什么是索引
- 索引是對 資料庫中一列或者多列的值進行排序的一中結構,使用索引可以快速訪問資料庫中表的特定資訊,索引的一個主要的目的就是加快檢索表中資料,亦即能協助資訊搜索者盡快的找到符合限制條件的記錄的輔助資料結構,
- 簡單來說索引就是資料庫的目錄,
索引有什么作用
索引的最大作用就是加快資料庫的查詢速度,
索引為什么會加快查詢速度
資料庫在執行一條SQL陳述句的時候,默認的方式是根據搜索條件進行全表掃描,遇到匹配條件的就加入搜索結果集合,但若是遇到大資料量的查詢時,直接全表匹配的方式太慢了,這時候就需要用到索引,我們對某一欄位增加索引,查詢的時候就會先去索引串列中一次定位到特定值得行數,大大減少遍歷匹配的行數,所以可以明顯的增加查詢的速度,
索引的種類
- 主鍵索引:資料記錄里面不能有null,資料內容不能重復,在一張表里面不能有多個主鍵索引,
- 普通索引:使用欄位關鍵字建立的索引,主要是提高查詢速度,
- 唯一索引:欄位資料是唯一的,資料內容里面能否為null,在一張表里面,是可以添加多個唯一索引,
- 全文索引:在早起版本中只有myisam引擎支持全文索引,在innodb5.6后也支持全文索引,在MySQL中全文索引不支持中文,我們一般使用sphinx集合coreseek來實作中文的全文索引,
索引的創建(索引的例子)
執行Create Table陳述句時可以創建索引,也可以單獨用Create index或者 Alter Table來為表增加索引,
1. ALTER TABLE
ALTER TABLE用來創建普通索引、unique索引或者primary key索引,
ALTER TABLE table_name ADD INDEX index_name(column_list)
ALTER TABLE table_name ADD UNIQUE(column_list)
ALTER TABLE table_name ADD PRIMARY KEY(column_list)
- table_name:是要增加索引的表名,
- column_list:指出對哪些列進行索引,多列時各列之間用逗號分隔,
- index_name:可選,預設是,MySQL將根據第一個索引列賦一個名稱,
- ALTER TABLE允許在單個陳述句中更改多個表,因此可以在同時創建多個索引,
2. CREATE INDEX
CREATE INDEX可以創建普通索引和UNIQUE索引,
CREATE INDEX index_name ON table_name (column_list)
CREATE UNIQUE INDEX index_name ON table_name (column_list)
注: table_name 索引名不可選,
洗掉索引
可利用ALTER TABLE或DROP INDEX陳述句來洗掉索引,類似于CREATE INDEX陳述句,DROP INDEX可以在ALTER TABLE內部作為一條陳述句處理,語法如下,
DROP INDEX index_name ON talbe_name
ALTER TABLE table_name DROP INDEX index_name
ALTER TABLE table_name DROP PRIMARY KEY
- 前兩條陳述句是等價的,洗掉掉table_name中的索引index_name,
- 第3條陳述句只在洗掉PRIMARY KEY索引時使用,因為一個表只可能有一個PRIMARY KEY索引,因此不需要指定索引名,如果沒有創建PRIMARY KEY索引,但表具有一個或多個UNIQUE索引,則MySQL將洗掉第一個UNIQUE索引,
- 如果從表中洗掉了某列,則索引會受到影響,對于多列組合的索引,如果洗掉其中的某列,則該列也會從索引中洗掉,如果洗掉組成索引的所有列,則整個索引將被洗掉,
查看索引
show index from tblname;
show keys from tblname;
查詢結果各欄位解釋
| 欄位名 | 解釋 |
|---|---|
| Table | 表的名稱 |
| Non_unique | 如果索引不能包括重復詞,則為0,如果可以,則為1 |
| Key_name | 索引的名稱 |
| Seq_in_index | 索引中的列序列號,從1開始, |
| Column_name | 列名稱, |
| Collation | 列以什么方式存盤在索引中,在MySQL中,有值‘A’(升序)或NULL(無分類), |
| Cardinality | 索引中唯一值的數目的估計值,通過運行ANALYZE TABLE或myisamchk -a可以更新,基數根據被存盤為整數的統計資料來計數,所以即使對于小型表,該值也沒有必要是精確的,基數越大,當進行聯合時,MySQL使用該索引的機會就越大, |
| Sub_part | 如果列只是被部分地編入索引,則為被編入索引的字符的數目,如果整列被編入索引,則為NULL, |
| Packed | 指示關鍵字如何被壓縮,如果沒有被壓縮,則為NULL, |
| Null | 如果列含有NULL,則含有YES,如果沒有,則該列含有NO, |
| Index_type | 用過的索引方法(BTREE, FULLTEXT, HASH, RTREE), |
| Comment | 暫無資料 ··· |
MySQL中的索引
MyISAM索引
MyISAM引擎使用B+Tree 作為索引結構,葉節點的data域存放的是資料記錄的地址,
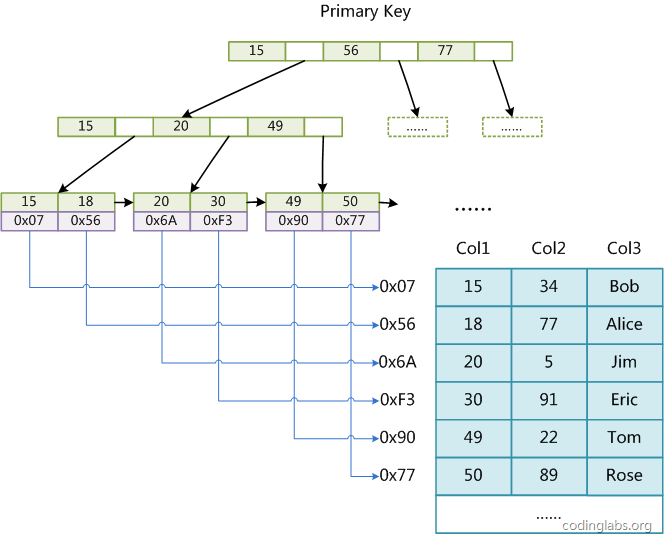
這里假設表中一共有三列,以Col1為主鍵則,
- MyISAM的索引檔案僅僅保存資料記錄的地址,
- MyISAM中,主索引和輔助索引在結構上沒有任何區別,只是主索引的key要求是唯一的,而輔助索引的key值可以是重復的,
如果在Col2上建立一個輔助索引,則此索引的結構如下,
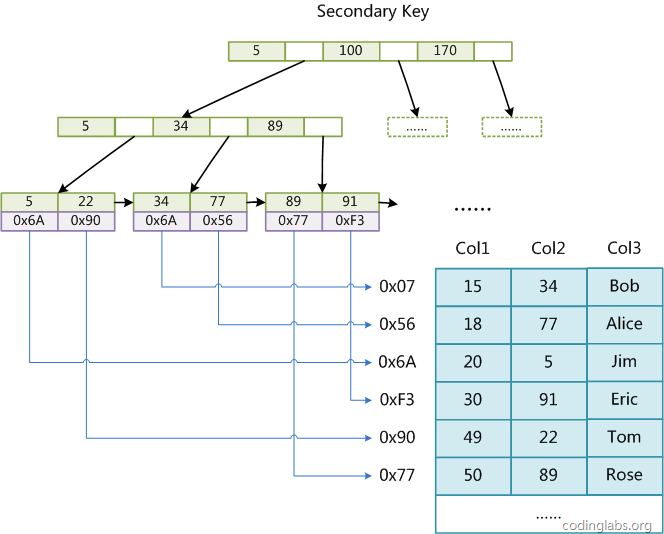
如圖,此索引同樣是一顆B+ 樹,data域保存資料記錄的地址,因此,MyISAM 中索引檢索的演算法為首先按照B+樹搜素演算法搜素索引,如果指定的Key存在,則取出其data域中的值,然后以data域中的值為地址,讀取相應資料記錄,
MyISAM的索引方式也叫做”非聚集“ 的,之所以這么稱呼是為了與INNODB的聚集索引區分,
InnoDB索引實作
InnoDB的索引也是使用B+Tree作為索引結構,但是具體的實作方式與MyISAM截然不同,
區別:
- InnoDB的資料檔案本身就是索引檔案,從上文知道,MyISAM索引檔案和資料檔案是分離的,索引檔案僅保存資料記錄的地址,而在InnoDB 中,表資料檔案本身就是按B+樹組織的一個索引結構,這棵樹的葉節點data域保存了完整的資料記錄,這個索引的key是資料表的主鍵,因此InnoDB表資料檔案本身就是主索引,
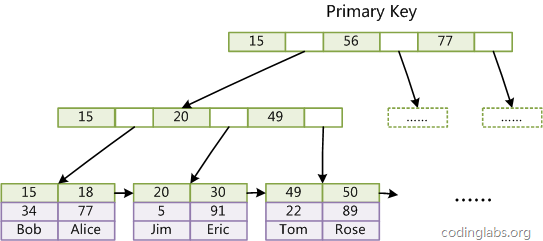
可以看到葉節點包含了完整的資料記錄,這種索引叫做聚集索引,因為InnoDB的資料檔案本身要按主鍵聚集,所以InnoDB要求表必須有主鍵(MyISAM可以沒有),如果沒有顯式指定,則MySQL系統會自動選擇一個可以唯一標識資料記錄的列作為主鍵,如果不存在這種列,則MySQL自動為InnoDB表生成一個隱含欄位作為主鍵,這個欄位長度為6個位元組,型別為長整形,
- InnoDB的輔助索引data域存盤相應記錄主鍵的值而不是地址,換句話說,InnoDB的所有輔助索引都參考主鍵作為data域,
如圖在Col3上的一個輔助索引:
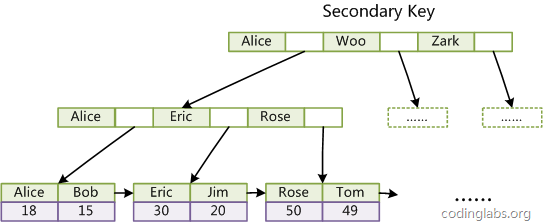
聚集索引這種實作方式使得按主鍵的搜索十分高效,但是輔助索引搜索需要檢索兩遍索引:首先檢索輔助索引獲得主鍵,然后用主鍵到主索引中檢索獲得記錄,
為什么說不建議使用過長的欄位作為主鍵?
答:因為所有輔助索引都參考主索引,過長的主索引會令輔助索引變得過大,
用非單調的欄位作為主鍵在InnoDB中不是個好主意
InnoDB資料檔案本身是一顆B+Tree,非單調的主鍵會造成在插入新記錄時資料檔案為了維持B+Tree的特性而頻繁的分裂調整,十分低效,而使用自增欄位作為主鍵則是一個很好的選擇,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/117939.html
標籤:MySQL
上一篇:Mysql+Keepalived雙主熱備高可用操作記錄
下一篇:Linux搭建MySQL主從