正則在爬蟲領域使用很廣泛,用來把網頁中有價值的文本提取出來,這個提取技術就是用正則匹配,
我感覺正則匹配就是型別匹配,當你能認識清楚字符里面所有包含的型別和結構,那么你寫出正則也就不難了,如何認識清楚文本中會有什么型別,看如下鏈接
https://www.zhihu.com/question/48219401/answer/742444326
在這篇文章中,我建議你認識好 這些基本的:
- 1.元字符
- 2.限定符
- 3.分組
- 4.條件或
認識完這些基礎型別之后,寫正則還是有點難,
建議跟著如下鏈接,把里面的練習都做一下,我包你會有新的感悟
https://juejin.im/post/6844903648309297166
把練習都做完后,一些正常難度的(初、中級)的正則你都能寫了,
高級或進階,自行學習吧,
https://deerchao.cn/tutorials/regex/regex.htm#regexoptions
工具
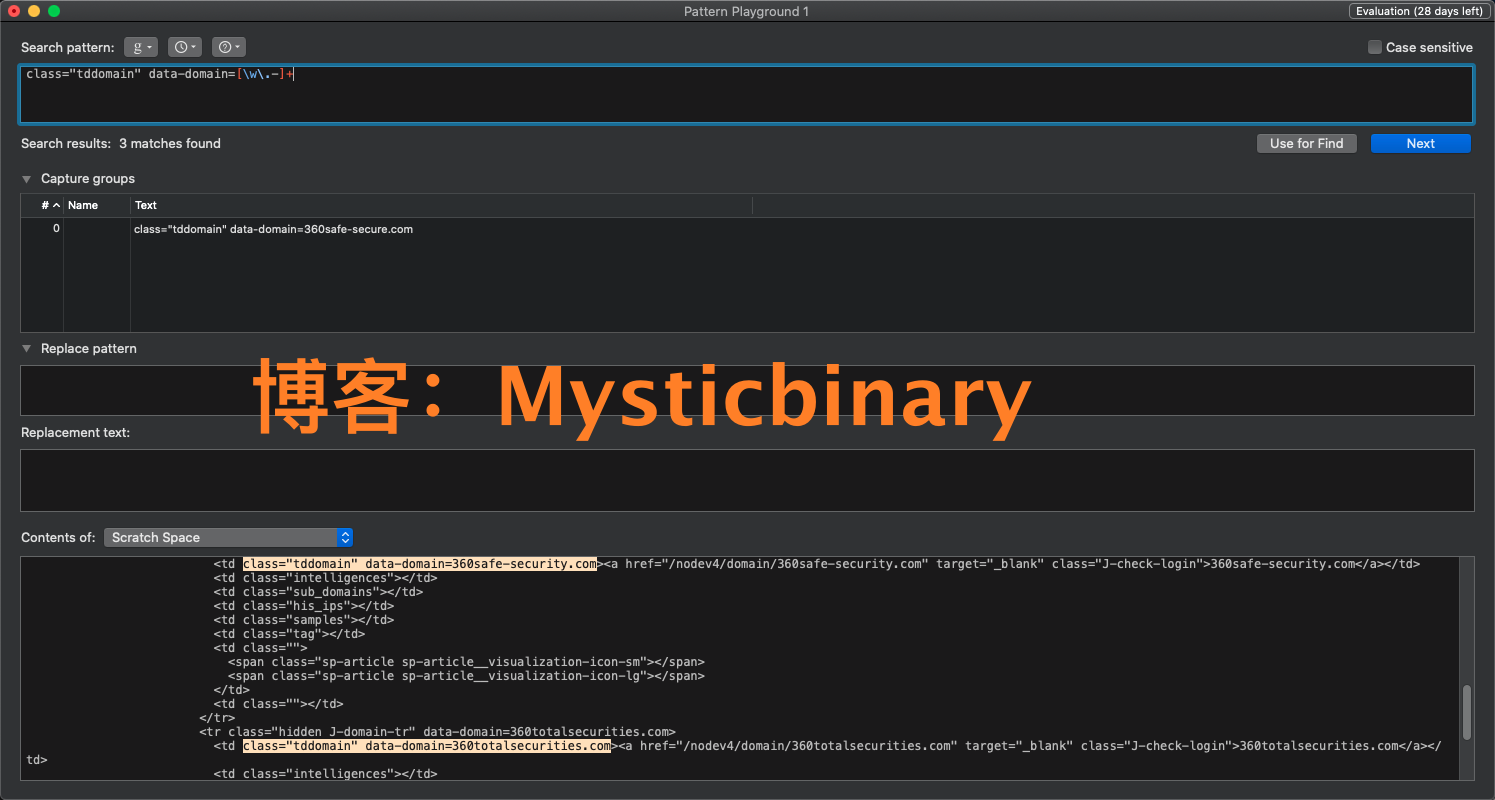
擁有一個好的除錯工具,會讓你能方便快捷的除錯你的正則陳述句,這種及時的反饋感很重要,特別是新手的你,
bbedit下載地址
https://apps.apple.com/cn/story/跟-bbedit-學正則運算式/id1485320067
使用截圖:
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/1185.html
標籤:其它