表結構這樣的
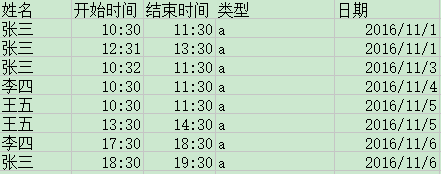
結果要這樣

能直接用SQL就寫出來的嗎?
uj5u.com熱心網友回復:
with t as
(select '張三' names,'10:30' btime,'11:30' etime,'a' type,'2016/11/1' rq from dual union all
select '張三' names,'12:30' btime,'13:30' etime,'a' type,'2016/11/1' rq from dual union all
select '張三' names,'10:32' btime,'11:30' etime,'a' type,'2016/11/3' rq from dual union all
select '張三' names,'18:30' btime,'19:30' etime,'a' type,'2016/11/4' rq from dual)
select a.names,a.btime,a.etime,a.type,b.btime,b.etime,b.type from
(select m.*,row_number()over(partition by names order by rq,btime) rn
from t m where rq='2016/11/1') a
full outer join
(select m.*,row_number()over(partition by names order by rq,btime) rn
from t m where rq='2016/11/3') b
on a.names = b.names and a.rn = b.rn
;
很麻煩,給你一個思路,幫你寫了2天的
uj5u.com熱心網友回復:
很麻煩,給你一個思路,幫你寫了2天的。你必須每一天都創建一個子查詢
即(select m.*,row_number()over(partition by names order by rq,btime) rn
from t m where rq='2016/11/1') 這樣,然后關聯第二個子查詢 rq='2016/11/2'的,用全外連接關聯,a.names = b.names and a.rn = b.rn匹配。
另外只能2天用一個全外連接,如果你再接著連接第3天的,會出現一些問題的。這樣你就需要大量的子查詢和嵌套。
uj5u.com熱心網友回復:
餓。是超級麻煩哦,不行只能寫代碼的時候嵌套回圈了,只是感覺效率很低,一個用戶的資訊就要31天資訊,就要查31次。。媽媽呀。
100個用戶會不會瘋掉了
uj5u.com熱心網友回復:
建立個臨時表對表遍歷一遍,把資料插入到臨時表中
然后直接對臨時表進行查詢統計
uj5u.com熱心網友回復:
臨時表怎么設計表結構便于出統計效果呢?能指導下嗎
uj5u.com熱心網友回復:
臨時表的結構就是你的報表結構,直觀明了
uj5u.com熱心網友回復:
以上是型別考勤相關的表,不可用姓名關聯,可能存在重名的情況,須有一張員工表,用員工ID關聯,下表中將員工ID代入,僅供參考,只寫了五天的資料--建表
create table test_xz
(
id varchar(20),
name varchar(20),
start_time varchar(20),
end_time varchar(20),
type varchar(20),
date_1 varchar(20)
)
--準備資料
insert into test_xz values('1001','張三','10:30','11:30','a','2016/11/1');
insert into test_xz values('1002','張三','12:31','13:30','a','2016/11/1');
insert into test_xz values('1001','張三','10:32','11:31','a','2016/11/3');
insert into test_xz values('1003','李四','10:30','11:30','a','2016/11/4');
insert into test_xz values('1004','王五','10:30','11:30','a','2016/11/5');
insert into test_xz values('1005','王五','13:30','14:30','a','2016/11/5');
commit;
--查詢
select t.id,
min(t1.start_time) 一號開始,
max(t1.end_time) 一號結束,
max(t1.type),
min(t2.start_time) 二號開始,
max(t2.end_time) 二號結束,
max(t2.type),
min(t3.start_time) 三號開始,
max(t3.end_time) 三號結束,
max(t3.type),
min(t4.start_time) 四號開始,
max(t4.end_time) 四號結束,
max(t4.type),
min(t5.start_time) 五號開始,
max(t5.end_time) 五號結束,
max(t5.type)
from (select id, start_time, end_time, type from test_xz) t
left join (select id, start_time, end_time, type
from test_xz
where date_1 = '2016/11/1') t1 --1號資料
on t.id = t1.id
left join (select id, start_time, end_time, type
from test_xz
where date_1 = '2016/11/2') t2 on t.id = t2.id --2號資料
left join (select id, start_time, end_time, type
from test_xz
where date_1 = '2016/11/3') t3 on t.id = t3.id --3號資料
left join (select id, start_time, end_time, type
from test_xz
where date_1 = '2016/11/4') t4 on t.id = t4.id --4號資料
left join (select id, start_time, end_time, type
from test_xz
where date_1 = '2016/11/5') t5 on t.id = t5.id --5號資料
group by t.id
order by t.id;
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/112093.html
標籤:基礎和管理
上一篇:求助oracle大神
下一篇:執行報錯,求指教