前言:
Java后端 第一步 認識SQL
1.認識SQL
1.1mysql 啟動方法
mysql 環境變數配置正確后,要使用管理員身份啟動 cmd
cmd1 :
net start mysql
service mysql restart
cmd2 :
mysql -u root -p
mysql -u root -p****** --或者直接輸入密碼
cmd3 : pwd = mysql_native_password
更改環境變數后配置MySQL,或者發現MySQL服務關閉了(不能從資料庫中查詢到東西)
把當前MySQL目錄\bin添加到系統變數,非用戶變數
進入mysql基礎目錄,修改 my.ini 檔案,base,data目錄均修改,可以不跳過密碼檢查
管理員模式進入cmd,\bin目錄下 mysqld -install

\bin目錄下 net start mysql

5.mysql -uroot -p**
可能需要重復配置比較費力,不建議改變原始路徑
1.2 sql 基本陳述句
1.2.1基本操作
sc delete mysql --洗掉所有配置 慎用create database xxx ; --創建一個資料庫
drop database xxxxx ; --洗掉資料庫的所有內容,包括原資料庫
show databases; --查看所有的資料庫
use xxxxxx; --切換xxxxxx資料庫
show tables; --查看資料庫中所有的表
describe xxx ; --查看xxxxxx資料庫中xxx表單的資訊
sqlyog operations : 選中ctrl+a---執行陳述句 左上角按鈕執行
飄號參考 sqlName.tableName
1.2.2創建表單 主鍵必須非空
CREATE TABLE `school`.`techer` ( `id` INT(10) NOT NULL COMMENT '教職工號', `name` VARCHAR(10) COMMENT '姓名', `age` INT(3) COMMENT '年齡', PRIMARY KEY (`id`) ) ENGINE=INNODB CHARSET=utf8 COLLATE=utf8_general_ci;
----初始化一個資料庫的表形狀
學習sql語法妙招:先用GUI 然后看GUI操作后的sql陳述句
1.3 sql基本資料型別
sql數值型別
tinyint 1 bit
smallint 2 bit
mediumint 3 bit
int 4 bit
bigint 8 bit
float 8 bit
decimal 字符型串浮點數 精確,精確,商用
sql字串型別
char 0~255
varchar 可變字符 0~65535
tinytext 2^8-1
text 2^16-1
sql時間日期
date YYYY-MM-DD
time HH:mm:ss
datetime YYYY-MMM-DD HH:mm:ss
timestamp 1970.1.1-now
year
sql null
無值 null 運算 null
1.4 sql欄位屬性

Unsigned :
- 無符號整數
- 宣告非負
zerofill :
- 不足的位數用0補全到 限定位數 eg.INT(10) 1->0000000001
自增
- 自動在上一條記錄上+1
- 唯一的主鍵 index 要子增 整數型別
非空 :
NULL
NOT NULL :如果不賦值 報錯
1.5 sql表單陳述句
show create database school --查看創建資料庫陳述句
show create table student --查看 student 資料表的定義陳述句
desc student --顯示表的結構
1.6 sql 中ENGINE INNODB和MYISAM 的區別
| MYISAM | INNODB | |
|---|---|---|
| 事務支持 | 不支持 | 支持 |
| 資料行鎖定 | 不支持 (表鎖) | 支持 (行鎖) |
| 外鍵約束 | 不支持 | 支持 |
| 全文索引 | 支持 | 不支持 |
| 表空間的大小 | 較小 | 較大 ,約為2倍 |
| 常規使用操作 | 節約空間 ,速度較快 | 安全性高,事務處理,多表多用戶操作 |
| 物理檔案上 | *.frm --表結構的定義檔案 ; *.MYD資料檔案(data) ; *.MYI 索引檔案 (index) | 在資料庫表中只有一個*.frm檔案,以及上級目錄下的ibdata1 檔案 |
物理空間的存盤位置 :
所有的資料庫檔案都存在data目錄下
設定資料庫表中的字符集編碼
CHARSET=utf8不設定的情況,會是mysql默認的字符集編碼 (不支持中文)
MySQL 的默認編碼是 Latin1
在my.ini 中配置 默認的編碼
character-set-server=utf8
1.7 sql的表單修改 (修改范式)
1.7.1表單內操作
改名規則 :
ALTER TABLE 舊表名 RENAME AS 新表名添加規則 :
ALTER TABLE 表名 ADD 欄位名 列屬性 [屬性]修改規則 :
ALTER TABLE 表名 MODIFY 欄位名 列屬性[屬性] ALTER TABLE 表名 CHANGE 舊欄位名 新欄位名 列屬性[屬性]洗掉規則(洗掉列) :
ALTER TABLE 表名 DROP 欄位名修改主鍵
ALTER TABLE Skills DELETE PRIMARY KEY ALTER TABLE Skills ADD PRIMARY KEY ( SkillID, SkillName );添加外鍵
alter table user add key `outside_KEY` (`id`);
1.7.2 表單整體操作
整體洗掉
DROP TABLE IF EXISTS `XXX`其他語法規則
( ` )單反號 (飄號) 用來 標識 庫名;表名;欄位名;索引;別名
一個DATABASE 有一個 db.opt 來保存當前的options 選項表
注釋 # ;/* */ ;--;
SQL大小寫不敏感
2.MySQL資料管理
2.1 外鍵
2.1.1 創建表時候直接添加外鍵
建表 grade
CREATE TABLE `grade`(
`gradeID` INT(10) NOT NULL AUTO_INCREMENT COMMENT '年級號',
`gradeName` VARCHAR(20) NOT NULL DEFAULT 'name' COMMENT '年級名',
PRIMARY KEY (`gradeID`)
)ENGINE=INNODB DEFAULT CHARSET=utf8
建表 student 并添加外鍵
CREATE TABLE IF NOT EXISTS `student` (
`id` INT(10) NOT NULL AUTO_INCREMENT COMMENT '學生學號' ,
`otherInformation` VARCHAR(50) NOT NULL DEFAULT 'info' COMMENT '其他資訊' ,
`gradeID` INT(10) NOT NULL COMMENT '學生的年級',
PRIMARY KEY (`id`) ,--主鍵
KEY `FK_gradeID` (`gradeID`), --添加外鍵
CONSTRAINT `FK_gradeID` FOREIGN KEY (`gradeID`) REFERENCES `grade`(`gradeID`) --添加約束
)ENGINE =INNODB CHARSET=utf8
邏輯關系 :
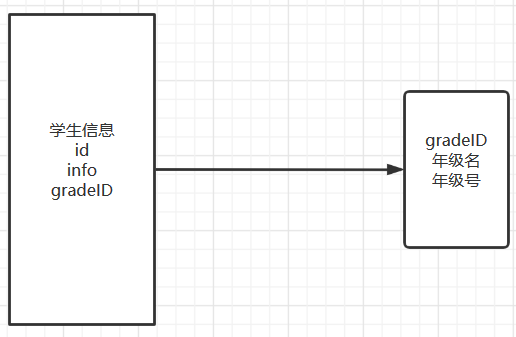
grade 不可被直接洗掉 由于student 定義了對于grade 的外部鍵
洗掉有外鍵的表 ,不可直接洗掉依賴的表
2.1.2 創建表后添加外鍵
ALTER TABLE `student` --修改表名
ADD CONSTRAINT `FK_gradeID` FOREIGN KEY (`gradeID`) REFERENCES `grade` (`gradeID`) --添加約束 增加外鍵欄位的位置
不用外鍵 :
阿里內部(業界)強制規范 :不得使用外鍵與內部相關聯 ,一切外鍵概念必須再應用層解決
2.2 DML語言 (修改資料)
資料庫的意義 :大規模資料存盤 建議全文背誦
2.2.1 添加
插入單個欄位
INSERT INTO `grade` VALUES(content) -- 內容和列資料 一一匹配
插入多個欄位
INSERT INTO `grade` (`gradeName`) --形容 表.列 VALUES('大四') ,('研一'); --值INSERT INTO `student` VALUES(1,'info1',1),(2,'info2',2); --外鍵值 必須對應于索引中的匹配
2.2.2修改
uodate 修改 (狀態)
修改一個屬性
UPDATE `student` set `name`='狂神' WHERE id=1;修改多個屬性 , 逗號隔開
UPDATE `student` SET `name`='老八',`age`= 35 ,`otherInformation`='老八蜜汁小憨包' WHERE id=2;
WHERE 附加運算子
| 運算子 | 含義 | 范圍 |
|---|---|---|
| = | 等于 | 絕對滿足條件 |
| <> 或者 != | 不等于 | 絕對不滿足 |
| > | 大于 | 絕對大于 |
| < | 小于 | 絕對小于 |
| <= | 小于等于 | ,, |
| >= | 大于等于 | ,, |
| BETWEEN ...and... | 范圍 | 范圍與 |
| AND | 與 | 條件與 |
| OR | 或 | 條件或 |
2.2.3 洗掉
洗掉單條資料
DELETE FROM `student` WHERE id=9;清空表單 (不建議使用)
DELETE FROM `student`建議使用的清空資料庫操作
TRUNCATE `student`二者的相同點:都能刪資料 都不會洗掉表單結構
區別:
- TRUNCATE 重新設定 ,自增列 計數器會歸零
- TRUNCATE 不會影響事務,索引從一開始
- DELETE 影響事務 ,新索引設定為上次洗掉的最后一位加一
而且DELETE洗掉后 重啟資料庫 的現象
引擎 問題 INNODB 自增列從一開始 (存盤在記憶體中,斷電即失) MYISAM 自增從上一個自增開始(存在檔案中 斷電不失)
2.2.4重繪資料庫
flush privileges
2.2.5 DML小結
INSERT INTO `student` VALUES(5,'網銀',3,'老鐵',30,CURRENT_TIME); --嚴格按列 否則失敗
UPDATE `student` SET `name`='王銀' ,age=18 WHERE id=5;
DELETE FROM `student` WHERE id=5;
SELECT
3.DQL查詢資料
3.1 認識DQL
3.1.1重要性
Data QUERY LANGUAGE : 資料查詢語言
支持所有型別的查詢
SQL最核心的語言規范
SQL使用頻率最高的語言規范
3.1.2 SELECT完整語法
SELECT [ALL | DISTINCT] {* | TABLE.* | [TABLE.field1][AS alias1],[TABLE.field2][AS alias2] ,...} FROM `tableName` as [TABLE_alias] [LEFT | RIGHT | INNER JOIN table_name] -- 聯表查詢 [WHERE ... ] -- 指定結果滿足條件 [GROUP BY ... ] -- 指定結果按照欄位分組 [HAVING] -- 過濾分組的記錄必須滿足的次要條件 [ORDER BY ... ] -- 指定查詢記錄按一個或者多個排序 [LIMIT {[OFFSET]ROW_COUNT | ROW_COUNTOFFSET OFFSET}]; -- 指定查詢的記錄從那條至哪條
3.2 查詢
3.2.1 基本查詢操作
1.查詢表的所有資料
SELECT * FROM student; --不帶飄號 SELECT * FROM `grade`; --帶飄號2.查詢指定欄位
SELECT `gradeName` FROM grade ; SELECT `name` ,`age` FROM student;3.查詢指定欄位,指定別名
SELECT `name` AS 學生姓名,`age` AS 學生年齡 FROM student;
3.2.2 DQL函式
1.連接函式
SELECT CONCAT ('姓名 : ',`name`) AS 標準名 FROM `student`;
3.2.3 普通的查詢操作
1.去重操作
SELECT DISTINCT `name` FROM `student` ;2.所有資料 +1
SELECT `totalScore`+1 FROM `student`;注意:只是顯示出來的資料+1 不會改變原表的內容
3.2.4 DQL (SELECT)的其他功能
1.查詢SQL版本號
SELECT VERSION()2.計算運算式的結果
SELECT 100*3-1 AS3.查詢自增步長
SELECT @@auto_insrement_increment
3.3 進階查詢
3.3.1where條件子句
作用 : 檢索資料中的符合條件的值
| 運算子 | 語法 | 描述 |
|---|---|---|
| AND && | a AND b a&&b | 邏輯與 |
| OR || | a OR b a||b | 邏輯或 |
| Not ! | NOT a ! a | 邏輯非 |
對于區間查詢的三種寫法
- &&
SELECT studentNo ,studentRes FROM result WHERE studentRes >=80 && studentRes <=95;
- BETWEEN AND
SELECT studentNo ,studentRes FROM result WHERE studentRes BETWEEN 80 AND 95;
- AND
SELECT studentNo ,studentRes FROM result WHERE studentRes >=80 AND studentRes <=95;或 ,非 操作類似 不多冗述
3.3.2模糊查詢
本質 : 比較運算子
| 運算子 | 語法 | 描述 |
|---|---|---|
| IS NULL | a is null | NULL為真 |
| IS NOT NULL | a is not null | 不是NULL 為真 |
| BETWEEN | a between b and c | a 在 b c間 為真 |
| Like | a like b | SQL匹配 a 匹配b 為真 |
| in | a in (a1,a2,a3....) | a在給定陣列欄位中為真 |
查詢通配符 :
% 匹配任何數量的任意字符
SELECT studentRes FROM result where studentName Like '劉%' -- 可以匹配如劉洋 劉建偉 劉行趙麗 劉大蘇打大大啊sdadasa -- 匹配名字中有 嘉的 Like '%嘉%'_ 匹配一個任意字符
SELECT studentRes FROM result where studentName Like '劉_' -- 可以匹配如 劉洋 劉備 劉兵 劉申 -- '劉__'匹配兩個任意字符 -- '劉___'匹配三個任意字符 以此類推....
3.4 JOINON聯表查詢
3.4.1七種理論
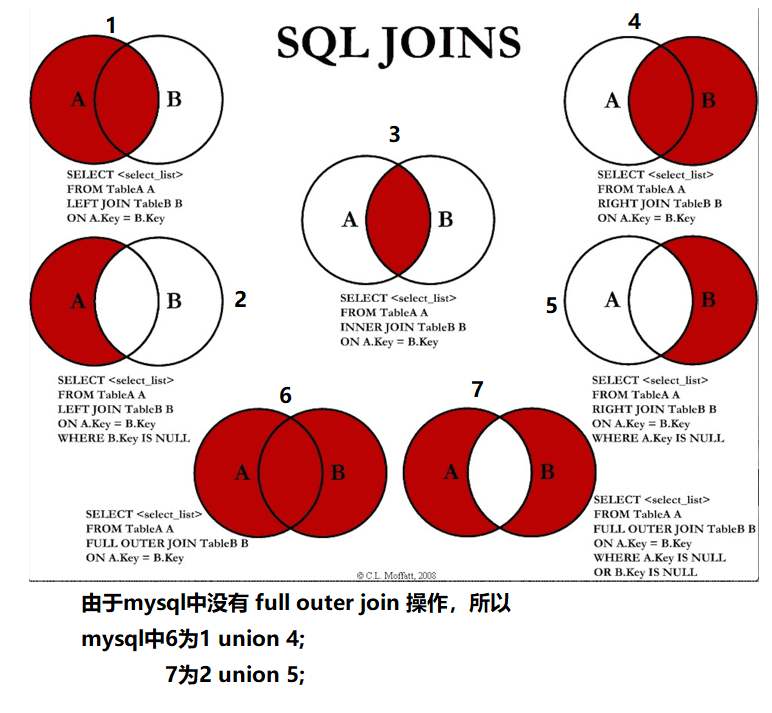
3.4.2三個例子
3examples :
1.INNER JOIN 相交查詢
SELECT s.gradeID ,s.`name` -- 查詢內容 FROM `student` AS s -- 起別名 INNER JOIN `grade` AS g -- 行內查詢 WHERE s.gradeID=g.gradeID; -- 條件2.Right JOIN 即使左表沒有匹配也會從右表回傳所有的值 以右表為基準
SELECT s.gradeID,s.name FROM `student` AS s -- 左表 RIGHT JOIN `grade` AS g -- 右表 ON s.gradeID=g.gradeID;3.Left JOIN 即使右表沒有匹配也會回傳左表的所有值 以左表為基準
SELECT s.gradeID,s.name FROM `student` AS s -- 左表 LEFT JOIN `grade` AS g -- 右表 ON s.gradeID=g.gradeID;
陳述句思路:
1.分析需求 ,分析查詢的欄位來自哪些表 student result subject (連接查詢)
2.確定使用哪種的連接查詢
3.判斷交叉點 :相同的資料
4.判斷交叉條件:WHERE 子句
注意:
ON 連接查詢
WHERE 條件查詢
3.4.3多表查詢
SELECT s.gradeID,s.name ,sc.totalScore -- student的年級 學生姓名 總分 FROM student AS s -- LEFT JOIN grade AS g ON s.gradeID=g.gradeID RIGHT JOIN score AS sc ON sc.id=s.gradeID;
3.5 自查詢,自連接
自己和自己連接
把一張表拆成兩張表
復習:
1.建表
CREATE TABLE IF NOT EXISTS`school`.`學習清單`( `pid` INT(10) NOT NULL DEFAULT 1 COMMENT '父親id', `selfid` INT(10) NOT NULL DEFAULT 2 COMMENT '自己id', `content` VARCHAR(20) COMMENT '內容', PRIMARY KEY (`selfid`) )ENGINE=INNODB CHARSET=utf8 COLLATE=utf8_general_ci;2.插值
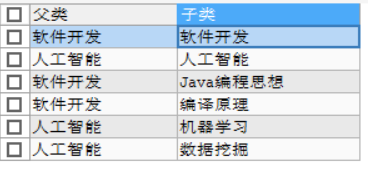
INSERT INTO `學習清單` VALUES(1,1,'軟體開發'),(2,2,'人工智能'), (1,3,'Java編程思想'),(1,4,'編譯原理'), (2,5,'機器學習'),(2,6,'資料挖掘');3.自連接,自磁區
SELECT a.`content` AS `父類`,b.`content` AS `子類` FROM `學習清單` AS a,`學習清單` AS b WHERE a.`selfid`=b.`pid`;結果:
定義自己的父親是自己 ,講一個父類分為幾個子類的程序
修改后
UPDATE `學習清單` SET `pid`=0 WHERE content='軟體開發' OR content='人工智能';

3.6 分頁和排序
起始頁下標 [i ,pagesize] 容納量 (i-1)*pagesize
SELECT a.`content` AS `父類` ,b.`content` AS `子類` FROM `學習清單` AS a ,`學習清單` AS b WHERE b.pid=a.selfid ORDER BY `父類` ASC LIMIT 0,6;limit 語法:
limit 查詢起始下標 pageSize排序 語法 :
ORDER BY `key` ASC -- 升序 ORDER BY `KEY` DESC -- 降序
3.7.子查詢 (嵌套查詢)
where 陳述句中再嵌套一個 select 陳述句
1.原始方法 : 聯表查詢方法
SELECT s.otherInformation AS `愛好`,s.id AS `身份號碼`,sc.totalScore AS `總分` FROM `student` AS s INNER JOIN `score` AS sc ON s.id=sc.id ORDER BY sc.totalScore DESC2.新方法 : 子查詢(嵌套where方法) 子查詢不能多于一行
SELECT DISTINCT s.otherInformation AS `愛好`,s.id AS `身份號碼`,s.`name` -- DISTINCT 去重 FROM `student` AS s WHERE s.id IN ( SELECT id FROM `score` WHERE `totalScore` BETWEEN 600 AND 700 -- where in 查詢范圍 ) ORDER BY s.id ASC ;
3.8 SELECT小結
某寶,某東,某夕夕千人千面
不僅是 mysql 還有Redis ,cloud ,SequoialDB 等非關系/快取儲型,比較復雜
4.MySQL函式
具體請參考官網檔案 : https://dev.mysql.com/doc/refman/5.7/en/introduction.html 用的話直接查找即可
4.1常用函式
SELECT 為先 永遠SELECT
ABS()|CEILING()|FLOOR()|RAND()|SIGN() .....都是見名知意的
4.2聚合函式
| 函式名 | 描述 |
|---|---|
| COUNT() | 計數 |
| SUM() | 求和 |
| AVG() | 平均值 |
| MAX() | 最大值 |
| MIN() | 最小值 |
| ... | ... |
忽略所有的NULL值
select count(name) from `student`
select * 1 null的辨析 請上網參考各路博文和官方DOC 只有納百家之長 才能清晰理解,這里不粘鏈接
4.3DQL查詢分組
eg. 查找一個科目的 平均,最大,最小分,并分類統計
SELECT s.name AS `姓名`,s.age AS `年齡`,AVG(`高等數學`) AS `平均分` ,MAX(`高等數學`) AS `最高分`, MIN(`高等數學`) `最低分` FROM `score` AS sc INNER JOIN student AS s ON s.id=sc.id GROUP BY s.id
4.4資料庫級別的MD5查詢加密
4.4.1定義
來自baidu :
MD5資訊摘要演算法(英語:MD5 Message-Digest Algorithm),一種被廣泛使用的密碼散列函式,可以產生出一個128位(16位元組)的散列值(hash value),用于確保資訊傳輸完整一致,MD5由美國密碼學家羅納德·李維斯特(Ronald Linn Rivest)設計,于1992年公開,用以取代MD4演算法,這套演算法的程式在 RFC 1321 標準中被加以規范,1996年后該演算法被證實存在弱點,可以被加以破解,對于需要高度安全性的資料,專家一般建議改用其他演算法,如SHA-2,2004年,證實MD5演算法無法防止碰撞(collision),因此不適用于安全性認證,如SSL公開密鑰認證或是數字簽名等用途,
4.4.2加密代碼(mysql實作)
1.建表
CREATE TABLE `testmd5`( `id` INT(4) NOT NULL , `name` VARCHAR(20) NOT NULL , `pwd` VARCHAR (50) NOT NULL, PRIMARY KEY (`id`) )ENGINE =INNODB DEFAULT CHARSET=utf8;2.插值
INSERT INTO `testmd5` VALUES (1,'zhangsan','123456'),(2,'wangwei','123456'),(3,'lisi','1233456');3.MD5方式加密
UPDATE testmd5 SET pwd=MD5(pwd)或者在插入時就加密
INSERT INTO `testmd5` VALUES (4,'sange',MD5('pop3'));4.檢驗用戶傳過來的密碼正確性
select * from testmd5 where `name`='sange' and pwd=md5('pop3')
5.事務和業務
5.1什么是事務
要么都成功,要么都失敗
eg1.定義某個事務為 : A給B轉賬 x元,保證A 擁有大于等于x元.
事務成功為 : A的賬戶記錄減少x元 ,并且B的賬戶記錄增加x元 ,兩者必須都成功 才事務成功,否則事務失敗
| SQL執行事務 | 抽象邏輯 | A賬戶狀態 | B賬戶狀態 | 總和 |
|---|---|---|---|---|
| * | 初始狀態 | 1000 | 1000 | 2000 |
| A記錄 - 200 | A給B轉賬200 | 800 | 1000 | 2000 |
| B記錄 + 200 | B收到A的200 | 800 | 1200 | 2000 |
| * | 結束狀態 | 800 | 1200 | 2000 |
絕對滿足表格,事務成功 Transaction success
5.2ACID原則
事務原則 : ACID 原則 原子性,一致性,隔離性,持久性
1.原子性 Atomicity
原子性是指事務是一個不可分割的作業單位,事務中的操作要么都發生,要么都不發生
2.一致性 Consistency
事務前后資料的完整性必須保持一致
3 隔離性 Isolation
事物的隔離是多個用戶并發訪問資料庫時,資料庫為每一個用戶開啟的事務,不能被其他的事務的操作資料干擾,多個并發事務之間要相互隔離
4.持久性 Durability
持久性是一個事務一旦被提交,他對資料庫中的資料的改變就是永久性的,接下來即使資料庫發生故障也不應該對其有任何影響
隔離產生的一些問題
臟讀:
指一個事務讀取了另外一個事務未提交的資料
不可重復讀:
在一個事務內讀取表中的某一行資料 多次讀取結果不同 (非錯誤,是場合不對)
虛讀 (幻讀):
是指在一個事務內讀取到了別的事務插入的資料 導致前后讀取不一致
5.3測驗事務
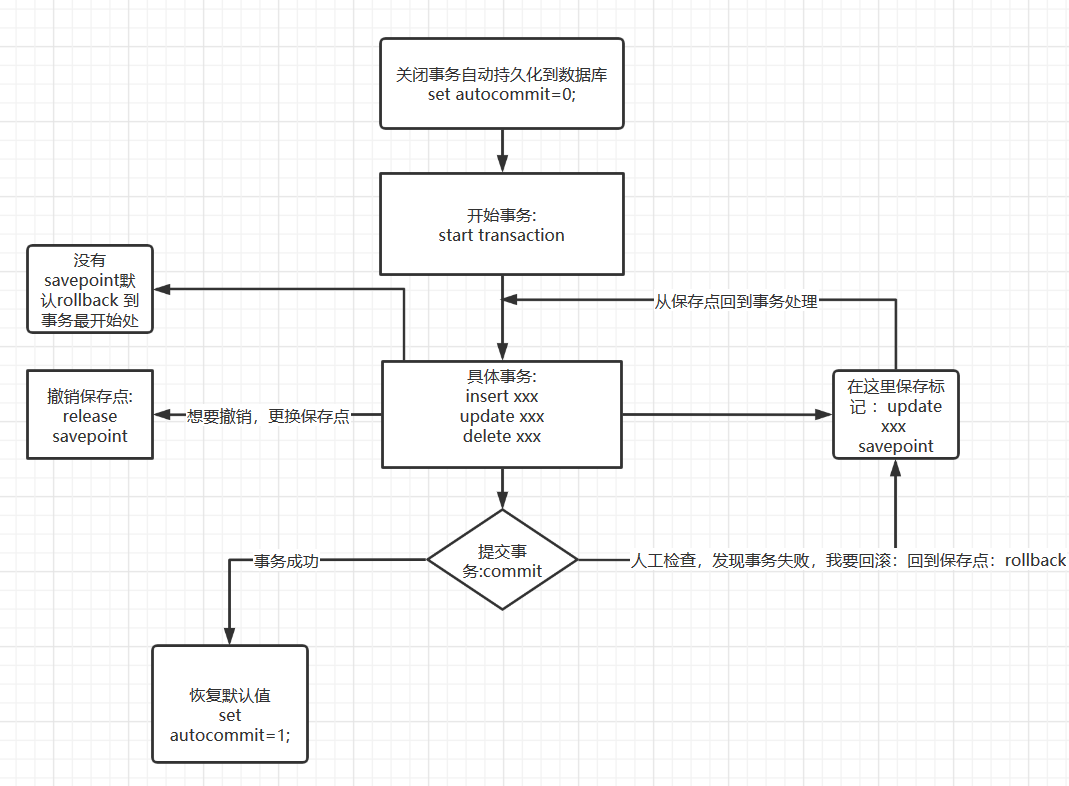
5.3.1 內容
- 設定事務自動提交到資料庫的狀態
SET autocommit=0; -- 設定事務 關閉 SET autocommit=1; -- 設定事務 開啟(默認)
2.手動處理事務
標記一個事務的開始,從此時起sql都在同一個事務內
set autocommit=0;
start transaction
增加事務記錄
insert xxx提交
commit事務失敗 ,回滾
ROLLBACK事務結束 回復到默認狀態
set autocommit=1;注 :
保存點 :設定一個事務的保存點
SAVEPOINT回滾到保存點
rollback to savepoint撤銷保存點
release savepoint事務邏輯圖 :原創
5.3.2事務實作
只有代碼
轉賬事務實作
一次執行一條,這很重要
CREATE DATABASE IF NOT EXISTS `shop` ;USE shop;
CREATE TABLE IF NOT EXISTS
account(
idINT(10) NOT NULL AUTO_INCREMENT COMMENT '賬戶名',
nameVARCHAR(10) NOT NULL COMMENT '姓名',
moneyDECIMAL(9,4) NOT NULL COMMENT '賬戶金額',
PRIMARY KEY (id)
)ENGINE=INNODB CHARSET=utf8 COLLATE=utf8_general_ciINSERT INTO
accountVALUES(1,'Roky',1000.00),(2,'Jane',5000.00),(3,'Pony',10000.00);SET autocommit=0;
START TRANSACTION
UPDATE
accountSET money=money-200 WHEREname='Jane'
UPDATEaccountSET money=money+200 WHEREname='Roky'COMMIT
ROLLBACK
SET autocommit=1;
6.索引原理
推薦博客:https://blog.codinglabs.org/articles/theory-of-mysql-index.html
從作業系統,計算機底層架構和資料結構,演算法講解的索引原理,是一篇質量極其高的博文,博主寫了半個月,成文時間2011年,年代較遠,但沒有影響它的價值,個人看了3天,順便說兩句,從計算機底層總結的東西,都值得我們仔細鉆研;程式不僅僅是事務邏輯和框架,從來都是資料結構和演算法,不懂底層原理,只能成為附庸
6.1 閱讀博文和官方Doc 心得筆記
1.索引本質
我們想更加快速的找到資料,我們都知道mysql是根據索引查找資料,但是普通的查找可能不會高效,依靠資料結構才能更加高效,所以所謂索引是一種資料結構
2.為什么選擇資料結構
解決海量用戶對于海量資料的高并發問題
3.MySQL選擇的資料結構
我們已經知道 BST 在查找方面的性能非常優越,但會造成退化,AVL和 R-B這兩個變種對于退化做了一些優化,R-B相對于AVL來說Rotate沒那么多,增加了結點的parent和color,已經非常優越了,于是,Java的HashMap選擇了這種結構,但是MySQL并沒有選擇這兩種,而是更為復雜的 B-Tree 和 B+Tree ,MySQL和HashMap都是以Key-Value方式查找Value,而HashMap是程式運行時有效的,非持久化,就是在RAM中斷電即失,而MySQL是持久性的,存盤在磁盤的磁區,說白了,HashMap性能再高,存盤的資料也要依靠記憶體大小,而MySQL是廉價的硬碟,資料量大到幾百億還可以運行,在Sahni博士所著作的資料結構與演算法 樹的末尾章節有詳細講述B-樹的原理,但是沒有代碼描述,總體來說,這種結構相對復雜.
2.1 B- /B+樹 概括結構
一切樹的本質 : 對于用鏈表描述的結構來講,永遠是遞回的.
一些定義
根節點 :根
內部節點 : 非空非根的結點
外部結點:葉子節點的兒子節點 ,就是NULL
抽象結構:一個B-樹 是一個m叉搜索樹,可以理解為有序陣列和樹形的結合,
結點概況:一個節點數為m的B樹可以有[m/2,m]個,這個結點是一個長度為m的陣列,這個陣列是有絕對不降序的,(絕對不降序是指對于陣列的整體元素來講,可以有相同的元素,但是MySQL不允許這種情況)對于內部的結點來講,根節點陣列長度至少為2,所有的外部節點都在同一個層,保證了樹高h可以絕對一致化
排列順序:一個結點的陣列最頭部結點的孩子結點的Key都小于該節點,一個結點陣列尾部結點Key都大于該節點,一個結點陣列中第i個元素Key 大于他的第i子Key,小于他的第i+1子的Key,
查找方式:所以我們在查找一個元素時候,先在根節點中間比較,找到適合的區間,這個程序是二分,對于合適區間進行跳躍,這個程序是樹形.
B+樹的優化:B+樹對于 原結點的陣列做了優化,每個結點增加了 一個指向下一個元素的指標,這個可以優化WHERE陳述句的區間查閱行為,
3.底層原理
對于計算機底層原理不敢多說,筆者是大一小白一枚,計算機導論有講述,不過涉及過少,因為競賽和做專案原因提前學習MySQL.
6.2 索引分類
在一個表中主鍵索引只有一個 ,唯一索引可以有多個
主鍵索引
PRIMARY KEY- 唯一標識,主鍵不可重復,只能有一個列作為主鍵索引
唯一索引
UNIQUE KEY- 避免重復的列出現,唯一索引可以重復 ,多個都可以標識位 唯一索引
常規索引
KEY/INDEX- 默認的
全文索引
FULLTEXT- 在特定的資料庫引擎下才有 (MyISAM)
索引的添加方式
- 創建表初期,給索引增加欄位 ,在欄位后面添加 xxx KEY (
xxx欄位)- 創建完畢,增加索引 ALTER TABLE xxx ADD xxx KEY xxx (
xxx)
顯示索引資訊
SHOW INDEX FROM `account`增加全文索引
ALTER TABLE `shop`.`account` ADD FULLTEXT INDEX `fullindex` (`name`)分析 sql 的執行情況
EXPLAIN SELECT * FROM `account`SELECT * FROM `account` WHERE MATCH(`name`) AGAINST('Pony');
mysql之explain相關博文 :
https://blog.csdn.net/jiadajing267/article/details/81269067
6.3 測驗百萬級資料量
MySQL 不僅存盤資料,增刪改查 而且是可以編程的
6.3.1插入隨機的百萬資料
定義函式
DELIMITER $$
CREATE FUNCTION analog()
RETURNS INT
BEGIN
DECLARE num INT DEFAULT 1000000;
DECLARE i INT DEFAULT 0;
WHILE i<num DO
INSERT INTOapp_user(name,phone,gender,password,age)VALUES(CONCAT('用戶',i),CONCAT(FLOOR(RAND()(9999999-1000000)+1000000),'@qq.com'),CONCAT('18',FLOOR(RAND()((999999999-10000000)+10000000))),FLOOR(RAND()2),UUID(),FLOOR(RAND()100));
SET i=i+1;
END WHILE;
RETURN i;
END;
執行函式
SELECT analog()
6.3.2測驗查詢
測驗
SELECT * FROM `app_user` WHERE `name`='用戶9999'解釋
explain SELECT * FROM `app_user` WHERE `name`='用戶9999'
我們給名字添加普通索引試一下
CREATE INDEX id_app_user_name ON app_user(`name`)添加索引耗費時間10~15s左右
可以看到時間和效率大大提升了

查詢時間由2.718 sec ->0.001 sec
查詢列數由 992787 row -> 1 row
這在解決高并發問題上很有效的
6.4添加索引的原則
- 索引不是越多越好,多則繁瑣,你也記不住
- 不要對行程變動資料加索引,一致性
- 小資料量的表不需要索引,畫蛇添足,多此一舉
- 索引一般加在經常常用來查詢的欄位上
7.權限管理與資料庫備份
權限管理的目的:
在公司中,一個業務或服務有一個資料庫,這個資料庫管理員享有最高的權限,而普通員工只有一般權限,不可能所有人都最高權限,不然你刪庫跑路怎么辦
7.1 SQLYog可視化管理
無腦點擊左上角即可
7.2 SQL命令管理
1.創建用戶
create user juminiy identified by '123456' -- pwd2.修改密碼
當前用戶
set password =password('123456')其他用戶
set password for juminiy =password('123456')重命名用戶
rename user juminiy to kkk03授權 對于某個用戶的全部權限
grant all privileges on *.* to juminiy但是不能給別人授權, root可以,唯一的和ROOT不同處就是GRANT
查看權限
show grant for juminiy查看root權限
show grant for root@localhost撤銷權限
revoke all privileges on *.* from juminiy洗掉用戶
drop user juminiy
7.3 SQL備份
1.為什么備份 :
- 保證重要的資料不丟失
- 資料的轉移
2.MySQL資料庫備份的方式
直接拷貝
可視化工具手動匯出
命令列匯出 mysqldump 命令列使用
資料庫匯出
先 net start mysql
直接在 cmd 或者 bash上操作即可
# mysqldump -h 主機 -u 用戶名 -p 密碼 資料庫 表1,表2,表3 > 物理磁盤的位置 /檔案名 mysqldump -hlocalhost -uroot -p123456 school student >D:/a.sql
資料庫匯入
-- 先登錄資料庫
mysql -uroot -p123456
-- 執行匯入
source d:/a.sql
-- 不登錄資料庫
mysql -uroot -pxxxxxx 庫<備份檔案
保證這個資料庫名存在,資料庫存在,才能匯入成功
8.資料庫的規約,三大范式
8.1 為什么需要資料規范化?
資訊重復
更新例外
洗掉例外
- 無法正常洗掉資訊
插入例外
- 無法正常顯示資訊
8.2 三大范式 :
8.2.1 第一范式 1NF:
原子性:保證每一列不可分
8.2.2 第二范式 2NF:
前提:滿足1NF
每張表只描述一件事務
8.2.3 第三范式 3NF:
前提:滿足 2NF
第三范式需要確保資料表中的每一列資料都PRIMARY KEY直接相關,不能間接相關
那么在實際的應用中呢,范式雖然是范式,但是是有問題的,有時候為了性能,可以不滿足1NF 2NF 3NF
8.4 規范性和性能的問題
阿里規約:關聯查詢的表不可超過三張
- 考慮商業化的需求和目標 (成本,用戶體驗)資料庫的性能更重要
- 在規范性能的問題的時候,需要適當放的考慮一下規范性
- 故意給某些表增加一些冗余的欄位 (從多表聯查變為單表查詢)
- 故意增加一些計算列 (從大資料量降低為小資料量的查詢)
9.JDBC
Java操作資料庫
9.1 資料庫驅動
驅動:聲卡,顯卡,資料庫
eg.資料庫需要驅動程式才能運行
9.2JDBC
SUN公司為了簡化開發人員的(對資料庫統一的)操作,提供了一個(Java)操作,按照具體的規范去做
匯入依賴的包
java.sql
javax.sql
需要的jar包,不然加載不了
9.3 java操作資料庫
1.加載驅動
Class.forName("com.mysql.jdbc.Driver");
2.用戶資訊和URL
mysql版本
String url="jdbc:mysql://localhost:3306/school?useUnicode=true&characterEncoding=utf8&useSSL=false"; String name="root"; String password="123456";oracle版本
String url="jdbc:oracle:thin@localhost1521:sid";
3.連接
Connection c=DriverManager.getConnection(url,name,password);
4.SQL的物件:操作SQL
和mySQL操作相同,見名知意
c.rollback(); c.commit(); c.setAutoCommit(false);
5.執行SQL的物件:執行SQL
和SQL操作相同,也是見名知意的
Statement s=c.createStatement(); s.executeQuery(); s.execute(); s.executeUpdate();
6.獲得結果集
不知道什么型別就用Object就可了
ResultSet rs=s.executeQuery(s1); rs.getObject();
7.釋放連接
rs.close(); s.close(); c.close();
9.4 SQL注入
使用statement物件(不安全的)用java操作資料庫
jdbc中的statement物件用于向資料庫發送SQL陳述句,想完成對于資料庫的增刪改查,只需要通過這個物件向資料庫發送增刪改查的信號即可,
Statement物件的executeUpdate 方法,用于向資料庫發送增,刪,改,查的SQL陳述句,executeUpdate執行完成后,將會回傳一個整數(告知我們幾行發生變化,提示資訊和SQL相同)
1.預備作業:封裝一個工具類
public class sqlIn { private Connection c; private Statement s; private ResultSet rs; public void drive() throws ClassNotFoundException, SQLException { Class.forName("com.mysql.jdbc.Driver"); String url="jdbc:mysql://localhost:3306/school?useUnicode=true&characterEncoding=utf8&useSSL=false"; String name="root"; String password="123456"; c= DriverManager.getConnection(url,name,password); s=c.createStatement(); } public void login(String name,String pwd) throws SQLException { String opr="select * from `login` where `name`='"+name+"' and password='"+pwd+"'"; rs=s.executeQuery(opr); while(rs.next()){ System.out.println(rs.getObject("name")); System.out.println(rs.getObject("password")); } } }2.正常查詢
public static void main(String[] args) throws SQLException, ClassNotFoundException { sqlIn p=new sqlIn(); p.drive(); p.login("Tom","123456"); }3.SQL注入
欺騙服務器的規范
sql存在漏洞 ,違法的字串拼接
select * from `tableName` where `rowName1`=' 'or 1=1' `rowName2`=' 'or 1=1'代碼實作
public static void main(String[] args) throws SQLException, ClassNotFoundException { sqlIn p=new sqlIn(); p.drive(); p.login( " 'or '1=1" , " 'or '1=1" ); }
9.5 安全的物件
java一個專門防止SQL注入的類: PreparedStatement
接上邊的9.4的類
java操作資料庫
1.添加資料
public void insert(int id,String name,String pwd) throws SQLException { String opr="insert into login(`id`,`name`,`password`) values(?,?,?)"; ps=c.prepareStatement(opr);//c->connection 物件 ps.setInt(1,id); ps.setString(2,name); ps.setString(3,pwd); ps.executeUpdate();//執行更新 否則無效 } public static void main(){ p.insert(13,"ppd1234","91881qq");插入 }2.洗掉資料
public void delete(int id) throws SQLException { String opr="delete from `login` where id="+Integer.valueOf(id); ps=c.prepareStatement(opr); ps.executeUpdate(); } public static void main(String args[]){ p.delete(1); }3.更新資料和查找資料不多解釋,opr字串就是SQL中的操作,Java執行excuteUpdate()就能成功
9.6使用IDEA連接資料庫
Community版本:右邊欄
Education版本:https://blog.csdn.net/cnds123321/article/details/102854508
踩了好多坑才連接上 嗚嗚嗚///
9.7 Java執行事務
java操作事務和SQL操作事務是一樣的同樣遵循ACID原則
如果不了解什么是事務 請回到 5事務和業務章節學習
eg.用戶轉賬
public void accountPay(String fromAccount,String toAccount,int Money) throws SQLException { try{ c.setAutoCommit(false); StringBuilder sb1=new StringBuilder(); sb1.append("update account set money=money-").append(Integer.valueOf(Money).toString()).append(" where `name`= '").append(fromAccount).append("'"); ps=c.prepareStatement(sb1.toString()); ps.executeUpdate(); StringBuilder sb2=new StringBuilder(); sb2.append("update account set money=money+").append(Integer.valueOf(Money).toString()).append(" where `name` = '").append(toAccount).append("'"); ps=c.prepareStatement(sb2.toString()); ps.executeUpdate(); }catch (SQLException e1){ try{ c.rollback();//失敗了 先回滾 錢不能沒 ... }catch(SQLException e2){ e1.printStackTrace(); e2.printStackTrace(); } }finally{ c.setAutoCommit(true); System.out.println("Successful!"); } public static void main(String args[]){ p.accountPay("Weiwei","Liping",500); }
9.8 資料庫連接
資料庫連接--執行完畢--釋放
連接--釋放 十分的浪費資源
通俗解釋:就是你去銀行,只有一個服務員,你進去,為你服務,你出去了,銀行關閉,下一個人再進來,在連接,服務完,再關閉,而連接池的作用就是設定多個服務員,每個服務員都在等待,銀行不會關閉,
可以用別人寫好的,例如:DBCP,C3P0,Tomcat ,Druld:Alibaba
也可以自己用java手動實作一個(DataSource)介面
匯入依賴:
DBCP :
commons-dbcp2-2.7.0.jar
commons-pool2-2.8.0.jar
使用封裝的工具類,測驗代碼和原來的沒有任何的區別
10.基礎完結散花,撒花,撒歡,撒歡兒
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/118330.html
標籤:MySQL