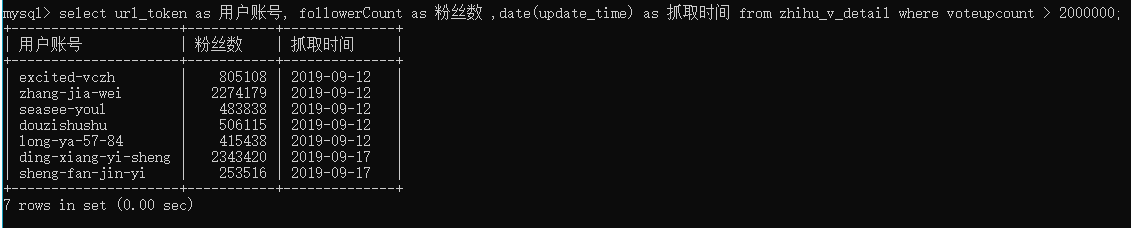
國慶假期花了一些時間,首次嘗試并玩轉 grafana,這幾天繼續不斷優化和完善,如今看著自己的成果,相當滿意,——逐步接近我想要的理想后臺啦,
需求是不停歇的,今天我又給自己發掘了一些新需求,比如變數、篩選框之類,都收集下來等有空繼續玩,編程學習的程序中,對于自己尚未嘗試的新技能點,本能直徑訓感到困難,但動手經驗告訴我:莫慌,用起來就懂了,瞧我自己每次都能很快上手吖,——善于讓自己在學習的程序中感受良好,并確實持續進步,自我激勵是一個特別實用的軟技能,
然后我想著不妨把這幾天玩轉 grafana 時用到的進階版的 sql 陳述句整理出來,所謂進階版,是針對我個人的 sql 能力啦,確切地講,是指在我之前的筆記中未曾出現、且玩轉 grafana 中我確實反復用到的,整理自己剛剛反復實踐的新知識點,能很好地鞏固新知,完成這件事,方能安心進入下一個階段向未知沖刺,
之前寫了一篇筆記,記錄自己是為什么要玩 grafana ,以及如何在 24 H做到被工程師稱贊,文中提及我把工程師已經實作的 sql陳述句拷貝下來,拆解為元知識點,然后逐個理解:它是什么功能,如何用,然后直接用起來試試效果,
舉個實體來拆解元知識點
在本篇筆記中,我也先舉一個實體用作知識點拆解,如下,該述陳述句的作用是:統計每天具有學習行為的用戶數,注:學習行為其實包含多種具體的行為,分布在兩個表中,
with data as(
select
date(created_at) as time,
user_id
from user_comments
union all
select
date(created_at) as time,
user_id
from user_activities
)
select
time,
count(distinct user_id) as 每日學習用戶數
from data
group by time
order by time
注意:sql 對大小寫、換行、縮進之類都不敏感,這是和 python不同的地方,上面之所以要換行和縮進,只是為了易讀性,
這一條 sql 陳述句看著挺長,其實是兩個部分,as 前面的 data 是資料的名字,我們自定義的,后面B部分的from 資料源就是它,被 with data as() 括起來的A部分,用于生成資料,相當于先做一次檢索統計得到一些資料命名為 data ,然后再對 data 進行檢索統計,
with data as (【陳述句塊A】)
【陳述句塊B】
可嵌套的 with data as()
短時間用 with data as() 用的比較多時,我就揣測:這玩意兒能嵌套嗎?一試果然可行,嵌套只是讓它看上去復雜點,本質沒啥變化,如下所示,陳述句塊 A 的資料源是原始資料,陳述句塊 B 的資料源是 data,陳述句塊 C 的資料源是 datax,
with datax as(
with data as (【陳述句塊A】)
【陳述句塊B】
)
【陳述句塊C】
實戰中,我最多用過3層嵌套,且偶爾為之;雙層嵌套用的多一些,而單層則相當常用,
用union合并資料行
上方實體被 with data as() 括起來的部分,其實是兩個表滿足條件的資料合并,抽象一下如下,
【陳述句塊X】
union all
【陳述句塊Y】
處理表格資料的合并時,細分有以下三個情形:
- 把多列或多行的資料,合并為單列或單行的資料
- 把A表的數列,與B表的數列合并起來
- 把A表的數行,與B表的數行合并起來
union 處理的是基于行的合并,舉例來說,如果陳述句塊X的結果為a行,陳述句塊Y的結果為b行,則通過union all 合并后的結果將有(a+b)行,而用 union 的結果是取a和b的并集,即a、b中都存在的資料行只保留一份,
相對應的,在pandas 通過 pd.concat() 的axis引數就能處理行、列的不同方式合并,還真是簡約吖,
函式data()與as別名
上方舉例中,陳述句塊X 和Y大體上是蠻基礎的陳述句,但依然出現了我之前沒有用過的方法,
date(created_at) as time,和count(distinct user_id) as 每日學習用戶數這兩個片段中,as之前是運算式陳述句,as之后是該陳述句運算結果的別名,date()方法是把復雜的時間資料簡化為年月日的日期資料,超高頻使用,count(distinct user_id)則表示:對user_id去重,然后統計user_id個數,超高頻使用,
類似count()和sum()都是高頻使用的基礎函式,不過資料統計中,更常用到累加,陳述句是定番組合,就不再單獨羅列啦:
sum(兌換用戶數) over (order by 兌換日期 asc rows between unbounded preceding and current row) as 累計用戶數
而count(1),count(*) 和 count(column_name) 在不同情況下,運行效率不同,鑒于我暫時沒有寫出性能最好的sql陳述句之覺悟,暫不深究啦,
各種情況下的去重
上面提及distinct ,如何使用distinct 倒不復雜;復雜的是需求,對資料指標的定義要理解準確;不同的資料指標,對去重有不同的要求,
情境A:不去重,
雖然count的是user_id,但這個資料其實并不是每天留言的用戶數,而是每天留言的條數,
select
date(created_at) as time,
count(user_id) as 每日留言條數
from
user_comments
group by
time
order by
time
情境B:當日去重,
在當天內去重,跨天不去重,用戶在某一天有多條留言,最終也只能為當天留言用戶數貢獻計數1
select
date(created_at) as time,
count(distinct user_id) as 每日留言用戶數
from
user_comments
group by
time
order by
time
情境C:歷史累積去重,
有過留言行為的累計用戶數,則在全時段內去重,只要該用戶曾有過留言行為,則計數1,不再重復計數,
select
count(distinct user_id) as 留過言的用戶總數
from
user_comments
情境D:每日和歷史累積同時去重,
假設我們想知道每日新增的留言用戶數,即如果該用戶以前曾留言則不計數,否則在首次留言當天計數1,這個情境比前面三種復雜點,但同樣相當高頻使用,
with data as (
select
distinct on (user_id) user_id,
date(created_at) as time
from
user_comments
)
select
time,
count(user_id) as 每日新增留言用戶數,
count(user_id) over (order by time asc rows between unbounded preceding and current row) as 累積留言用戶總數
from data
group by time,user_id
order by time
幾個常見的小知識點
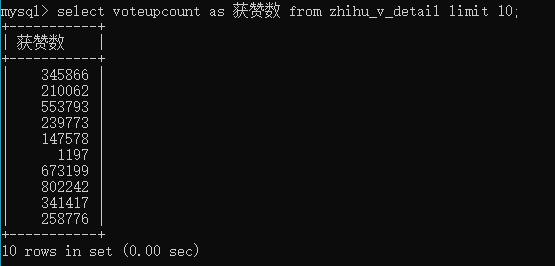
limit指定顯示多少條資料,換言之,沒有這個條件,就表示要顯示查詢結果的所有資料,我之前不知道這個知識點時,有時不小心直接在命令列提示符中查看某個表,會一下子列印很多很多行,以至于一直下翻都不見底……而在資料后臺中,通常配合排序功能,用來顯示“排行榜”資料,比如,學習次數排行榜、兌換總額排行榜之類,
select * from table_name limit 50;
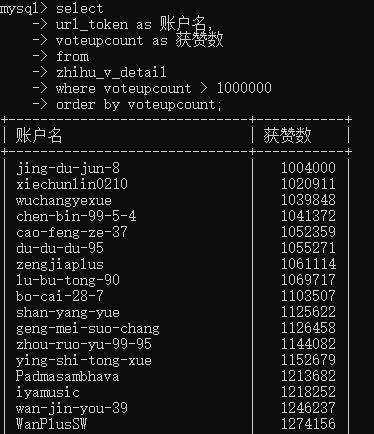
order by 指定資料按哪些欄位排序,默認順序,可用desc倒序,
select * from table_name order by column_name;
group by 指定資料按哪些欄位分組,很多報表按日統計,前面舉例中無形中也用了該方法數次,就不單獨舉例啦,
多表聯合查詢
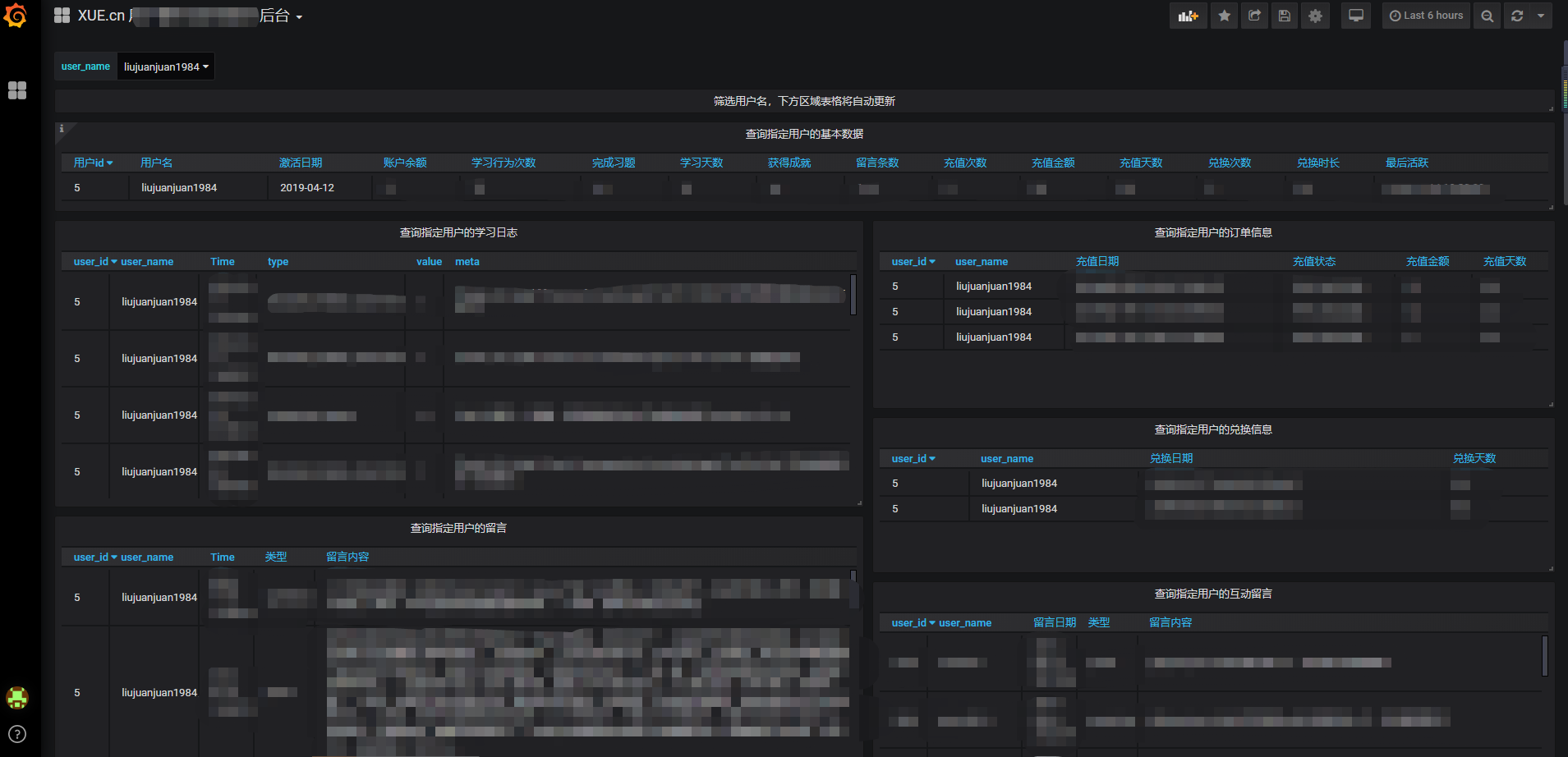
最后說明下,相對復雜的多表查詢,從多個表格、或表格和自定義資料源如data中合并查詢,一個相對簡單的實體如下,根據輸入變數 user_name 從 users_extra 查詢到 user_id,然后用 user_id 去user_activities 表查詢,
with data as(
select user_id,user_name from users_extra where user_name = '$user_name'
)
select
count(1) as 學習行為次數
from
user_activities,data
where
user_activities.user_id = data.user_id
這種聯合查詢必要的條件是,多個資料源可以通過某個欄位對應起來,更復雜的例子,其實都可以動用拆解的方式,拆解為更單元的知識點,這里就不展開啦,
順便說,上面的 user_name = '$user_name' 陳述句是 grafana 中用于呼叫自定義變數,實作后可支持下拉框篩選,這也是剛開始寫這篇文章時,我提到的新需求,結果文章修修改改寫完,這個需求竟然被我實作了,還真是快!
小結
如果某天你和我一樣開始接觸一點進階、復雜的sql陳述句或其它技能,千萬別慌,找一些現成的實體(比如收藏我這篇筆記)來消化,逐塊拆解為元知識點,然后再把它們拼裝結合用起來,你會發現:也不過如此嘛,
這個程序多像玩兒積木吖!好玩好玩!
如果這篇筆記幫到了你,一定要留言告訴我吖;這將鼓勵我整理和分享更多,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/119326.html
標籤:MySQL