背景
現在主流的資料庫系統的故障恢復邏輯都是基于經典的ARIES協議,也就是基于undo日志+redo日志的來進行故障恢復,redo日志是物理日志,一般采用WAL(Write-Ahead-Logging)機制,所以也稱redo日志為wal日志,redo日志記錄了所有資料的變更,undo日志是邏輯日志,記錄了所有操作的前鏡像,方便例外時進行回滾,用戶在提交事務時,只要確保寫redo日志成功即可,并不需要對應的資料頁也實時落盤,這套機制的基本思想是利用空間換時間,用戶事務的更新實際上在資料頁和redo日志中記錄了兩份,傳統的資料庫存盤引擎都是基于B+Tree來組織資料頁,因此刷資料頁是離散小塊IO,而寫redo是順序IO,對磁盤介質更友好,而且OLTP場景下,業務對RT(ResponseTime)也比較敏感,所以這套機制非常流行,
redo日志是保證資料不丟的關鍵因素,而且每個事務在提交時,都需要寫redo日志,可想而知這塊資源競爭是非常激烈的,這個問題是所有基于WAL機制的資料庫系統個的共性問題,下文的討論以MySQL為例,并以此說明MySQL8.0在這塊的優化,
最初的redo日志機制
在MySQL的日志系統中,這里討論的是InnoDB引擎,mtr(mini-transaction)是最小事務單位,一個用戶事務會對應若干個mtr,mtr保證內部操作的原子性,比如B+Tree分裂操作,必需在一個mtr中,用戶執行操作時,會同時更新資料頁和寫redo日志,mtr是redo日志的載體,存在每個會話的私有變數中,mtr提交時,會將本地redo日志拷貝到全域的log_buffer中,為了保證日志有序性,需要加鎖來訪問log_buffer,這把鎖就是log_sys_t::mutex,所以這個鎖競爭非常激烈,在這個鎖保護下,除了要將本地日志拷貝到全域buffer,還需要將資料頁加入了flush_list,供后臺執行緒刷臟,輔助資料庫檢查點持續往前推進,檢查點一方面能控制全域的redo日志檔案大小,讓日志具備回圈復用的能力;另一方面,也能提高故障恢復速度,因為故障恢復的本質就是利用落盤的redo日志來恢復沒有落盤的資料頁,所以最開始(MySQL5.1)只有一把鎖,大并發場景下,這個鎖競爭非常激烈,MySQL在多核系統下也無法提升性能,
拆分log_sys_t::mutex
既然鎖競爭壓力大,那么最直觀的想法就是拆鎖,首先按功能拆分,剛剛說到,在mutex保護下,做了兩件事,一件是拷貝本地日志到全域log_buffer;另一件事是將事務修改的page加入到flush_list,日志系統將這兩件事解耦,引入了log_sys_t::flush_order_mutex,減少log_sys_t::mutex的持鎖時間,將本地日志拷貝到log_buffer后,就可以釋放log_sys_t::mutex,這樣拷貝日志的執行緒和處理flush_list的執行緒就可以并發起來,
除了這個,日志系統還引入了雙log_buffer機制,這個主要是為了解決全域log_buffer的讀寫并發問題,一個buffer用于拷貝日志到log_buffer,另一個log_buffer則用于讀取,寫入到日志檔案,當需要讀log_buffer時,則可以切換log_buffer的角色,這樣就消除了寫日志檔案帶來的訪問log_buffer鎖競爭,
但是,拆分完鎖后,多個用戶執行緒仍然需要在log_sys_t::mutex保護下,串行寫log_buffer,由于memcpy操作比較重,所以這個鎖競爭仍然非常激烈,需要優化,
消除log_sys_t::mutex
為了解決log_sys_t::mutex并發問題,MySQL 8.0引入了新的log_buffer機制,借助于lock_free的link_buf資料結構,利用原子變數來進行預占位,這樣多個執行緒就能并發寫redo,這種機制帶來了一個空洞問題,因為寫日志速度不一樣,可能導致后占位(lsn較大)的執行緒先寫完,但是我們寫日志執行緒肯定是不能將帶有空洞的buffer寫到日志檔案,因此會維護一個滑動視窗,即最小的連續的lsn:buf_ready_for_write_lsn,寫日志執行緒會不斷的檢查 link_buf變數recent_written,然后寫日志,推進buf_ready_for_write_lsn,
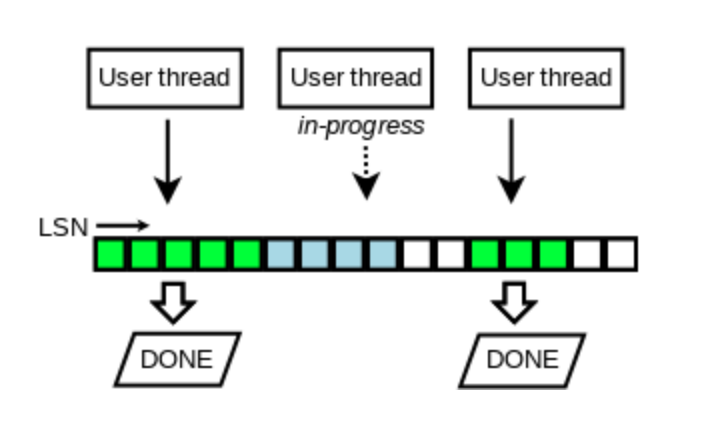
前面我們提到了系統中有兩把鎖,log_sys_t::mutex和log_sys_t::flush_order_mutex,通過占位方式,解決了寫log_buffer的問題,那么如何解決將臟頁有序加入到flush_list的問題呢?MySQL 8.0實作中仍然借助于link_buf資料結構,原來要求是加入flush_list的資料頁的oldest_modification_lsn一定是遞增的,這里順便說下oldest_modification_lsn的含義,oldest_modification_lsn是指page第一次被修改后,mtr在log_sys_t中分配的lsn,即使這個page在flush下去之前,又在記憶體中被修改過N次,仍然以第一次修改的lsn為準,這樣做的目的是,確保資料頁記憶體的修改與檢查點推進能對應上,避免檢查點推進了,但對應的臟頁可能還未刷盤,造成資料丟失問題,
由于是并發亂序寫log_buffer,那么無法保證按lsn遞增有序加入到flush_list,也就無法推進檢查點,MySQL 8.0通過限制大于一定閥值L的lsn加入到flush_list做為權衡,假設當前flush_list的lsn最大值為M,那么只有在M值與當前執行緒lsn相差范圍在L以內時,才將臟頁寫入flush_list,同樣的,推進M,也依賴于link_buf變數recent_closed,這種策略本質上放寬了之前對于flush_list中對于LSN全域有序的限制到L范圍內的有序,
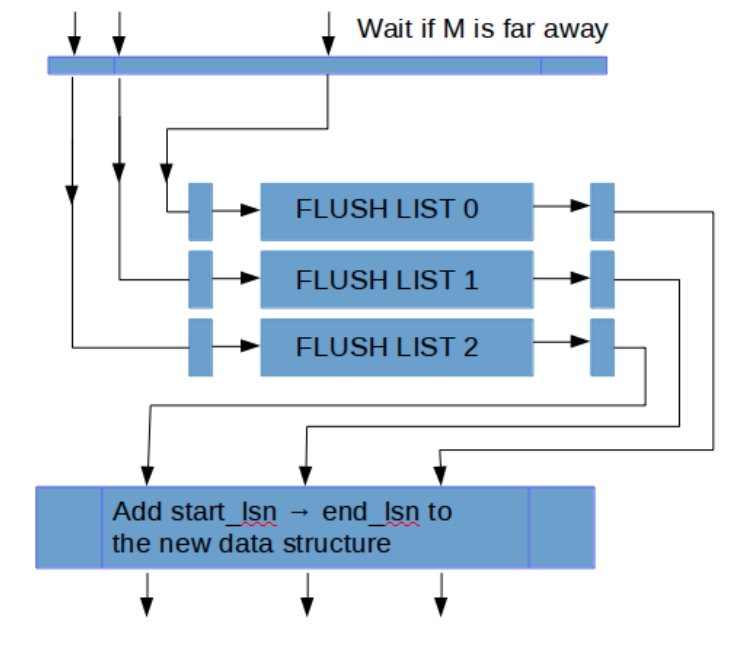
除了日志系統變成lock free,MySQL8.0還將寫日志執行緒從用戶執行緒中拆分出來,有單獨的log writer執行緒和log flusher后臺執行緒來處理寫日志和sync日志,原來的寫日志方式是,大家隨機group-commit,由一個執行緒負責write/flush日志,其它執行緒等待,這種模式下group的大小比較隨機,拆分后,處理更靈活,batch大小也更好控制,而且對于flush_log_at_trx_commit!=1的場景,只需要等log writer的通知即可,
總結
從MySQL日志系統優化的演程序序來看,始終是圍繞鎖log_sys_t::mutex展開, 從最初的按功能拆分出log_sys_t::flush_order_mutex,到按讀寫拆分實作為雙log_buffer,以及最新的MySQL 8.0利用無鎖機制徹底去掉這把鎖,顯然MySQL的并發能力是越來越強的,這種優化“套路”其實是比較樸素通用的,對于一個新的系統,通過一把大鎖能簡化并發邏輯,優先保證正確性,在系統慢慢演程序序中,我們可以按功能拆分鎖,緩解鎖沖突壓力;如果某把鎖處于核心鏈路,而且又成為瓶頸,那么再想辦法繼續拆,或者實作為無鎖,徹底解決并發沖突問題,目的只有一個就是充分利用多核CPU資源,然執行緒多干活,減少回應時間的同時,拉高吞吐量,而不是都等待空閑著,文章中并沒有涉及更多關于MySQL8.0日志系統優化的細節,官方檔案已經寫地足夠好,大家可以詳細看看,
參考檔案
https://mysqlserverteam.com/mysql-8-0-new-lock-free-scalable-wal-design/
http://mysql.taobao.org/monthly/2018/07/01/
https://yq.aliyun.com/articles/592215?utm_content=m_49932
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/109152.html
標籤:MySQL
上一篇:連接 sql