATABASE YOU WANT TO DO THIS IN!!!
-- ALTHOUGH I"VE NOT TESTED FOR IT, I'M PRETTY SURE IT'S GOING TO KNOCK A FAIR BIT OUT OF BUFFER CACHE, NO MATTER WHAT!
-- READ AND UNDERSTAND ALL THE COMMENTS IN THE CODE BELOW OR DON'T USE THIS CODE!
-- TEST IT ON A DEV BOX FIRST!!!
--===== Create a temporary filegroup and presized file so we don't have to wait for growth.
-- Yes... the table (HEAP) will reach a size of 18.75GB (aka 18750MB)
USE Scratch;
ALTER DATABASE Scratch ADD FILEGROUP Dummy;
ALTER DATABASE Scratch
ADD FILE (NAME = N'Dummy'
,FILENAME = N'E:\SQL Server\SQLData\Dummy.ndf'
,SIZE=18750, MAXSIZE = 20000MB, FILEGROWTH=50MB)
TO FILEGROUP Dummy
;
GO
--===== This creates a table with the minimum row width we can get away with.
CREATE TABLE dbo.Dummy (N TINYINT, ts TIMESTAMP) ON Dummy; --It's a HEAP, actually
GO
--===== Do a (binary) BILLION inserts into this working table to increase @@DBTS by 1 BILLION (1024^3) for the database.
-- You could put this in a loop. The file will not grow and we'll do minimal logging to protect the logfile.
-- TO GET THE MINIMAL LOGGING, THE DATABASE MUST BE IN THE BULK LOGGED OR SIMPLE RECOVERY MODEL.
-- OTHERWISE, THIS WILL EXPLODE YOUR LOG FILE.
-- On my laptop, this section takes 3.2 minutes to run and only uses 450MB thanks to minimal logging.
-- And, no, that's not a misprint... ONLY 450 Megabytes of log file useage
TRUNCATE TABLE dbo.Dummy; --Only Page De-Allocations are logged and required to continue minimal logging.
CHECKPOINT; --Forces writes to T-Log file in the BULK LOGGED and to clear in the SIMPLE Recovery Models.
CHECKPOINT; --Sometimes, one CHECKPOINT isn't fully effective.
;
SELECT @@DBTS --Just checking the "Before" value.
;
WITH
E1(N) AS (SELECT 1 FROM (VALUES (1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1))E0(N)) --Up to 16 rows
INSERT INTO dbo.Dummy WITH (TABLOCK) --Required to get minimal logging in BULK LOGGED and SIMPLE Recovery Models
(N)
SELECT TOP 1073741824 CONVERT(TINYINT,1) --Binary BILLION (1024^3)
FROM E1 a,E1 b,E1 c,E1 d,E1 e,E1 f,E1 g,E1 h --Up to 16^8 or 4,294,967,296 rows
OPTION (RECOMPILE,MAXDOP 1) --Helps minimal logging and prevents parallelism for a substantial speed increase.
;
SELECT @@DBTS
;
GO
--===== This is the cleanup of the file and filegroup, which is MUCH faster than a SHRINK.
DROP TABLE dbo.Dummy;
ALTER DATABASE Scratch REMOVE FILE Dummy;
ALTER DATABASE Scratch REMOVE FILEGROUP Dummy;
CHECKPOINT; --Forces writes to T-Log file in the BULK LOGGED and to clear in the SIMPLE Recovery Models.
CHECKPOINT; --Sometimes, one CHECKPOINT isn't fully effective.
GO
SELECT @@DBTS --Verify that the effort wasn't wasted.
;
這是我使用的 Scratch 資料庫的圖片。在我最初的測驗中,它的初始大小為 50MB,兩個檔案都增長了 50MB,以查看最終大小。您可以看到 PRIMARY 檔案組并沒有增長太多(它只有 4MB 并且從 1MB 開始)。我們所做的一切都進入了 DUMMY 檔案組,完成后我們將洗掉它,這樣我們就不必縮小我們的 PRIMARY 或擔心我們剛剛使用的額外 18.75GB。
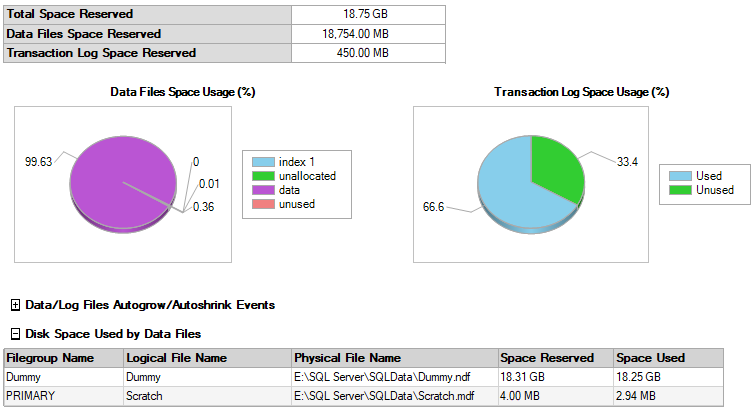
在我們運行上面最后一段代碼洗掉 DUMMY 表、洗掉 DUMMY 檔案和洗掉 DUMMY 檔案組后,總資料檔案大小恢復正常,無需執行 SHRINK。
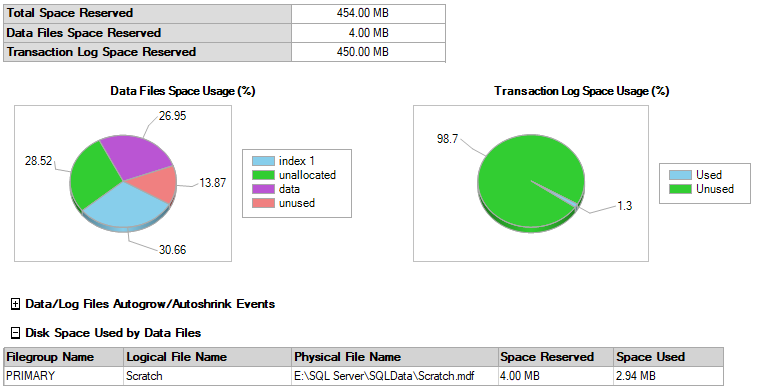
而且,如果日志檔案中只有 450MB 可用,它根本不會增長。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qukuanlian/435016.html