文章目錄
- 作業1:Keras教程
- 1. 快樂的房子
- 2. 用Keras建模
- 3. 用你的圖片測驗
- 4. 一些有用的Keras函式
- 作業2:殘差網路 Residual Networks
- 1. 深層神經網路的問題
- 2. 建立殘差網路
- 2.1 identity恒等模塊
- 2.2 卷積模塊
- 3. 建立你的第一個殘差網路(50層)
- 4. 用自己的照片測驗
測驗題:參考博文
筆記:04.卷積神經網路 W2.深度卷積網路:實體探究
作業1:Keras教程
Keras 是一個用 Python 撰寫的高級神經網路 API,它能夠以 TensorFlow, CNTK, 或者 Theano 作為后端運行,
Keras 的開發重點是支持快速的實驗,能夠以最小的時延把你的想法轉換為實驗結果,是做好研究的關鍵,
Keras 是更高級的框架,對普通模型來說很友好,但是要實作更復雜的模型需要 TensorFlow 等低級的框架
- 匯入一些包
import numpy as np
from keras import layers
from keras.layers import Input, Dense, Activation, ZeroPadding2D, BatchNormalization, Flatten, Conv2D
from keras.layers import AveragePooling2D, MaxPooling2D, Dropout, GlobalMaxPooling2D, GlobalAveragePooling2D
from keras.models import Model
from keras.preprocessing import image
from keras.utils import layer_utils
from keras.utils.data_utils import get_file
from keras.applications.imagenet_utils import preprocess_input
import pydot
from IPython.display import SVG
from keras.utils.vis_utils import model_to_dot
from keras.utils import plot_model
from kt_utils import *
import keras.backend as K
K.set_image_data_format('channels_last')
import matplotlib.pyplot as plt
from matplotlib.pyplot import imshow
%matplotlib inline
1. 快樂的房子
問題背景:快樂的房子的門口的攝像頭會識別你的表情是否是 Happy 的,是 Happy 的,門才會打開,哈哈!
我們要建模自動識別表情是否快樂!

- 歸一化圖片資料,了解資料維度
X_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = load_dataset()
# Normalize image vectors
X_train = X_train_orig/255.
X_test = X_test_orig/255.
# Reshape
Y_train = Y_train_orig.T
Y_test = Y_test_orig.T
print ("number of training examples = " + str(X_train.shape[0]))
print ("number of test examples = " + str(X_test.shape[0]))
print ("X_train shape: " + str(X_train.shape))
print ("Y_train shape: " + str(Y_train.shape))
print ("X_test shape: " + str(X_test.shape))
print ("Y_test shape: " + str(Y_test.shape))
輸出:
number of training examples = 600
number of test examples = 150
X_train shape: (600, 64, 64, 3)
Y_train shape: (600, 1)
X_test shape: (150, 64, 64, 3)
Y_test shape: (150, 1)
600個訓練樣本,150個測驗樣本,圖片維度 64*64*3 = 12288
2. 用Keras建模
Keras 可以快速建模,且模型效果不錯
舉個例子:
def model(input_shape):
# 定義輸入的 placeholder 作為 tensor with shape input_shape.
# 想象這是你的圖片輸入
X_input = Input(input_shape)
# Zero-Padding: pads the border of X_input with zeroes
X = ZeroPadding2D((3, 3))(X_input)
# CONV -> BN -> RELU Block applied to X
X = Conv2D(32, (7, 7), strides = (1, 1), name = 'conv0')(X)
X = BatchNormalization(axis = 3, name = 'bn0')(X)
X = Activation('relu')(X)
# MAXPOOL
X = MaxPooling2D((2, 2), name='max_pool')(X)
# FLATTEN X (means convert it to a vector) + FULLYCONNECTED
X = Flatten()(X)
X = Dense(1, activation='sigmoid', name='fc')(X)
# Create model. This creates your Keras model instance,
# you'll use this instance to train/test the model.
model = Model(inputs = X_input, outputs = X, name='HappyModel')
return model
本次作業很open,可以自由搭建模型,修改超引數,請注意各層之間的維度匹配
Keras Model 類參考鏈接
- 定義模型
# GRADED FUNCTION: HappyModel
def HappyModel(input_shape):
"""
Implementation of the HappyModel.
Arguments:
input_shape -- shape of the images of the dataset
Returns:
model -- a Model() instance in Keras
"""
### START CODE HERE ###
# Feel free to use the suggested outline in the text above to get started, and run through the whole
# exercise (including the later portions of this notebook) once. The come back also try out other
# network architectures as well.
X_input = Input(input_shape)
X = ZeroPadding2D((3,3))(X_input)
X = Conv2D(32,(7,7), strides = (1,1), name='conv0')(X)
X = BatchNormalization(axis = 3, name='bn0')(X)
X = Activation('relu')(X)
X = MaxPooling2D((2,2), name='max_pool')(X)
X = Flatten()(X)
X = Dense(1, activation='sigmoid', name='fc')(X)
model = Model(inputs = X_input, outputs = X, name='HappyModel')
### END CODE HERE ###
return model
- 創建模型實體
happyModel = HappyModel(X_train[0].shape)
- 配置訓練模型
import keras
opt = keras.optimizers.Adam(learning_rate=0.01)
happyModel.compile(optimizer=opt,
loss=keras.losses.BinaryCrossentropy(),metrics=['acc'])
- 訓練 并 存盤回傳的訓練程序資料用于可視化
history = happyModel.fit(x=X_train, y=Y_train,
validation_split=0.25, batch_size=32, epochs=30)
- 繪制訓練程序
# 繪制訓練 & 驗證的準確率值
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
# 繪制訓練 & 驗證的損失值
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
,,,省略
Epoch 29/30
15/15 [==============================]
- 2s 148ms/step - loss: 0.1504 - acc: 0.9733 - val_loss: 0.1518 - val_acc: 0.9600
Epoch 30/30
15/15 [==============================]
- 2s 147ms/step - loss: 0.1160 - acc: 0.9711 - val_loss: 0.2242 - val_acc: 0.9333
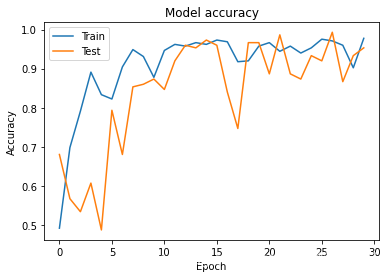
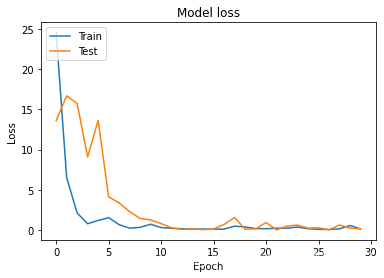
- 測驗模型效果
### START CODE HERE ### (1 line)
from keras import metrics
preds = happyModel.evaluate(X_test, Y_test, batch_size=32, verbose=1, sample_weight=None)
### END CODE HERE ###
print(preds)
print ("Loss = " + str(preds[0]))
print ("Test Accuracy = " + str(preds[1]))
輸出:
5/5 [==============================] - 0s 20ms/step - loss: 0.2842 - acc: 0.9400
[0.28415805101394653, 0.9399999976158142]
Loss = 0.28415805101394653
Test Accuracy = 0.9399999976158142
3. 用你的圖片測驗
### START CODE HERE ###
img_path = 'images/1.jpg'
### END CODE HERE ###
img = image.load_img(img_path, target_size=(64, 64))
imshow(img)
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
print(happyModel.predict(x))

4. 一些有用的Keras函式
happyModel.summary()模型的結構,引數等資訊
happyModel.summary()
Model: "HappyModel"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 64, 64, 3)] 0
_________________________________________________________________
zero_padding2d (ZeroPadding2 (None, 70, 70, 3) 0
_________________________________________________________________
conv0 (Conv2D) (None, 64, 64, 32) 4736
_________________________________________________________________
bn0 (BatchNormalization) (None, 64, 64, 32) 128
_________________________________________________________________
activation (Activation) (None, 64, 64, 32) 0
_________________________________________________________________
max_pool (MaxPooling2D) (None, 32, 32, 32) 0
_________________________________________________________________
flatten (Flatten) (None, 32768) 0
_________________________________________________________________
fc (Dense) (None, 1) 32769
=================================================================
Total params: 37,633
Trainable params: 37,569
Non-trainable params: 64
_________________________________________________________________
plot_model()把模型結構保存成圖片
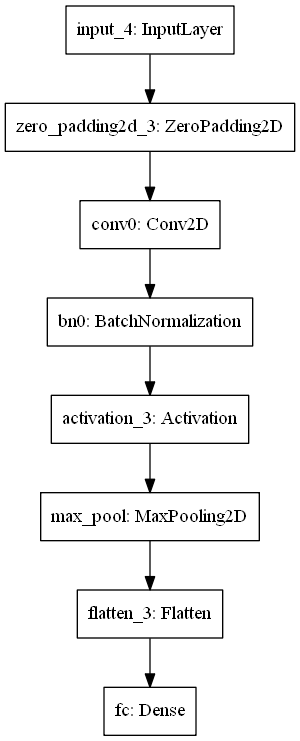
作業2:殘差網路 Residual Networks
使用殘差網路能夠訓練更深的神經網路,普通的深層神經網路是很難訓練的,
- 匯入包
import numpy as np
from keras import layers
from keras.layers import Input, Add, Dense, Activation, ZeroPadding2D, BatchNormalization, Flatten, Conv2D, AveragePooling2D, MaxPooling2D, GlobalMaxPooling2D
from keras.models import Model, load_model
from keras.preprocessing import image
from keras.utils import layer_utils
from keras.utils.data_utils import get_file
from keras.applications.imagenet_utils import preprocess_input
import pydot
from IPython.display import SVG
from keras.utils.vis_utils import model_to_dot
from keras.utils import plot_model
from resnets_utils import *
from keras.initializers import glorot_uniform
import scipy.misc
from matplotlib.pyplot import imshow
%matplotlib inline
import keras.backend as K
K.set_image_data_format('channels_last')
K.set_learning_phase(1)
1. 深層神經網路的問題
深層網路優點:
- 可以表示復雜的函式
- 可以學習很多不同層次的特征(低層次,高層次)
缺點:
- 梯度消失/爆炸,梯度變的非常小或者非常大
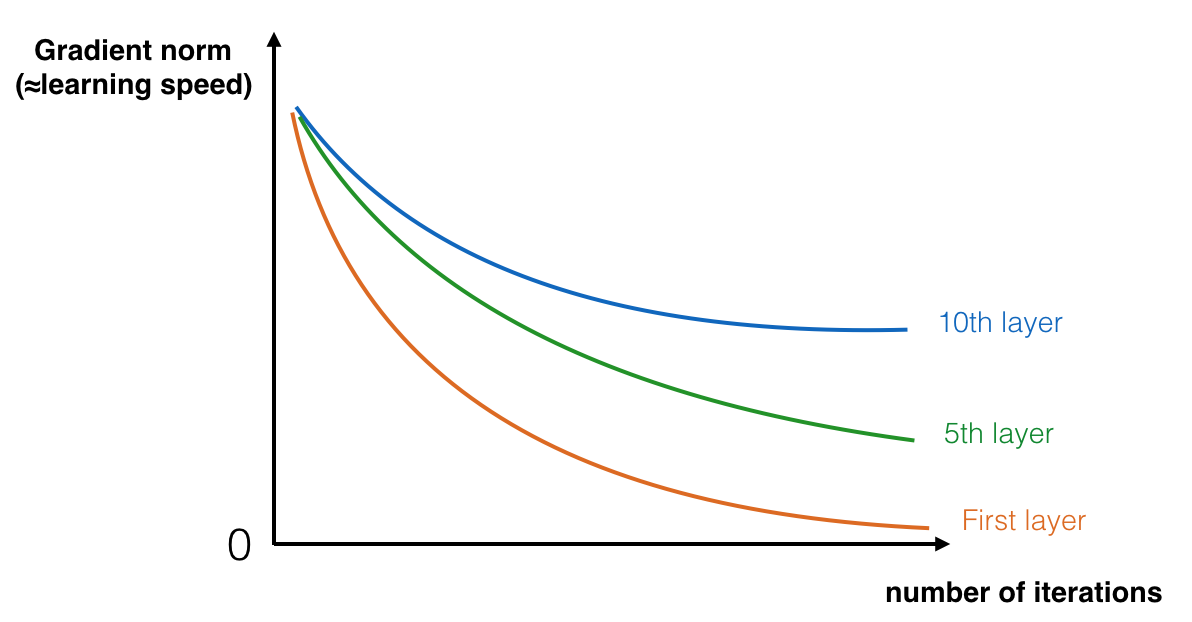
隨著迭代次數增加,淺層的梯度很快的就降到 0
2. 建立殘差網路
通過跳躍的連接,允許梯度直接反向傳到淺層

- 跳躍連接使得模塊更容易學習恒等函式
- 殘差模塊不會損害訓練效果
殘差網路有兩種型別的模塊,主要取決于輸入輸出的維度是否一樣
2.1 identity恒等模塊
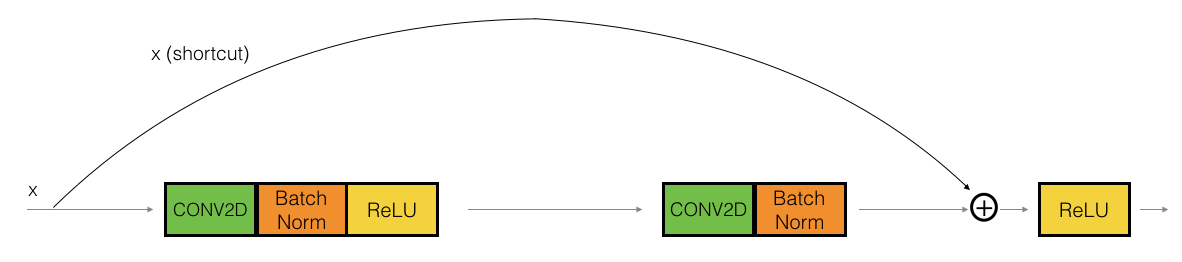
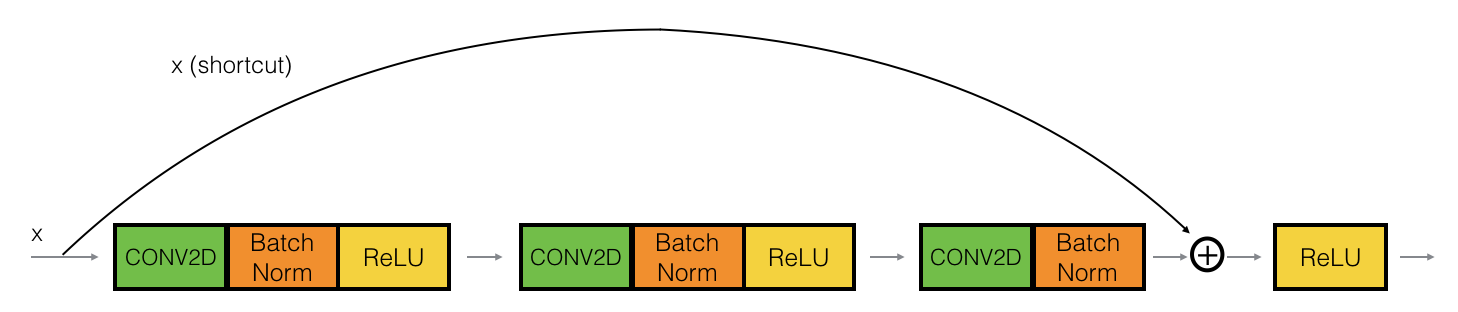
下面我們要實作:跳過3個隱藏層的結構,其稍微更強大一些
convolution2d 參考:https://keras.io/api/layers/convolution_layers/convolution2d/
batch_normalization 參考:
https://keras.io/api/layers/normalization_layers/batch_normalization/
add 參考:
https://keras.io/api/layers/merging_layers/add/
# GRADED FUNCTION: identity_block
def identity_block(X, f, filters, stage, block):
"""
Implementation of the identity block as defined in Figure 3
Arguments:
X -- input tensor of shape (m, n_H_prev, n_W_prev, n_C_prev)
f -- integer, specifying the shape of the middle CONV's window for the main path
filters -- python list of integers, defining the number of filters in the CONV layers of the main path
stage -- integer, used to name the layers, depending on their position in the network
block -- string/character, used to name the layers, depending on their position in the network
Returns:
X -- output of the identity block, tensor of shape (n_H, n_W, n_C)
"""
# defining name basis
conv_name_base = 'res' + str(stage) + block + '_branch'
bn_name_base = 'bn' + str(stage) + block + '_branch'
# Retrieve Filters
F1, F2, F3 = filters
# Save the input value. You'll need this later to add back to the main path.
X_shortcut = X
# First component of main path
X = Conv2D(filters = F1, kernel_size = (1, 1), strides = (1,1), padding = 'valid', name = conv_name_base + '2a', kernel_initializer = glorot_uniform(seed=0))(X)
X = BatchNormalization(axis = 3, name = bn_name_base + '2a')(X)
X = Activation('relu')(X)
### START CODE HERE ###
# Second component of main path (≈3 lines)
X = Conv2D(filters = F2, kernel_size=(f, f), strides = (1, 1), padding='same', name=conv_name_base+'2b', kernel_initializer=glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3, name=bn_name_base+'2b')(X)
X = Activation('relu')(X)
# Third component of main path (≈2 lines)
X = Conv2D(filters=F3, kernel_size=(1,1), strides=(1,1), padding='valid', name=conv_name_base+'2c', kernel_initializer=glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3, name=bn_name_base+'2c')(X)
# Final step: Add shortcut value to main path, and pass it through a RELU activation (≈2 lines)
X = Add()([X_shortcut, X])
X = Activation('relu')(X)
### END CODE HERE ###
return X
測驗代碼:
# import tensorflow.compat.v1 as tf
# tf.disable_v2_behavior()
tf.reset_default_graph()
with tf.Session() as test:
np.random.seed(1)
A_prev = tf.placeholder("float", [3, 4, 4, 6])
X = np.random.randn(3, 4, 4, 6)
A = identity_block(A_prev, f = 2, filters = [2, 4, 6], stage = 1, block = 'a')
test.run(tf.global_variables_initializer())
out = test.run([A], feed_dict={A_prev: X, K.learning_phase(): 0})
print("out = " + str(out[0][1][1][0]))
輸出:
out = [0.19716819 0. 1.3561226 2.1713073 0. 1.3324987 ]
2.2 卷積模塊
該模塊可以適用于:輸入輸出維度不匹配的情況
其 跳躍連接上有一個 CONV2D 卷積層,它沒有使用非線性激活函式,作用是改變輸入的維度,使后面的加法維度匹配
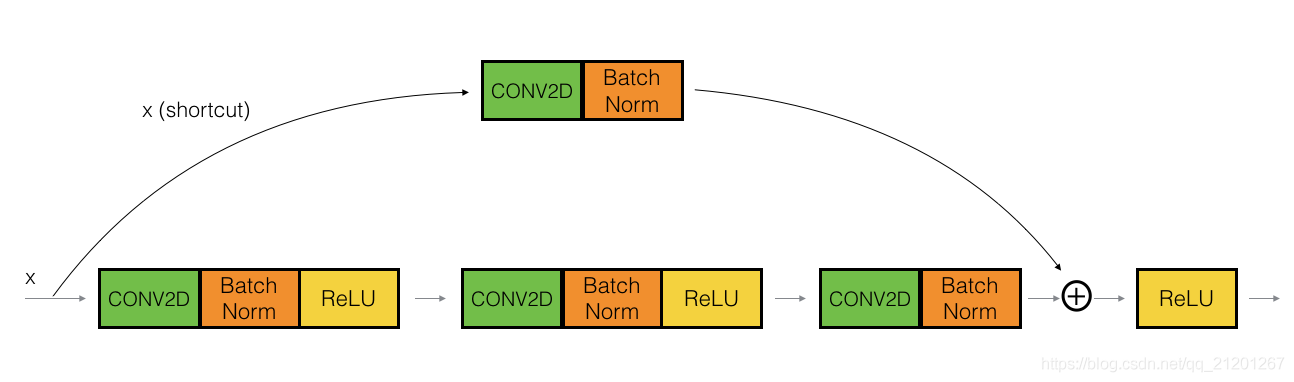
# GRADED FUNCTION: convolutional_block
def convolutional_block(X, f, filters, stage, block, s = 2):
"""
Implementation of the convolutional block as defined in Figure 4
Arguments:
X -- input tensor of shape (m, n_H_prev, n_W_prev, n_C_prev)
f -- integer, specifying the shape of the middle CONV's window for the main path
filters -- python list of integers, defining the number of filters in the CONV layers of the main path
stage -- integer, used to name the layers, depending on their position in the network
block -- string/character, used to name the layers, depending on their position in the network
s -- Integer, specifying the stride to be used
Returns:
X -- output of the convolutional block, tensor of shape (n_H, n_W, n_C)
"""
# defining name basis
conv_name_base = 'res' + str(stage) + block + '_branch'
bn_name_base = 'bn' + str(stage) + block + '_branch'
# Retrieve Filters
F1, F2, F3 = filters
# Save the input value
X_shortcut = X
##### MAIN PATH #####
# First component of main path
X = Conv2D(F1, (1, 1), strides = (s,s), padding = 'valid', name = conv_name_base + '2a', kernel_initializer = glorot_uniform(seed=0))(X)
X = BatchNormalization(axis = 3, name = bn_name_base + '2a')(X)
X = Activation('relu')(X)
### START CODE HERE ###
# Second component of main path (≈3 lines)
X = Conv2D(F2, (f,f), strides=(1,1),padding='same',name=conv_name_base+'2b',kernel_initializer=glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3, name=bn_name_base+'2b')(X)
X = Activation('relu')(X)
# Third component of main path (≈2 lines)
X = Conv2D(F3,(1,1), strides=(1,1),padding='valid',name=conv_name_base+'2c',kernel_initializer=glorot_uniform(seed=0))(X)
X = BatchNormalization(axis=3, name=bn_name_base+'2c')(X)
##### SHORTCUT PATH #### (≈2 lines)
X_shortcut = Conv2D(F3, (1,1), strides=(s,s),padding='valid',name=conv_name_base+'1',kernel_initializer=glorot_uniform(seed=0))(X_shortcut)
X_shortcut = BatchNormalization(axis=3, name=bn_name_base+'1')(X_shortcut)
# Final step: Add shortcut value to main path, and pass it through a RELU activation (≈2 lines)
X = Add()([X, X_shortcut])
X = Activation('relu')(X)
### END CODE HERE ###
return X
測驗:
tf.reset_default_graph()
with tf.Session() as test:
np.random.seed(1)
A_prev = tf.placeholder("float", [3, 4, 4, 6])
X = np.random.randn(3, 4, 4, 6)
A = convolutional_block(A_prev, f = 2, filters = [2, 4, 6], stage = 1, block = 'a')
test.run(tf.global_variables_initializer())
out = test.run([A], feed_dict={A_prev: X, K.learning_phase(): 0})
print("out = " + str(out[0][1][1][0]))
輸出:
out = [0.09018463 1.2348979 0.46822023 0.03671762 0. 0.65516603]
3. 建立你的第一個殘差網路(50層)
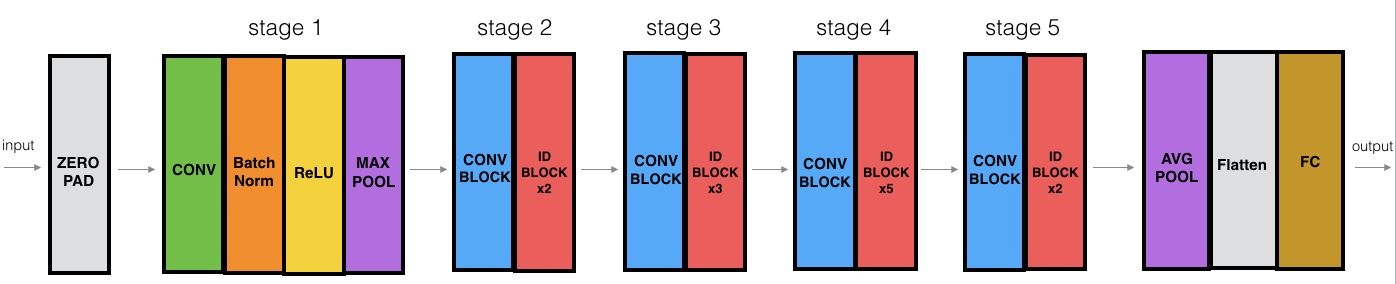
ID(Identity)恒等模塊,ID BLOCK x3 表示恒等模塊3次
pooling 參考 https://keras.io/zh/layers/pooling/
# GRADED FUNCTION: ResNet50
def ResNet50(input_shape = (64, 64, 3), classes = 6):
"""
Implementation of the popular ResNet50 the following architecture:
CONV2D -> BATCHNORM -> RELU -> MAXPOOL -> CONVBLOCK -> IDBLOCK*2 -> CONVBLOCK -> IDBLOCK*3
-> CONVBLOCK -> IDBLOCK*5 -> CONVBLOCK -> IDBLOCK*2 -> AVGPOOL -> TOPLAYER
Arguments:
input_shape -- shape of the images of the dataset
classes -- integer, number of classes
Returns:
model -- a Model() instance in Keras
"""
# Define the input as a tensor with shape input_shape
X_input = Input(input_shape)
# Zero-Padding
X = ZeroPadding2D((3, 3))(X_input)
# Stage 1
X = Conv2D(64, (7, 7), strides = (2, 2), name = 'conv1', kernel_initializer = glorot_uniform(seed=0))(X)
X = BatchNormalization(axis = 3, name = 'bn_conv1')(X)
X = Activation('relu')(X)
X = MaxPooling2D((3, 3), strides=(2, 2))(X)
# Stage 2
X = convolutional_block(X, f = 3, filters = [64, 64, 256], stage = 2, block='a', s = 1)
X = identity_block(X, 3, [64, 64, 256], stage=2, block='b')
X = identity_block(X, 3, [64, 64, 256], stage=2, block='c')
### START CODE HERE ###
# Stage 3 (≈4 lines)
X = convolutional_block(X, f=3, filters=[128,128,512], stage=3, block='a', s=2)
X = identity_block(X, 3, [128,128,512],stage=3, block='b')
X = identity_block(X, 3, [128,128,512],stage=3, block='c')
X = identity_block(X, 3, [128,128,512],stage=3, block='d')
# Stage 4 (≈6 lines)
X = convolutional_block(X, f=3, filters=[256,256,1024], stage=4, block='a', s=2)
X = identity_block(X, 3, [256,256,1024],stage=4, block='b')
X = identity_block(X, 3, [256,256,1024],stage=4, block='c')
X = identity_block(X, 3, [256,256,1024],stage=4, block='d')
X = identity_block(X, 3, [256,256,1024],stage=4, block='e')
X = identity_block(X, 3, [256,256,1024],stage=4, block='f')
# Stage 5 (≈3 lines)
X = convolutional_block(X, f=3, filters=[512,512,2048], stage=5, block='a', s=2)
X = identity_block(X, 3, [512,512,2048], stage=5, block='b')
X = identity_block(X, 3, [512,512,2048], stage=5, block='c')
# AVGPOOL (≈1 line). Use "X = AveragePooling2D(...)(X)"
X = AveragePooling2D(pool_size=(2,2))(X)
### END CODE HERE ###
# output layer
X = Flatten()(X)
X = Dense(classes, activation='softmax', name='fc' + str(classes), kernel_initializer = glorot_uniform(seed=0))(X)
# Create model
model = Model(inputs = X_input, outputs = X, name='ResNet50')
return model
- 建立模型
model = ResNet50(input_shape = (64, 64, 3), classes = 6)
- 配置模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
- 資料匯入 + one_hot 編碼

X_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = load_dataset()
# Normalize image vectors
X_train = X_train_orig/255.
X_test = X_test_orig/255.
# Convert training and test labels to one hot matrices
Y_train = convert_to_one_hot(Y_train_orig, 6).T
Y_test = convert_to_one_hot(Y_test_orig, 6).T
print ("number of training examples = " + str(X_train.shape[0]))
print ("number of test examples = " + str(X_test.shape[0]))
print ("X_train shape: " + str(X_train.shape))
print ("Y_train shape: " + str(Y_train.shape))
print ("X_test shape: " + str(X_test.shape))
print ("Y_test shape: " + str(Y_test.shape))
輸出:
number of training examples = 1080
number of test examples = 120
X_train shape: (1080, 64, 64, 3)
Y_train shape: (1080, 6)
X_test shape: (120, 64, 64, 3)
Y_test shape: (120, 6)
- 訓練(迭代兩次測驗下)
model.fit(X_train, Y_train, epochs = 2, batch_size = 32)
輸出:(損失在下降,準確率在上升)
Epoch 1/2
1080/1080 [==============================]
- 208s 192ms/step - loss: 2.6086 - acc: 0.3037
Epoch 2/2
1080/1080 [==============================]
- 193s 178ms/step - loss: 2.2677 - acc: 0.3972
- 測驗
preds = model.evaluate(X_test, Y_test)
print ("Loss = " + str(preds[0]))
print ("Test Accuracy = " + str(preds[1]))
輸出:(準確率 19%)
120/120 [==============================] - 5s 38ms/step
Loss = 12.753657023111979
Test Accuracy = 0.19166666467984517
該模型訓練2次效果很差,訓練更多次效果才會好(時間比較久)
老師直接給出了訓練好的模型
model = load_model('ResNet50.h5')
preds = model.evaluate(X_test, Y_test)
print ("Loss = " + str(preds[0]))
print ("Test Accuracy = " + str(preds[1]))
Loss = 0.5301782568295796
Test Accuracy = 0.8666667
老師給的 ResNets 殘差網路 預測準確率為 86.7%
前次作業中 TF 3層網路模型的預測準確率為 72.5%
4. 用自己的照片測驗
import imageio
img_path = 'images/my_image.jpg'
img = image.load_img(img_path, target_size=(64, 64))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
print('Input image shape:', x.shape)
my_image = imageio.imread(img_path)
imshow(my_image)
print("class prediction vector [p(0), p(1), p(2), p(3), p(4), p(5)] = ")
print(model.predict(x))
輸出:
Input image shape: (1, 64, 64, 3)
class prediction vector [p(0), p(1), p(2), p(3), p(4), p(5)] =
[[1. 0. 0. 0. 0. 0.]]

- 模型結構總結
model.summary()
Model: "ResNet50"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 64, 64, 3)] 0
__________________________________________________________________________________________________
zero_padding2d_1 (ZeroPadding2D (None, 70, 70, 3) 0 input_1[0][0]
__________________________________________________________________________________________________
conv1 (Conv2D) (None, 32, 32, 64) 9472 zero_padding2d_1[0][0]
__________________________________________________________________________________________________
bn_conv1 (BatchNormalization) (None, 32, 32, 64) 256 conv1[0][0]
__________________________________________________________________________________________________
activation_4 (Activation) (None, 32, 32, 64) 0 bn_conv1[0][0]
__________________________________________________________________________________________________
max_pooling2d_1 (MaxPooling2D) (None, 15, 15, 64) 0 activation_4[0][0]
__________________________________________________________________________________________________
res2a_branch2a (Conv2D) (None, 15, 15, 64) 4160 max_pooling2d_1[0][0]
________________________________________________________________________
省略省略省略省略
省略省略省略省略
add_16 (Add) (None, 2, 2, 2048) 0 bn5b_branch2c[0][0]
activation_46[0][0]
__________________________________________________________________________________________________
activation_49 (Activation) (None, 2, 2, 2048) 0 add_16[0][0]
__________________________________________________________________________________________________
res5c_branch2a (Conv2D) (None, 2, 2, 512) 1049088 activation_49[0][0]
__________________________________________________________________________________________________
bn5c_branch2a (BatchNormalizati (None, 2, 2, 512) 2048 res5c_branch2a[0][0]
__________________________________________________________________________________________________
activation_50 (Activation) (None, 2, 2, 512) 0 bn5c_branch2a[0][0]
__________________________________________________________________________________________________
res5c_branch2b (Conv2D) (None, 2, 2, 512) 2359808 activation_50[0][0]
__________________________________________________________________________________________________
bn5c_branch2b (BatchNormalizati (None, 2, 2, 512) 2048 res5c_branch2b[0][0]
__________________________________________________________________________________________________
activation_51 (Activation) (None, 2, 2, 512) 0 bn5c_branch2b[0][0]
__________________________________________________________________________________________________
res5c_branch2c (Conv2D) (None, 2, 2, 2048) 1050624 activation_51[0][0]
__________________________________________________________________________________________________
bn5c_branch2c (BatchNormalizati (None, 2, 2, 2048) 8192 res5c_branch2c[0][0]
__________________________________________________________________________________________________
add_17 (Add) (None, 2, 2, 2048) 0 bn5c_branch2c[0][0]
activation_49[0][0]
__________________________________________________________________________________________________
activation_52 (Activation) (None, 2, 2, 2048) 0 add_17[0][0]
__________________________________________________________________________________________________
avg_pool (AveragePooling2D) (None, 1, 1, 2048) 0 activation_52[0][0]
__________________________________________________________________________________________________
flatten_1 (Flatten) (None, 2048) 0 avg_pool[0][0]
__________________________________________________________________________________________________
fc6 (Dense) (None, 6) 12294 flatten_1[0][0]
==================================================================================================
Total params: 23,600,006
Trainable params: 23,546,886
Non-trainable params: 53,120
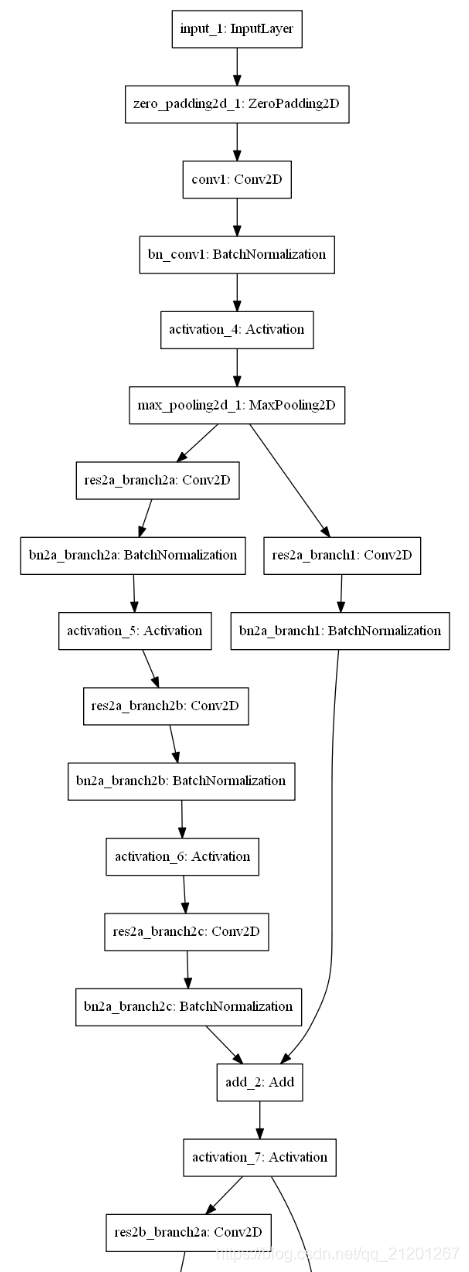
- 繪制模型結構圖
plot_model(model, to_file='model.png')
SVG(model_to_dot(model).create(prog='dot', format='svg'))
圖片很長,只截取部分
參考論文
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun - Deep Residual Learning for Image Recognition (2015)
- Francois Chollet’s github repository: https://github.com/fchollet/deep-learning-models/blob/master/resnet50.py
我的CSDN博客地址 https://michael.blog.csdn.net/
長按或掃碼關注我的公眾號(Michael阿明),一起加油、一起學習進步!
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/123236.html
標籤:其他