這個查詢的目的是希望是能夠實作分頁查詢,但是根據執行計劃 ,如果查詢的上限數是800,后續參與計算的基數就是799 而不是49,這個將查詢的上限數上調到190000 ,則后續參與計算的基數就是189950,我覺得這樣嚴重影響sql的執行性能
sql的代碼如下 :
with material_a as
(select *
from (select row_.*, rownum rownum_
from t_sap_material row_
where rownum < 800
order by row_.material_info_id)
where rownum_ > 750),
factory_a as
(select materail_id,
listagg(factory, ',') within GROUP(order by factory) factory_list
from (select distinct ma.materail_id, ma.factory
from t_sap_material_factory_map ma inner join material_a m_a on m_a.material_info_id = ma.materail_id)
group by materail_id),
org_a as
(select material_info_id,
listagg(organization_id, ',') within GROUP(order by organization_id) org_list
from (select distinct material_info_id,organization_id from (select m.material_info_id,m.organization_id
from t_sap_materal_sale_map m where m.material_info_id in (select m_a.material_info_id from material_a m_a)
))
group by material_info_id)
select k.*, fa.factory_list, oa.org_list
from material_a k
left join factory_a fa
on fa.materail_id = k.material_info_id
left join org_a oa
on oa.material_info_id = k.material_info_id

這個將分頁的上限數上調到190000 ,則后續參與計算的基數就是189950 如下
with material_a as
(select *
from (select row_.*, rownum rownum_
from t_sap_material row_
where rownum < 190000
order by row_.material_info_id)
where rownum_ > 189950),
factory_a as
(select materail_id,
listagg(factory, ',') within GROUP(order by factory) factory_list
from (select distinct ma.materail_id, ma.factory
from t_sap_material_factory_map ma inner join material_a m_a on m_a.material_info_id = ma.materail_id)
group by materail_id),
org_a as
(select material_info_id,
listagg(organization_id, ',') within GROUP(order by organization_id) org_list
from (select distinct material_info_id,organization_id from (select m.material_info_id,m.organization_id
from t_sap_materal_sale_map m where m.material_info_id in (select m_a.material_info_id from material_a m_a)
))
group by material_info_id)
select k.*, fa.factory_list, oa.org_list
from material_a k
left join factory_a fa
on fa.materail_id = k.material_info_id
left join org_a oa
on oa.material_info_id = k.material_info_id
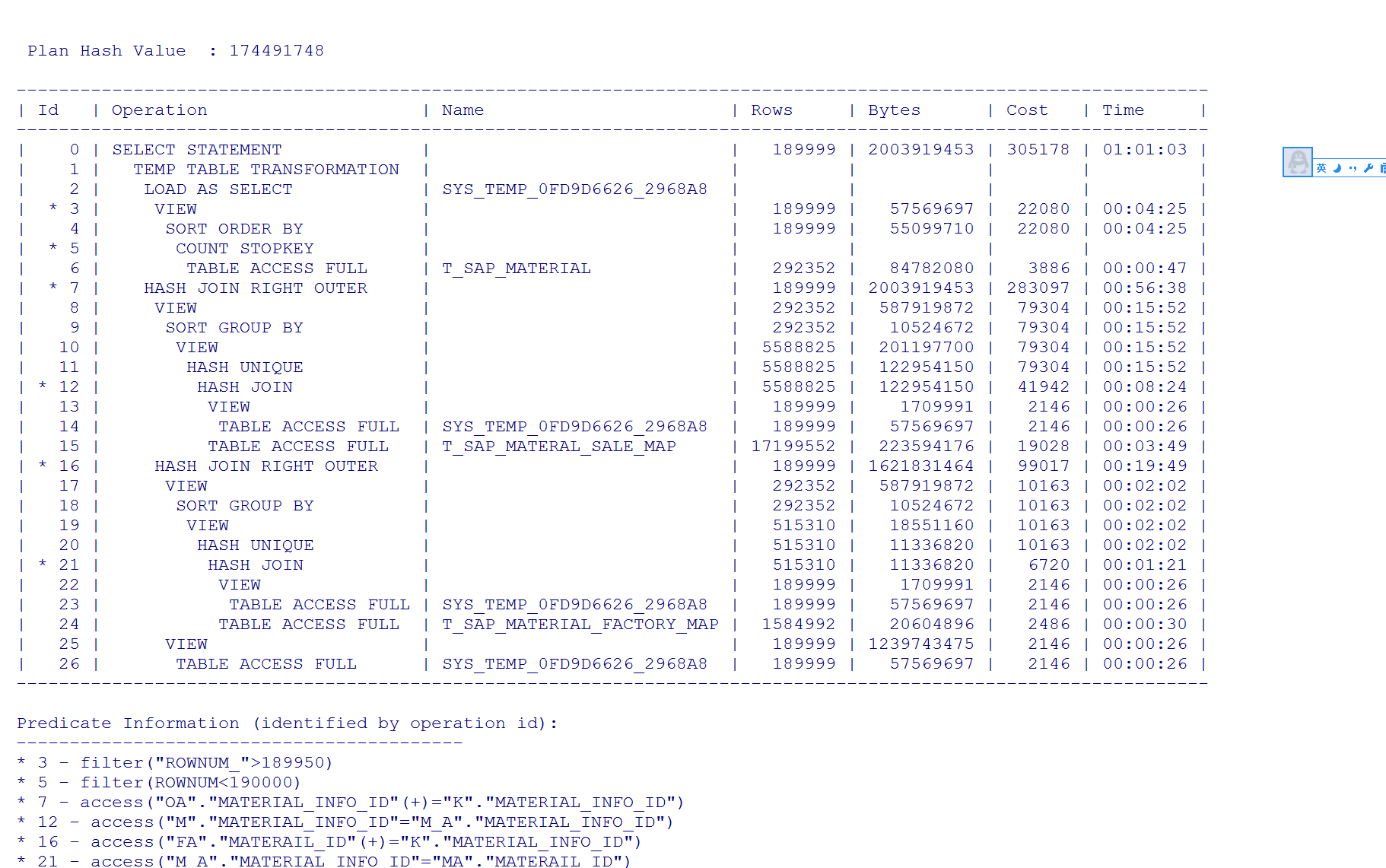
我覺得這樣嚴重影響sql的執行性能,但我不知道這是不是這個sql優化的重點,請教各位怎么能能更好的優化這個sql?
uj5u.com熱心網友回復:
看了下,好像還真是,你的耗時主要是你的hash join right outer,果然你第一條記錄少的話可以減少很多資料匹配。不過你這個還可以優化的,加索引吧。
uj5u.com熱心網友回復:
t_sap_material_factory_map t_sap_materal_sale_map 是t_sap_material 的子表 sql的意思是要把t_sap_material_factory_map t_sap_materal_sale_map 表中的一列合并,用逗號分割匯總好查詢結果里面uj5u.com熱心網友回復:
索引 加哪合適呢?uj5u.com熱心網友回復:
驅動表選擇問題,可以對比第一個執行快的執行計劃, 加上hint/ select /*+ use_hash(k,fa) leading(k) use_hash(k,oa)*/ k.*, fa.factory_list, oa.org_list,你可以試下效果轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/103490.html
標籤:開發
下一篇:ora-01410