這是某公司的一份SQL Server資料分析面試題,總共有4道題,此處挑選了其中的3道,另外1道比較簡單,就不列出來了,
第一題:
題目:寫一個SQL函式,能將一串字串按指定的分隔符拆分成行,比如給定字串"查詢,入庫,出庫,移庫,盤點,設定",查詢出來的結果是:

審題:這是一道典型的Split函式題,看過一些寫法,可以一段一段地截取,可以使用反轉等等,但是核心的知識點就是Index,
做題:下面是我的寫法,僅供參考,
CREATE FUNCTION [dbo].[Split](@Text NVARCHAR(4000),@SplitSymbol NVARCHAR(4000)) RETURNS @ResultTable TABLE ([VALUE] NVARCHAR(4000)) AS BEGIN --變數定義 DECLARE @StartIndex INT --開始位置 DECLARE @FindIndex INT --找到位置 DECLARE @Content NVARCHAR(4000) --找到內容 --變數初始化 SET @StartIndex=1 --T-SQL查找位置是從1開始的 SET @FindIndex=0 --回圈查找字串分割符 WHILE (@StartIndex<=LEN(@Text)) BEGIN --回傳查找位置 SELECT @FindIndex=CHARINDEX(@SplitSymbol,@Text,@StartIndex) --查找位置回傳0表示已查找完畢 IF (ISNULL(@FindIndex,0)=0) BEGIN SET @FindIndex=LEN(@Text)+1 END --截取字串 SET @Content=LTRIM(RTRIM(SUBSTRING(@Text,@StartIndex,@FindIndex-@StartIndex))) --初始化下次開始位置 SET @StartIndex=@FindIndex+1 --找到值插入結果表 INSERT INTO @ResultTable ([VALUE]) VALUES (@Content) END RETURN END
執行:
SELECT * FROM Split('查詢,入庫,出庫,移庫,盤點,設定',',')
第二題:
題目:對于以下資料,補充一段SQL代碼,計算出每個步驟的計劃開始時間,
原資料:
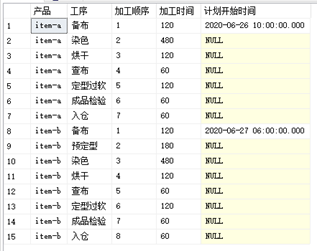
需要的結果:
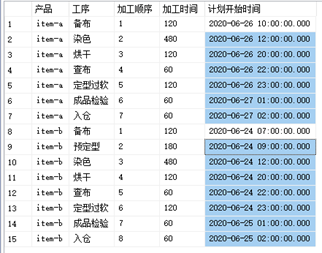
原始資料:
declare @t as table ([產品] nvarchar(50), [工序] nvarchar(50), [加工順序] int, [加工時間] int, [計劃開始時間] datetime) insert @t values ('item-a', '備布', 1, 120, '2020-06-26 10:00:00'), ('item-a', '染色', 2, 480, null), ('item-a', '烘干', 3, 120, null), ('item-a', '查布', 4, 60, null), ('item-a', '定型過軟', 5, 120, null), ('item-a', '成品檢驗', 6, 60, null), ('item-a', '入倉', 7, 60, null), ('item-b', '備布', 1, 120, '2020-06-24 06:00:00'), ('item-b', '預定型', 2, 180, null), ('item-b', '染色', 3, 480, null), ('item-b', '烘干', 4, 120, null), ('item-b', '查布', 5, 60, null), ('item-b', '定型過軟', 6, 120, null), ('item-b', '成品檢驗', 7, 60, null), ('item-b', '入倉', 8, 60, null)
-- 請在此加入代碼更新【計劃開始時間】,
-- 每個產品下一步的開始時間等于上一步的【計劃開始時間】加上【加工時間】,【加工時間】的單位為分鐘,
-- 比如【item-a】的第2步【染色】的計劃開始時間等于 2020-06-26 12:00:00.000
審題:這道題主要是相同產品依加工順序進行時間的累加,由于加工序順序是加1遞增的,大大減低了這道題的難度,否則可能要考慮使用游標來寫,
做題:下面是我的寫法,僅供參考,
DECLARE @I INT =2,@MAX INT SELECT @MAX=MAX(加工順序) FROM @t WHILE @I<=@MAX BEGIN UPDATE A SET A.計劃開始時間=DATEADD(MI,B.加工時間,B.計劃開始時間) FROM @t A INNER JOIN @t B ON A.產品=B.產品 AND A.加工順序-1=B.加工順序 WHERE A.加工順序=@I SET @I=@I+1 END SELECT * FROM @t
第三題:
題目:部門工資前三高的所有員工,
Employee 表包含所有員工資訊,每個員工有其對應的工號 Id,姓名 Name,工資 Salary 和部門編號 DepartmentId ,
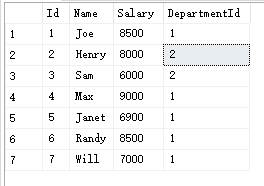
Department 表包含公司所有部門的資訊,
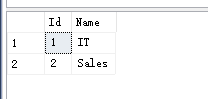
撰寫一個 SQL 查詢,找出每個部門獲得前三高工資的所有員工,例如,根據上述給定的表,查詢結果應回傳:
Select id,name from Employee group by Department order by Salary ASC limit 3;
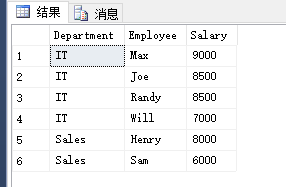
解釋:
IT 部門中,Max 獲得了最高的工資,Randy 和 Joe 都拿到了第二高的工資,Will 的工資排第三,銷售部門(Sales)只有兩名員工,Henry 的工資最高,Sam 的工資排第二,
資料:
declare @employee as table (Id int, [Name] varchar(30), [Salary] int, [DepartmentId] int) insert @employee([Id], [Name], [Salary], [DepartmentId]) values (1, 'Joe', 8500, 1) , (2, 'Henry', 8000, 2) , (3, 'Sam', 6000, 2) , (4, 'Max', 9000, 1) , (5, 'Janet', 6900, 1) , (6, 'Randy', 8500, 1) , (7, 'Will', 7000, 1) declare @department as table (Id int, [Name] varchar(30)) insert @department([Id], [Name]) values(1, 'IT'), (2, 'Sales')
審題:題目描述有點長,主要要留意的是相同部門有同薪的人員,
做題:下面是我的寫法,僅供參考,
DECLARE @Temp TABLE (DepartmentId INT,Salary INT) INSERT INTO @Temp (DepartmentId,Salary) SELECT DISTINCT DepartmentId,Salary FROM @employee SELECT A.DepartmentId,C.Name DepartmentName,A.Name,A.Salary FROM @employee A INNER JOIN ( SELECT T.* FROM ( SELECT DepartmentId,Salary,ROW_NUMBER() OVER (PARTITION BY DepartmentId ORDER BY Salary DESC) AS ROWNUMBER FROM @Temp ) T WHERE T.ROWNUMBER<=3 ) B ON A.DepartmentId=B.DepartmentId AND A.Salary=B.Salary LEFT JOIN @department C ON A.DepartmentId=c.Id ORDER BY A.DepartmentId,A.Salary DESC,A.ID
總結:有些題看起來很簡單,但是要看準考點,才可以臨危不亂,道路千千萬,你選哪一條?
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/1204.html
標籤:SQL Server