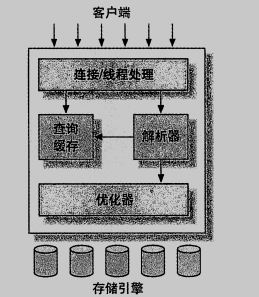
mysql 的邏輯架構分為三層:
最上層的服務大多數基于網路的客戶端、服務器的工具或者服務都有類似的架構,比如連接處理,授權認證、安全等
第二層架構:mysql的核心服務功能都在這一層,包括查詢決議,分析,優化,快取以及所有的內置函式,所有跨存盤引擎的功能都在這一層實作:存盤程序,觸發器、視圖
第三層:包含存盤引擎,負責資料的存盤和提取,innoDB是個例外,它會決議外鍵定義,因為mysql服務器本身沒有實作該功能
連接管理與安全性:
當客戶端連接到mysql服務器是,服務器需要對其進行認證,認證基于用戶名,原始主機資訊和密碼,一旦客戶端連接成功,服務器 會繼續驗證該客戶端是否具有執行某個特定查詢的權限
優化與執行:
mysql會決議查詢,并創建內部資料結構(決議樹),然后對其進行各種優化,包括重寫查詢,決定表的讀取順序,以及選擇合適的索引,用戶可以通過特殊的關鍵字提示優化器,影響他的決策程序,也可以請求優化器解釋優化程序的各個因素,使yoghurt可以知道服務器是如何進行優化決策的,并提供一個參考基準,便于用戶重構查詢和修改相關配置,優化查詢效率
存盤引擎對于優化查詢時有影響的
對于select陳述句,在決議查詢之前,服務器會先檢查快取,如果能找到對應的查詢,服務器就不會再執行查詢決議,優化和執行的整個程序,而是直接回傳查詢結果
并發控制:
只要有多個查詢需要在同一時刻修改資料,都會產生并發控制的問題,
如果應用鎖可以保證資料的完整性,不被破壞,但是并不支持并發處理,
兩個層面的并發控制:服務器層和存盤引擎層
讀寫鎖:通過實作一個由兩種型別的鎖組成的鎖系統來解決問題,也稱作共享鎖和排它鎖或者讀鎖和寫鎖
讀鎖是共享的,互相不阻塞的,而寫鎖則是排他的,
鎖粒度:一種提高共享資源并發性的方式就是讓鎖定物件更有選擇性,盡量只鎖定需要修改的部分資料,而不是所有資源,更理想的方式是,是對會修改的資料片進行精確的鎖定,
在任何時候,在給定的資源上,鎖定的資料量越少,則系統的并發程度越高,只要相互之間不發生沖突即可
所謂的鎖策略,就是在鎖的開銷和資料的安全性之間尋求平衡,大多數商業資料庫系統沒有提供能多的選擇,一般都是在表上施加行級鎖,而mysql則提供了多種選擇,每種mysql存盤引擎都可以實作自己的鎖策略和鎖粒度
表鎖:
鎖開銷最小的策略,會鎖定整張表,寫鎖也比讀鎖優先級更高,一個寫鎖請求可能會被插入到讀鎖佇列的前面
行級鎖:
最大程度地支持并發處理,同時也帶來最大的鎖開銷,行級鎖只在存盤引擎層實作,服務器層沒有實作,所有的引擎都以自己的方式實作了鎖
事務:ACID
atomicity consistency isolation durability
每種存盤引擎實作的隔離級別不盡相同
四種隔離級別:innodb引擎支持所有隔離級別
read uncommitted:未提交讀,事務可以讀取未提交的資料,臟讀(很少使用)
read committed:提交讀,大多數資料庫系統的默認隔離級別都是read committed,但mysql不是,這和個級別有時候也叫做不可重復讀,兩次執行同樣的查詢可能會得到不一樣的結果
repeatable read:可重復讀,是mysql的默認事務隔離級別,該級別保證了在同一個事務中多次讀取同樣的記錄結果是一致的,但是無法解決另外一個幻讀問題,幻讀指的是當某個事務在讀取某個范圍內的記錄時,另外一個事務又在該范圍內插入了新的記錄,檔之前的事務再次讀取該范圍的記錄時,會產生幻行,
innodb和xtradb存盤引擎通過多版本并發控制解決了幻讀的問題,
serializable:可串行化,最高的隔離級別,強制事務串行執行,避免幻讀問題,也很少用,
事務日志;
幫助提高事務的效率,使用事務日志,存盤引擎在修改表的資料時只需要修改其記憶體拷貝,再把該修改行為記錄到持久在硬碟上的事務日志中,而不用每次都將修改的資料本身持久到磁盤,事務日志采用的追加的方式,因此寫日志的操作時磁盤上一小塊區域內的順序I/O操作,而不像隨機I/O需要在磁盤的多個地方移動磁頭,所以采用事務日志的方式相對來說快的多
修改資料需要寫兩次磁盤
mysql中的事務
兩種事務型的存盤引擎:innodb和NDB Cluster
SET AUTOCOMMIT = 0 ;設定禁用自動提交模式,修改AUTOCOMMIT對本身就是非事務型的表,不會有任何影響,
有些命令在執行之前會強制執行commit提交當前的活動事務,
SET TRANSACTION ISOLATION LEVEL read committed;設定隔離級別,可以在組態檔中設定整個資料庫的隔離級別,也可以只改變當前會話的隔離級別
在事務中混合使用存盤引擎
mysql服務器層不管理事務,事務是由下層的存盤引擎實作的,所以在同一個事務中,使用多種存盤引擎是不可靠的
MVCC:多版本并發控制
innodb的mvcc:通過在每行記錄后面保存兩個隱藏的列來實作的,一個列保存了行的創建時間,一個保存行的過期時間(洗掉時間),存盤的并不是實際的時間值,而是系統版本號,每開始一個新的事務,系統版本號都會自動遞增,
不同的存盤引擎保存資料和索引的方式是不同的,但表的定義則是在mysql服務層統一處理的
SHOW TABLE STATUS LIKE 'user';顯示相關表資訊
innodb是mysql的默認事務型引擎,被設計用來處理大量的短期事務,短期事務大部分情況是正常提交的,很少會被回滾,
innodb
innodb基于聚簇索引建立,innodb的索引結構和mysql的其他存盤引擎有很大的不同,聚簇索引對主鍵查詢有很高的性能,不過它的二級索引中必須包含主鍵列,若表上的索引較多的話,主鍵應當盡可能小,存盤格式是平臺獨立的,可移植,崩潰后可安全恢復
myisam存盤引擎;崩潰后無法恢復,支持資料修復,支持全文索引,基于分詞創建的索引,對整張表加鎖,寫鎖具有排他性,讀鎖共享,不能很好的支持高并發
Memory引擎:基于記憶體,所以不保存資料 ,支持hash索引,是表級鎖,并發寫入性能較低, 應用場景:用于保存資料分析中產生 的中間資料,用于查找或者映射表,MySQL在執行查詢的程序中需要使用臨時表來保存中間結果,內部使用的臨時表就是memory表,
NDB cluster引擎:
mysql服務器、NDB集群存盤引擎,以及分布式的,share-nothing的,容災的,高可用的NDB資料庫的組合,被稱為mysql集群,
第三方存盤引擎:
OLTP:XtraDB是基于innodb引擎的一個改進版本,可以作為innodb的一個完全的替代產品,
另外還有一些和innodb非常類似的OLTP類存盤引擎,比如都支持acid事務和mvcc,其中一個就是pbxt,對固態存盤ssd提供了適當的支持,
tokudb引擎使用了一種新的叫做分形樹的索引資料結構,該結構是快取無關的,因此即使其大小超過記憶體性能也不會下降,是一種大資料存盤引擎,因為擁有很高的壓縮比,可以在很大的資料量上創建大量索引 ,
面向列的存盤引擎:
mysql默認是面向行的,服務器的查詢也是以行為單位處理的,
infobright是最有名的面向列的存盤引擎,在非常的資料量(數十TB)時,該引擎作業良好,視為資料分析和資料倉庫應用設計的,資料高度壓縮,按照塊進行排序,每個塊都對應一組元資料,訪問元資料即可決定是否跳過該塊,該引擎不支持縮影,
參考文獻《高性能mysql》
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/119269.html
標籤:MySQL
上一篇:Mysql—表資料之單表查詢