uj5u.com熱心網友回復:
建立函式
ALTER FUNCTION dbo.f_splite
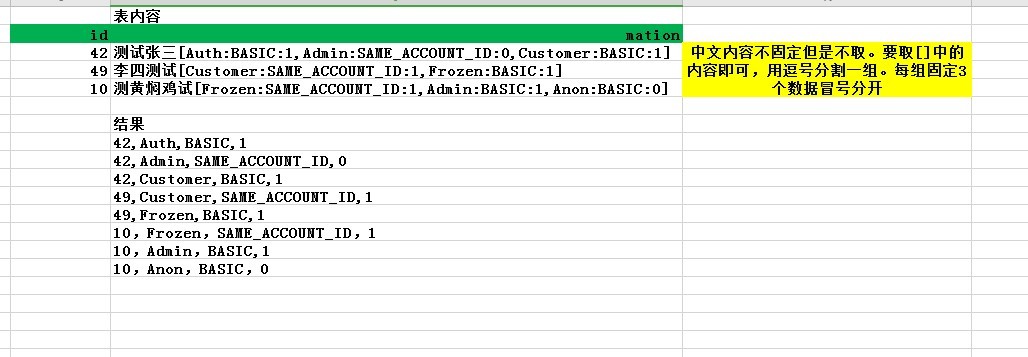
--測驗資料
uj5u.com熱心網友回復:
不知你要拆分成兩列還是四列?如果兩列就是1#那樣,四列參考下面這個(拆分函式可以用1#的):
DECLARE @t TABLE(id INT, context NVARCHAR(200));
uj5u.com熱心網友回復:
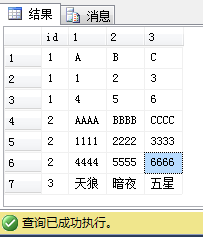
最后的查詢也可用PIVOT來轉換行列,也是一樣的:
SELECT p.id, p.[3], p.[2], p.[1] from (SELECT a.id,
uj5u.com熱心網友回復:
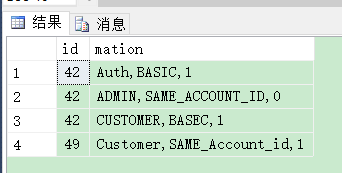
參考 1 樓 二月十六 的回復: 建立函式ALTER FUNCTION dbo.f_splite --測驗資料 大哥CROSS APPLY ( 這個后面提示語法錯誤
uj5u.com熱心網友回復:
參考 2 樓 Hello World, 的回復: 不知你要拆分成兩列還是四列?如果兩列就是1#那樣,四列參考下面這個(拆分函式可以用1#的):DECLARE @t TABLE(id INT, context NVARCHAR(200)); emmm 請問資料庫版本多少 我這報 substring( 附近語法錯誤
uj5u.com熱心網友回復:
參考 3 樓 Hello World, 的回復: 最后的查詢也可用PIVOT來轉換行列,也是一樣的:SELECT p.id, p.[3], p.[2], p.[1] from (SELECT a.id, 請問就是必須參考 自定義函式嘍
uj5u.com熱心網友回復:
參考 4 樓 weixin_42101800 的回復: Quote: 參考 1 樓 二月十六 的回復: ALTER FUNCTION dbo.f_splite --測驗資料
提示什么錯誤?
uj5u.com熱心網友回復:
參考 6 樓 weixin_42101800 的回復: Quote: 參考 3 樓 Hello World, 的回復: SELECT p.id, p.[3], p.[2], p.[1] from (SELECT a.id,
最新版本系統自帶有個string_split函式,可以不用自定義
uj5u.com熱心網友回復:
參考 7 樓 二月十六 的回復: Quote: 參考 4 樓 weixin_42101800 的回復: Quote: 參考 1 樓 二月十六 的回復: ALTER FUNCTION dbo.f_splite --測驗資料 參考 7 樓 二月十六 的回復: Quote: 參考 4 樓 weixin_42101800 的回復: Quote: 參考 1 樓 二月十六 的回復: ALTER FUNCTION dbo.f_splite --測驗資料 uj5u.com熱心網友回復:
參考 8 樓 Hello World, 的回復: Quote: 參考 6 樓 weixin_42101800 的回復: Quote: 參考 3 樓 Hello World, 的回復: SELECT p.id, p.[3], p.[2], p.[1] from (SELECT a.id, uj5u.com熱心網友回復:
參考 9 樓 weixin_42101800 的回復: Quote: 參考 7 樓 二月十六 的回復: Quote: 參考 4 樓 weixin_42101800 的回復: Quote: 參考 1 樓 二月十六 的回復: ALTER FUNCTION dbo.f_splite --測驗資料 參考 7 樓 二月十六 的回復: Quote: 參考 4 樓 weixin_42101800 的回復: Quote: 參考 1 樓 二月十六 的回復: ALTER FUNCTION dbo.f_splite --測驗資料 uj5u.com熱心網友回復:
SQL Server2008也是支持Cross Apply的,你的自定義函式確定建立了?
uj5u.com熱心網友回復:
看看這個資料庫的兼容性是多少
uj5u.com熱心網友回復:
參考 11 樓 二月十六 的回復: Quote: 參考 9 樓 weixin_42101800 的回復: Quote: 參考 7 樓 二月十六 的回復: Quote: 參考 4 樓 weixin_42101800 的回復: Quote: 參考 1 樓 二月十六 的回復: ALTER FUNCTION dbo.f_splite --測驗資料 參考 7 樓 二月十六 的回復: Quote: 參考 4 樓 weixin_42101800 的回復: Quote: 參考 1 樓 二月十六 的回復: ALTER FUNCTION dbo.f_splite --測驗資料 uj5u.com熱心網友回復:
看著不應該報錯,是完全復制的嗎
uj5u.com熱心網友回復:
參考 15 樓 二月十六 的回復: 看著不應該報錯,是完全復制的嗎 uj5u.com熱心網友回復:
參考 16 樓 weixin_42101800 的回復: Quote: 參考 15 樓 二月十六 的回復: uj5u.com熱心網友回復:
參考 17 樓 二月十六 的回復: Quote: 參考 16 樓 weixin_42101800 的回復: Quote: 參考 15 樓 二月十六 的回復: uj5u.com熱心網友回復:
參考 17 樓 二月十六 的回復: Quote: 參考 16 樓 weixin_42101800 的回復: Quote: 參考 15 樓 二月十六 的回復: uj5u.com熱心網友回復:
參考 19 樓 weixin_42101800 的回復: Quote: 參考 17 樓 二月十六 的回復: Quote: 參考 16 樓 weixin_42101800 的回復: Quote: 參考 15 樓 二月十六 的回復: uj5u.com熱心網友回復:
參考 20 樓 二月十六 的回復: Quote: 參考 19 樓 weixin_42101800 的回復: Quote: 參考 17 樓 二月十六 的回復: Quote: 參考 16 樓 weixin_42101800 的回復: Quote: 參考 15 樓 二月十六 的回復:
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/107466.html
標籤:基礎類
上一篇:求指點,我不知道錯哪了
下一篇:sql觸發器