有兩張表,要從一張表按照一定的條件給第二張表填資料,第二張表只有有限行,即要用兩個游標雙重回圈,從第一張表中讀取一個資料,對第二個表進行判斷,滿足條件就寫入,沒有就跳出。以此類推,直到第二張表寫滿停止。現在我不知道怎么寫第一個游標的結束陳述句,求大神!!!!
uj5u.com熱心網友回復:
不是很明白,為什么第二張表是有限行?如果做了限制,當超過有限行應該會報錯,所有是否可以用EXCEPTION來處理呢
uj5u.com熱心網友回復:
把具體的情況再描述清楚一些吧~uj5u.com熱心網友回復:
因為其實可以認為第二張表是有條件的,第一張表中的資料滿足這個條件才會寫入,打個比方,第一張表是很多的信,第二張表是不同的人,不同人接受不同的信,當所有人都收到信并在看信時,就沒有必要把接下來的信一個一個判斷了,因為人都已經在看信了,所以就不繼續分發,結束回圈,等到某個人看完信才會繼續分發。不知道這個比喻好不好理解。
uj5u.com熱心網友回復:
樓上說明了
uj5u.com熱心網友回復:
那你加個標志來說明表是否已滿應該就可以了呀
uj5u.com熱心網友回復:
不用定義兩個游標,定義一個就可以了;回圈第二張表;
uj5u.com熱心網友回復:
但是第一張表是有順序的,一定要從第一條資料開始檢索
uj5u.com熱心網友回復:
能稍微說具體一點嗎?因為不一定是最后一行插入資料就結束,有可能中間的行會空出來繼續檢索
uj5u.com熱心網友回復:
你不妨給出一些示例資料,和你的預期結果,沒準能更快的解決你的問題;
uj5u.com熱心網友回復:
如這個圖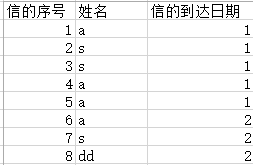 現在有八封信,按照信的到達時間進行排序,但是收件人的表只有三個人
現在有八封信,按照信的到達時間進行排序,但是收件人的表只有三個人 。因為我在第一張表中已經排序過了,所以先取出第一條資料,在2表中遍歷,找出收件人為a,插入資料,然后再取出第二條資料在第2張表中遍歷, 插入收件人為s的行中。但是在取出第三個資料遍歷的時候發現收件人已經被占用,所以并不插入,繼續向下直到第二張表全部被插入資料或者第一張表的資料遍歷完才結束,現在就是不知道全部被插入跳出回圈那段該怎么寫
。因為我在第一張表中已經排序過了,所以先取出第一條資料,在2表中遍歷,找出收件人為a,插入資料,然后再取出第二條資料在第2張表中遍歷, 插入收件人為s的行中。但是在取出第三個資料遍歷的時候發現收件人已經被占用,所以并不插入,繼續向下直到第二張表全部被插入資料或者第一張表的資料遍歷完才結束,現在就是不知道全部被插入跳出回圈那段該怎么寫
uj5u.com熱心網友回復:
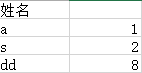 這是結束回圈時的結果
這是結束回圈時的結果
uj5u.com熱心網友回復:
給了一點簡單資料,求指教
uj5u.com熱心網友回復:
-- 這個不用使用游標 ,一個子查詢就可以了
Connected to Oracle Database 11g Enterprise Edition Release 11.2.0.2.0
Connected as test@MSGDE
SQL>
SQL> col id format a10;
SQL> col name format a10;
SQL> col rq format a10;
SQL> create table a(id int, name varchar(10), rq int);
Table created
SQL> create table b(id int, name varchar(10), rq int);
Table created
SQL> begin
2 insert into a values(1,'a',1);
3 insert into a values(2,'s',1);
4 insert into a values(3,'s',1);
5 insert into a values(4,'a',1);
6 insert into a values(5,'a',1);
7 insert into a values(6,'a',2);
8 insert into a values(7,'s',2);
9 insert into a values(8,'dd',2);
10 end;
11 /
PL/SQL procedure successfully completed
SQL> insert into b
2 select * from a
3 where not exists(select * from a x where a.name =x.name and x.id < a.id);
3 rows inserted
SQL> select * from b order by id ;
ID NAME RQ
---------- ---------- ----------
1 a 1
2 s 1
8 dd 2
SQL> drop table a purge ;
Table dropped
SQL> drop table b purge ;
Table dropped
SQL>
uj5u.com熱心網友回復:
你的邏輯有問題,為什么不把T2表放在外回圈,回圈去找T1表呢
uj5u.com熱心網友回復:
這是求分組最小值,何必多次回圈呢?select distinct b.name,first_value(a.id) over (partition by a.name order by a.id) from a,b where a.name=b.name;
或
select distinct b.name,min(a.id) over (partition by a.name order by a.id) from a,b where a.name=b.name;
uj5u.com熱心網友回復:
一個分析函式就搞定了 ROW_NUMER ... OVER要是下次遍歷時,排除已看過的郵件,則可以在第一張表里加上一個閱讀標記
uj5u.com熱心網友回復:
還沒看到分析函式,學習了!轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/116410.html
標籤:開發
下一篇:dba未來的前景如何