先從上次遇到的一個執行計劃相關的疑問入手,類似于select count(1) from table的查詢,可以在即某些較小欄位上的索引進行掃描來替代全表掃描來實作count優化,這是一個MySQL中傳統的優化套路,但是在postgresql中類似場景總是會走全表掃描而不是預期的索引掃描,為什么同樣的套路搬到Postgresql上就不好使了?這是一個postgresql中一個典型的MVCC機制造成的,應該是一個比較有代表性的問題了,看起來是十年前就有人問過類似的問題了https://dba.stackexchange.com/questions/2070/postgresql-count-uses-a-sequential-scan-not-index 因此經驗跟教條之間,其實很近很近,不能輕易“復印”的以往的經驗,
 Postgresql MVCC下的資料可見性
這里涉及到一個資料可見性的問題
Postgresql在資料修改時通過保留資料的歷史版本來實作MVCC,也即不同的事務要看到同一條資料的不同版本,這需要依次保留不同版本的問題,
Postgresql MVCC下的資料可見性
這里涉及到一個資料可見性的問題
Postgresql在資料修改時通過保留資料的歷史版本來實作MVCC,也即不同的事務要看到同一條資料的不同版本,這需要依次保留不同版本的問題,不同的資料庫的MVCC機制實作是不同的,MySQL或者Oracle中是通過將歷史記錄寫入undo表空間實作,Postgresql是直接在當前頁面保留這個資料的歷史版本, 這里暫時拋開Postgresql的HOT優化機制,粗略來看一條update或者delete發生時是如何實作多版本的, 資料修改操作:將某一行的data欄位從a修改為b
可以直觀地想象一下Postgresql中修改一條記錄事生成的“undo”記錄的實作,(當然除此之外這個undo記錄與xlog有關)
 其程序就是update的時候保留老的記錄,重新寫入一條新紀錄的, 通過不同的事務Id決定不同的事務可以看到修改前或者修改后的記錄
其程序就是update的時候保留老的記錄,重新寫入一條新紀錄的, 通過不同的事務Id決定不同的事務可以看到修改前或者修改后的記錄資料洗掉操作:這里示例洗掉上面修改后的記錄的程序
洗掉操作是類似的一個程序,僅標記原始記錄被洗掉(set t_xmax),但此時記錄還保存在原地,
 這里就存在2個問題:
1、誰&什么時候&什么條件下,清理歷史版本
這里就存在2個問題:
1、誰&什么時候&什么條件下,清理歷史版本大量的歷史版本會造成表膨脹的問題,不過目前看來應該不是問題,絕大多數情況下后臺清理行程完全可以hold的住,
其實這個問題源自于MVCC需要保留不同版本資料的機制造成的,是一個支持MVCC的共性問題,MySQL中也有類似問題,MySQL 5.7之前undo 表空間膨脹且無法裝直接收縮,業內也為此整出來各種奇淫巧技來處理該問題、所以某些問題是必須要經歷或者說面對的,沒有絕對好或者絕對壞的方法,
參考前面統計新資訊更新時涉及到的vacuum自動化機制:https://www.cnblogs.com/wy123/p/13347176.html 2、如何解決索引鍵無法“直接”感知資料行的變化(索引上沒有行版本資訊)
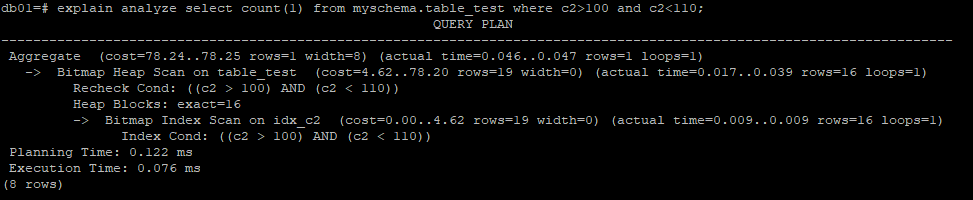
多版本的只能在資料行級別體現,而無法在索引樹中體現出來,也就是說索引上是沒有版本資訊的,洗掉一條記錄會標記一條記錄洗掉前的版本,以及將新寫入一個條記錄并標記為洗掉,這個程序可以認為該表上的索引是無感知的,或者對應的索引鍵是無法直接知道“我對應的記錄被洗掉了”,這一點是postgresql所特有的,如果索引想知道其某個鍵值對應的資料行有沒有發生變化或者被洗掉,是需要結合clog,也就是commit log(新版本中叫xact log)的,通過索引鍵訪問資料行的時候,需要經過xlog做一次驗證,才能決定該索引鍵是否發生了變換(增刪改), 所以現在可以想明白,為什么在count(1) 不會通過僅掃描索引就可以完成的了吧,因為在計算總行數的程序中,必須要通過“回表”重新驗證該記錄是否當當前事務可見, “回表”這一點如何體現?如下demo select count(c2) from myschema.table_test where c2>100 and c2<103;
可以發現其執行程序中雖然是index only scan,但Heap Fetches標明依舊進行了回表(驗證索引上符合條件資料的可見性),因此這里的執行計劃顯式的index only scan并不合適,
 此外隨著資料范圍的增加,優化器開始采用bitmap scan的方式來執行,其目的只有一個:回表進行資料可見性的檢查(Heap Blocks)
此外隨著資料范圍的增加,優化器開始采用bitmap scan的方式來執行,其目的只有一個:回表進行資料可見性的檢查(Heap Blocks)
 上面兩種情況都是一個小范圍的count,換成一個大范圍或者全表的count,如果每次這么回表(Heap Fetches)或者bitmap index scan校驗就太低效了,那么就直接全表掃描還是相對比較直接的做法,
上面兩種情況都是一個小范圍的count,換成一個大范圍或者全表的count,如果每次這么回表(Heap Fetches)或者bitmap index scan校驗就太低效了,那么就直接全表掃描還是相對比較直接的做法,
 可見性映射
為了避免索引上沒有版本資訊導致的回表recheck,PostgreSQL對目標表的做了一個可見性映射,也就是說,如果一個頁面中存盤的所有元組都是可見的,PostgreSQL使用索引元組的鍵,就無須回表再次確認資料的可見性,否則,PostgreSQL將從索引元組中讀取指向的表元組,并檢查元組的可見性,這是一個常規的程序,需要注意的是,這個可見性映射是一個非精確值,參考http://www.postgres.cn/docs/9.4/storage-vm.html
其原理如下圖所示,當前事務通過一個visibility map元資料來判斷哪些資料頁面是可見的,哪些資料頁面(因為發生過修改)是不可見的,
可見性映射
為了避免索引上沒有版本資訊導致的回表recheck,PostgreSQL對目標表的做了一個可見性映射,也就是說,如果一個頁面中存盤的所有元組都是可見的,PostgreSQL使用索引元組的鍵,就無須回表再次確認資料的可見性,否則,PostgreSQL將從索引元組中讀取指向的表元組,并檢查元組的可見性,這是一個常規的程序,需要注意的是,這個可見性映射是一個非精確值,參考http://www.postgres.cn/docs/9.4/storage-vm.html
其原理如下圖所示,當前事務通過一個visibility map元資料來判斷哪些資料頁面是可見的,哪些資料頁面(因為發生過修改)是不可見的,
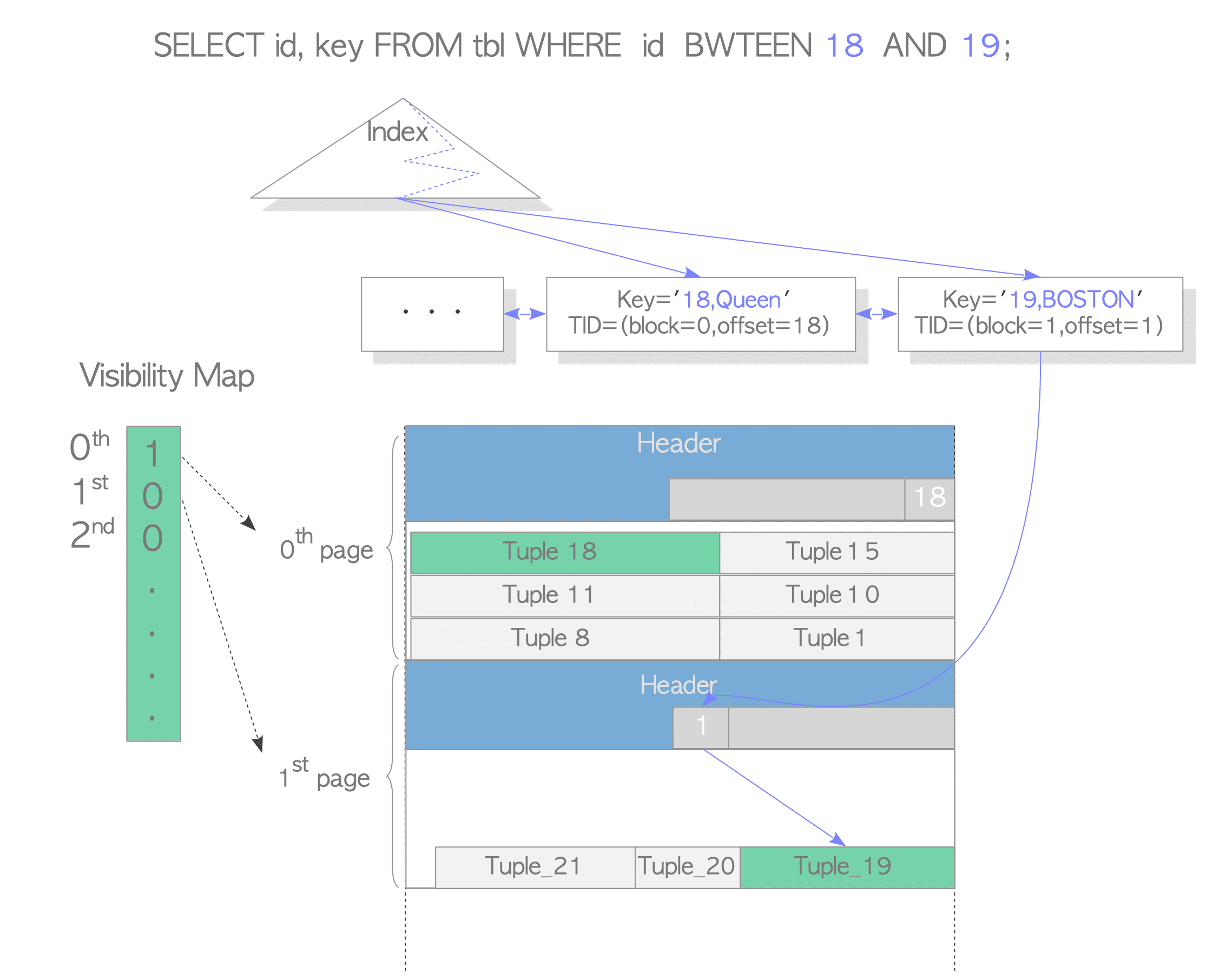 那么這個可見性映射visibility map如何直觀地體現出來?
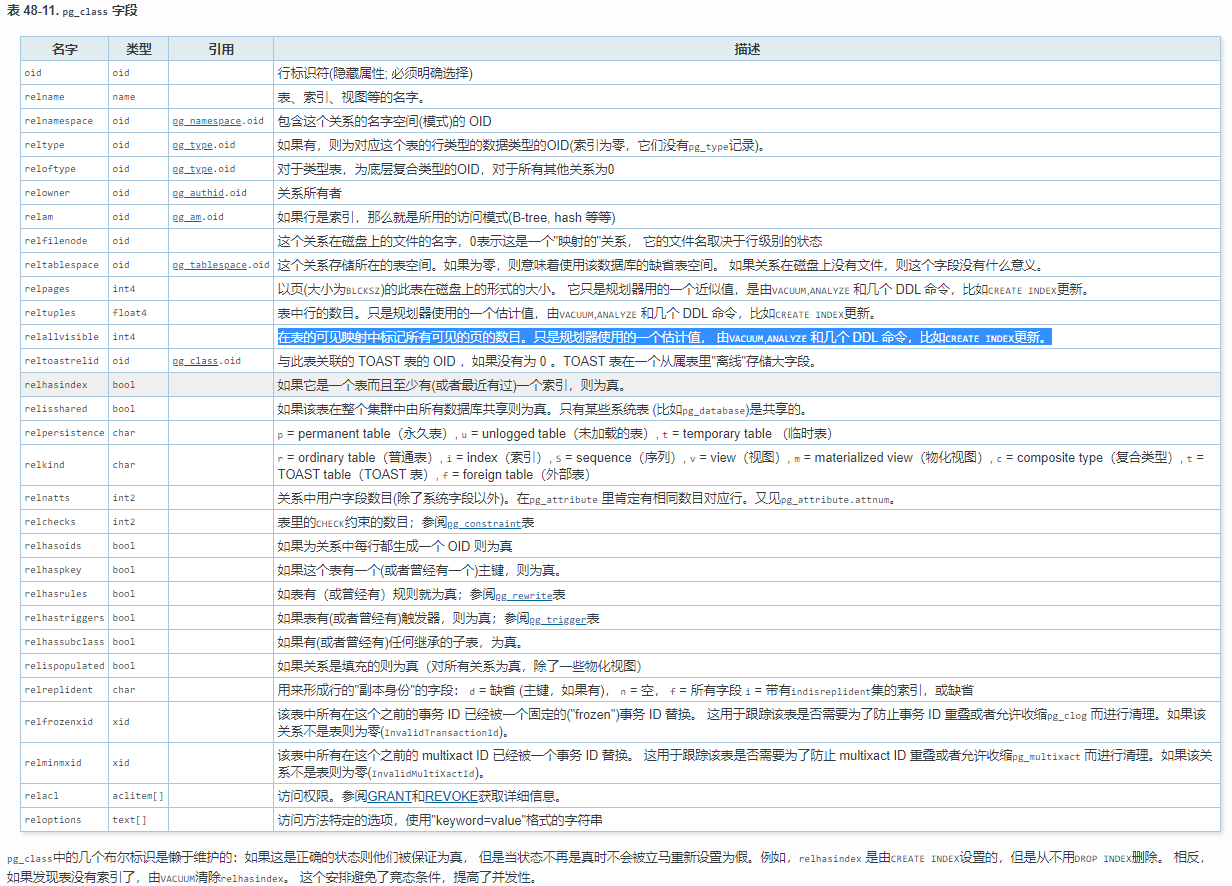
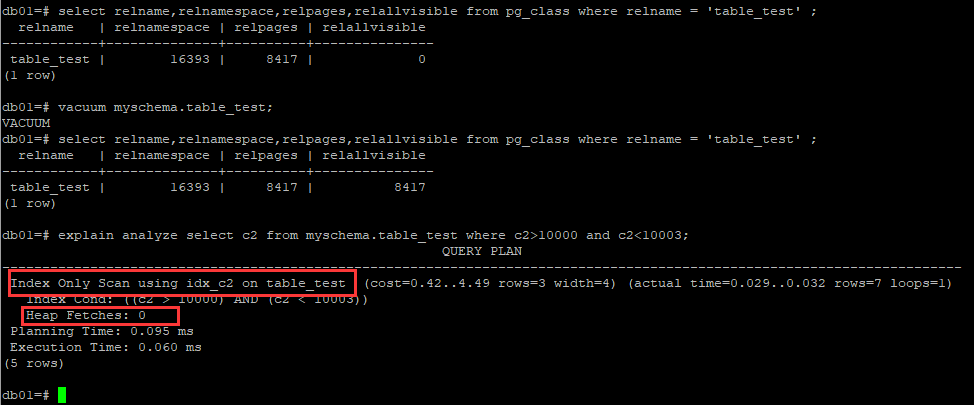
那么這個可見性映射visibility map如何直觀地體現出來?這里涉及到pg_class表的一個relallvisible欄位,其含義是在表的可見映射中標記所有可見的頁的數目,只是優化參考的一個估計值, 由VACUUM,ANALYZE 和幾個 DDL 命令,比如CREATE INDEX更新,
這個欄位的解釋見這里:http://www.postgres.cn/docs/9.4/catalog-pg-class.html
 在更新relallvisible欄位的資訊之后,再次執行select count(c2) from myschema.table_test where c2>100 and c2<103;因為可見性映射告訴優化器復合條件的資料頁面的資料都是可見的,因此這里就無須再次回表recheck了
在更新relallvisible欄位的資訊之后,再次執行select count(c2) from myschema.table_test where c2>100 and c2<103;因為可見性映射告訴優化器復合條件的資料頁面的資料都是可見的,因此這里就無須再次回表recheck了
Postgresql MVCC機制的優缺點
這里稱Postgresql的MVCC實作為“原地副本”,其特色是可實作快速回滾,一是因為事務修改前版本還在“原地”,二是依賴于事務的clog,事務的提交與否是通過事更新事務的clog中的標記位來實作的,因此事務的大小(修改1行和修改100W行資料),回滾時其代價是一樣的,其次,基于“原地”的資料行副本,相比將資料修改前的副本轉移到undo表空間需要來回移動資料,個人認為這樣原地操作效率會稍高一點,同時這也是其缺點,大量的資料修改和洗掉,會造成表空間的膨脹,在vacuum回收之前會對加大讀操作的代價,同時,即便有vacuum回收這個不可見資料副本,也更容易造成存盤空間上的碎片,參考鏈接 http://www.interdb.jp/pg/pgsql07.html
https://blog.csdn.net/xiaohai928ww/article/details/103742744
http://www.postgres.cn/docs/9.4/routine-vacuuming.html
https://www.enmotech.com/web/detail/1/701/1.html
某些經驗可以重用,但是不可復印
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/1165.html
標籤:PostgreSQL
上一篇:PostgreSQL執行計劃概述