陳述句是:
select a.*, b.order_item_id, b.service_offer_id
from TEM_KD_XY1 a
join crmdb.l_order_item b
on a.offer_comp_inst_id = b.order_item_obj_id
where b.finish_time > sysdate -365
and b.lan_id = 3
執行計劃是:
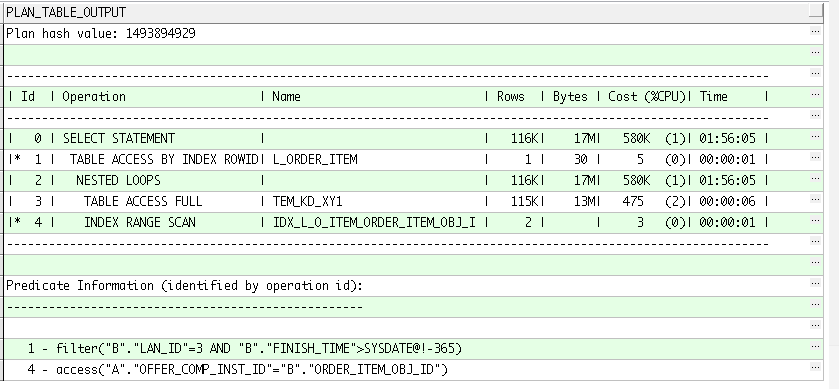
此外 a.offer_comp_inst_id = b.order_item_obj_id 這兩個條件的欄位都已經建立了索引,請大家幫我分析下!謝謝!
uj5u.com熱心網友回復:
你這兩個表都有多大的資料量?另外,生成一個trace檔案看看吧uj5u.com熱心網友回復:
一個表4億條記錄,一個表10萬多條記錄
uj5u.com熱心網友回復:
幾點建議:第一:在from中,將小表作為基礎表,也就是放到最后面。
第二:開trace看一下具體執行計劃的生成方式:
alter session set events '10053 trace name context forever , level 1; --打開10053事件
explain for 具體sql; --解釋sql陳述句
alter session set events '10053 trace name context off'; --關閉10053事件
查看trace檔案的位置:
--DBA身份運行以下陳述句
select c.value || '/' || d.instance_name || '_ora_' || a.spid || '.trc' || case
when e.value is not null then
'_' || e.value
end trace
from v$process a, v$session b, v$parameter c, v$instance d, v$parameter e
where a.addr = b.paddr
and b.audsid = userenv('sessionid')
and c.name = 'user_dump_dest'
and e.name = 'tracefile_identifier';
uj5u.com熱心網友回復:
表TEM_KD_XY1 a 在全表搜索,有沒有在欄位offer_comp_inst_id上建立索引?uj5u.com熱心網友回復:
你說你在a.offer_comp_inst_id上建立了索引,但是執行計劃沒走該索引,TEM_KD_XY1建立索引后是否被分析過?該欄位值重復率如何?crmdb.l_order_item表有4億?在finish_time上是否有合適的索引?是否能用到磁區來優化?
uj5u.com熱心網友回復:
發現原來臨時表TEM_KD_XY1是全表都要參與比較的,所以該表是否建立索引沒什么意義了。
那么大表是否有磁區?兩表關聯時,如果無法使用磁區,估計效率是不會快的。
另外,SQL的運行效率和“SQL是否簡單”沒有什么關系
uj5u.com熱心網友回復:
finish_time 有索引,我查了一下,crmdb.l_order_item 這個4億記錄的表沒有磁區
uj5u.com熱心網友回復:
現在查一次多長時間?回傳結果多少條?uj5u.com熱心網友回復:
你回傳的資料也蠻多的lan_id 有索引嗎
可以考慮lan_id ,finish_time 組合索引
另外,考慮表磁區,PARALLEL 試試
uj5u.com熱心網友回復:
全部查詢出來 4個小時,回傳幾十萬條記錄
uj5u.com熱心網友回復:

轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/116404.html
標籤:基礎和管理
上一篇:求救!在線等 謝謝各位大神了!!