select LEFT(pp.add_time,4) date,
sum( case when pp.license_type='5' then 1 else 0 end) 'regist5',
sum( case when pp.license_type='7' then 1 else 0 end) 'regist7',
sum( case when pp.license_type='1002' then 1 else 0 end) 'regist1002',
sum( case when pp.license_type='1201' then 1 else 0 end) 'regist1201',
sum( case when pp.license_type='1202' then 1 else 0 end) 'regist1202'
from t_person_plan pp where pp.plan_status not in(6,7,9) and concat(LEFT(pp.dept_id,4),'00')='320200'
and left(pp.add_time,4)<'2017' GROUP BY LEFT(pp.add_time,4)
實作的結果如下圖:
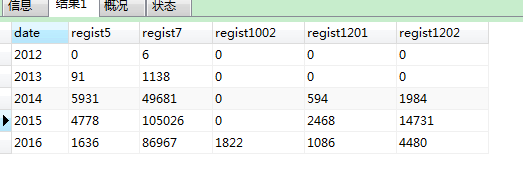
請教這個mysql怎么優化比較好呢?將近300萬的資料,以后資料還會不斷增多。謝謝。
uj5u.com熱心網友回復:
這么多資料分組肯定快不了得預先提取一些粒度比較大的資料到統計表里面 然后在統計表里再進行統計
uj5u.com熱心網友回復:
滿足條件的資料量如果比較少的話, 那么你的 where 條件中的兩個計算,可以做成計算列并加索引如果占比大的話,優化的余地不大,但計算列也可以提升一些性能
uj5u.com熱心網友回復:
請教下,怎么叫計算列?你可以舉個例子,寫個簡單的sql嗎?謝謝
uj5u.com熱心網友回復:
這是個方法,我在考慮要不要寫個存盤程序。把統計資料放到一個表里。這樣也好很多
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/113836.html
標籤:MySQL
上一篇:求大神幫我寫個sql或存盤程序:查詢出表中所有的未用到的欄位(這個欄位的所有值都為null)
下一篇:VFP9報表列印換行時漢字亂碼