外鍵(Foreign Key)
如果今天有一張表上面有很多職務的資訊
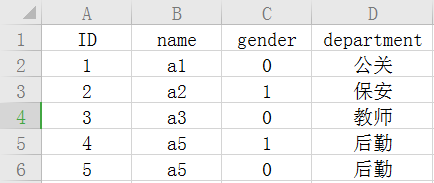
我們可以通過使用外鍵的方式去將兩張表產生關聯
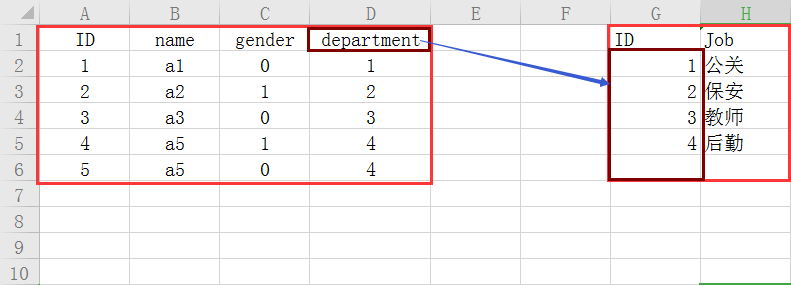
這樣的好處能夠節省空間,比方說你今天的職務名稱很長,在一張表中就要重復的去寫這個職務的名字,很浪費空間;除此之外也能起到一個約束的作用,
像department就是外鍵,
執行代碼:
create table t1( uid bigint auto_increment primary key, name varchar(32), department_id int, gender int, constraint fk_user_depar foreign key ("department_id",) references department("id") )engine=innodb default charset=utf8; create table t2( id bigint auto_increment primary key, job char(15), )engine=innodb default charset=utf8;
什么時候用主鍵?主鍵的作用?
保存資料的完整性,一個表只能有一個主鍵,一個主鍵可以由多列合成一個主鍵且主鍵不可為空
create table t1( uid bigint auto_increment, name varchar(32), department_id int, gender int, primary key(uid,gender) #將兩列合成為一個主鍵 constraint fk_user_depar foreign key ("department_id",) references department("id") )engine=innodb default charset=utf8;
ps:外鍵的名字不能重復,
多列和成的主鍵值對應另外一張表的多個列:
create table t1( uid bigint auto_increment, name varchar(32), department_id int, gender int, primary key(department_id,gender) #將兩列合成為一個主鍵 constraint fk_user_depar foreign key ("department_id","gender") references department("id","num_gender") )engine=innodb default charset=utf8; create table t2( id bigint auto_increment primary key, job char(15), num_gender bigint, )engine=innodb default charset=utf8;
自增列的起始值
desc 表名;
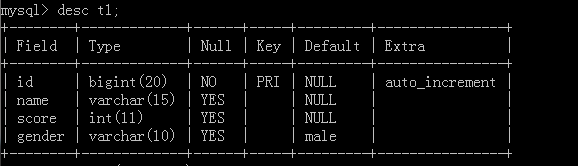
show create table 表名:
假設原表:
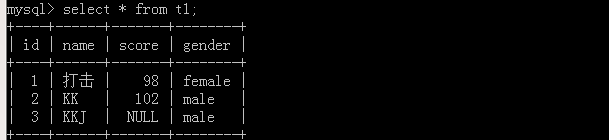
執行陳述句命令
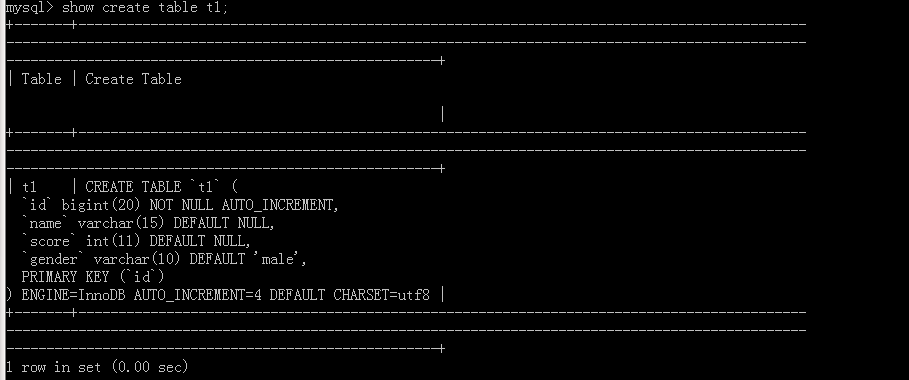
附加上命令\G
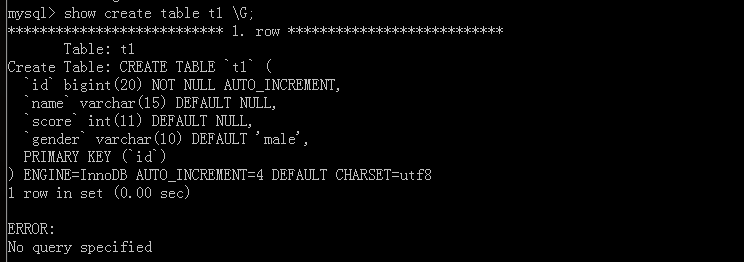
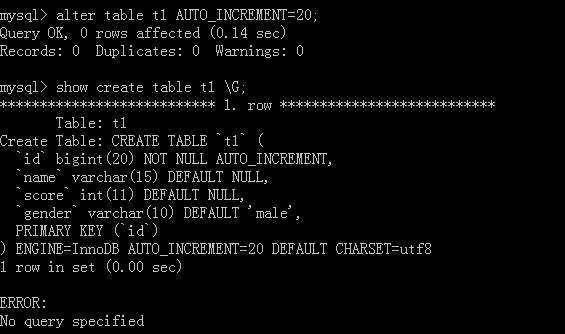
可以看出這就是我們寫的SQL陳述句,但是沒有‘AUTO_INCREMENT=4’,因為原表中有三個資料,這里表示下一次的自增值是4,
我們再去加上兩筆資料看一看這里的自增值是怎么變得,
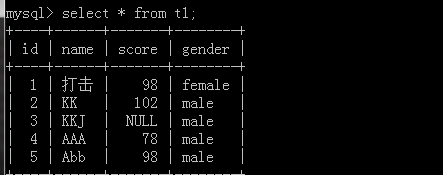
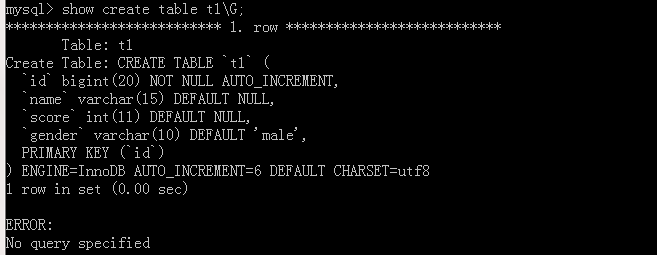
如果要去修改這個自增值,要使用alter table 表名 AUTO_CREMENT=值;
自增列的步長
Mysql的自增步長不好,因為它是基于會話級別,一次登錄就是一次會話
<1>基于會話級別:
陳述句:show session variables like 'auto_inc%' 查看全域變數
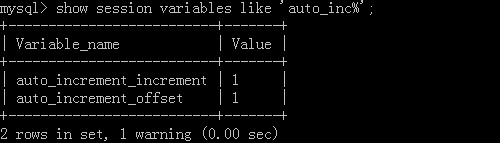
設定步長:set session auto_increment_increment=值;
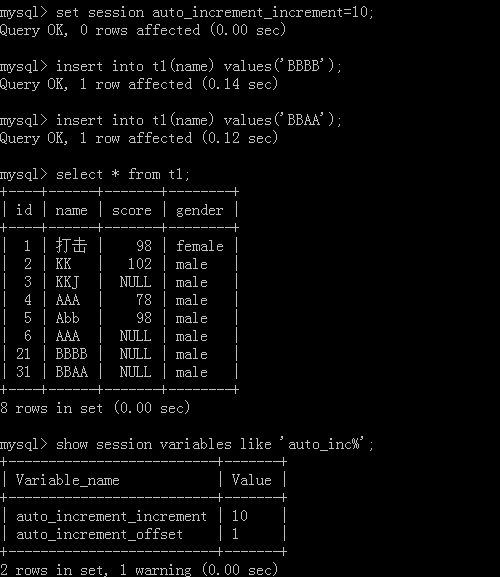
注意每一個會話的步長的都是獨立的,除非用全域去把每一個會話的全域變數去統一
修改當前會話的起始值:
set session auto_increment_offset=值;
<2>基于全域級別的:
它能夠讓所有人登錄時的步長都被修改成為一個統一的值
set global auto_increment_increment=200;
查看全域變數:
show global variables like 'auto_inc%';
修改全域的起始值:
set global auto_increment_offset=值;
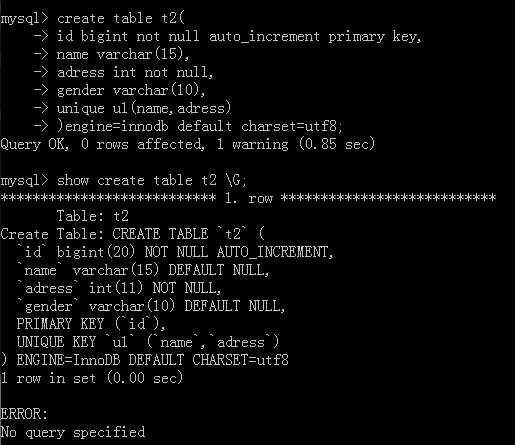
唯一索引
唯一索引的作用就是能夠加速查找和起到一個約束的作用
外鍵的變種
<1>一對多
例如:用戶和部門的關系
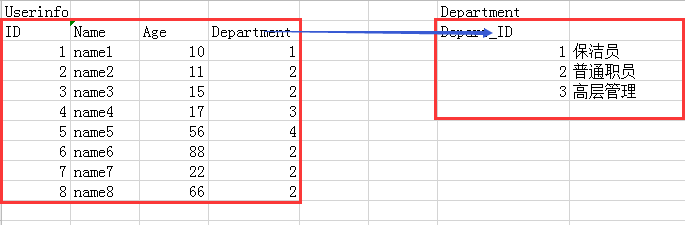
<2>一對一
例如:用戶表和博客表
需要用Foreign key和唯一索引去約束

如果想要制作一張員工表對應他們的權限關系,但只有高管才能去擁有權限去查看員工資料
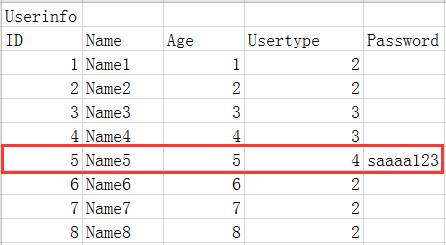
這里的Usertype是外鍵它所對應的是另外一張員工的職位表,但其實只有Usertype中的4是有權限去查看員工的資料的,所以其他員工的密碼這一欄會造成資源的浪費,那這里我們可以用另外一種方式去優化:
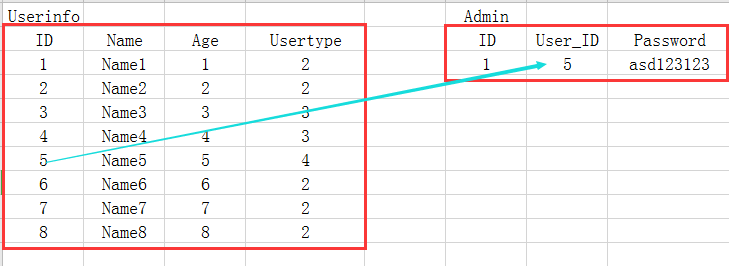
<3>多對多
一張表表示:
例如:百合網的相親記錄表
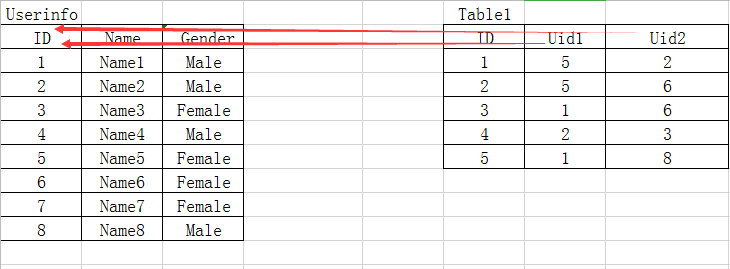
這里一共有兩個外鍵Uid1、Uid2共同指向ID
兩張表表示:
例如主機和用戶的關系表,一個用戶能夠掌控什么型別的主機
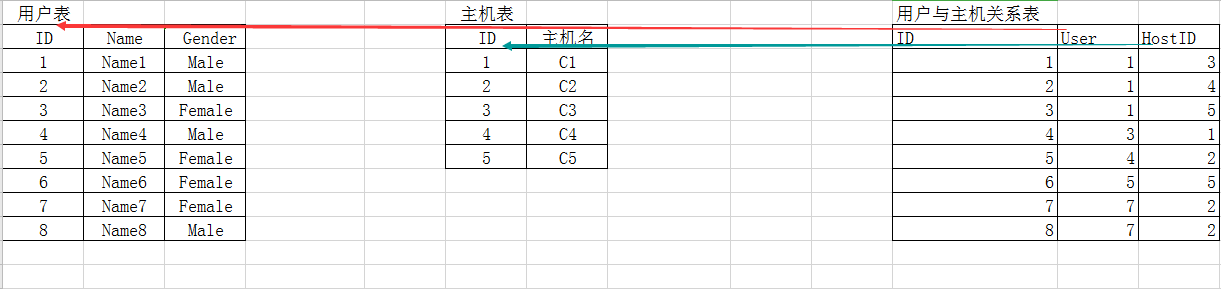
主要去表示的好處能夠讓我們很清楚的看到一個用戶掌握了幾臺主機且這臺主機被什么用戶給掌管的,User和HostID它要具有唯一性,
SQL陳述句資料行的一些補充
<1>.增
假設有一張表
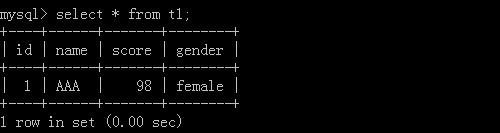
通過語法:insert into 表名(第一列資料名,第二列資料名...) values(對應的第一列值一,對應的第二列值一...),(對應的第一列值二,對應的第二列值二...),...;用這種方式可以插入多次的值,

查看一下新增的資料:
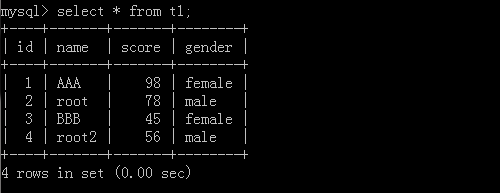
同樣的我們也可從一個表中提取資料到另外一張表中
原表就是上面新增完資料的表,然后我們再去創建一個新的表:
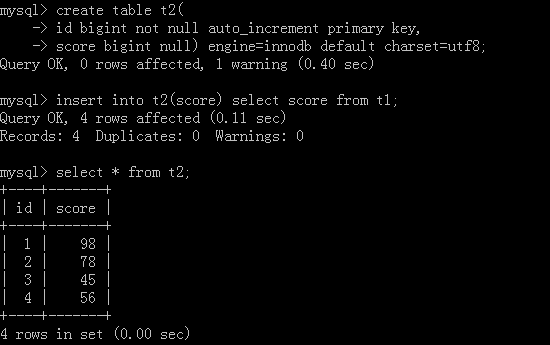
<2>.刪
分為無條件的情況和有條件的情況
無條件:
delete from 表名;
有條件:
1.delete from 表名 where ID != 2; 2.delete from 表名 where ID = 2; 3.delete from 表名 where ID > 2; #也可以是小于、大于等于、小于等于 4.delete from 表名 where ID < 2 and name = 'name1'; 5.delete from 表名 where ID >= 2 or name = 'name1;
<3>.改
1.改一條
update 表名 set name = 'name1' where id > 2 and name = 'AAA';
2.改多條
update 表名 set name = 'name1',age = 20 where id > 2 or name = 'AAA';
<4>.查
1.select * from 表名; 2.select id,name from 表名; 3.select id,name from 表名 where id > 10 or name = 'name1';
4.select id,name as 新名稱 from 表名 where id > 10 or name ='nam1';
原表格:
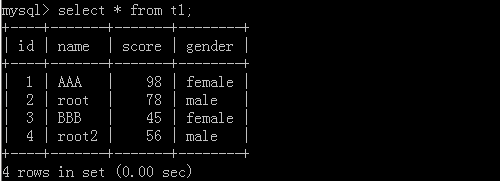
執行后:
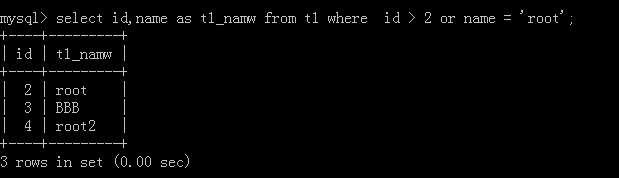
5.select name,age,'資料' from 表名;
原表格:
執行后:
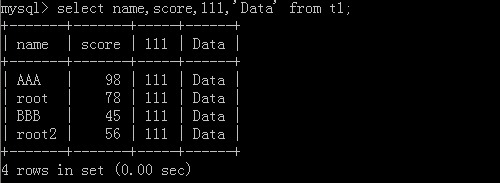
其他:
原表:
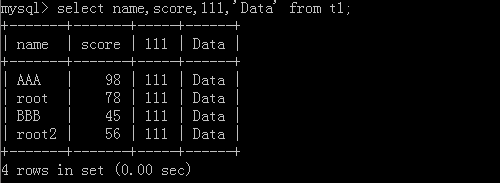
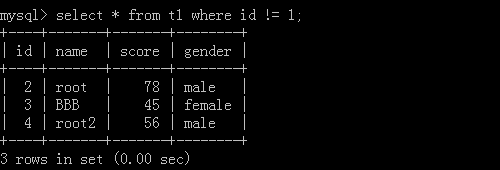
1.select * from t1 where id != 1;
執行結果:
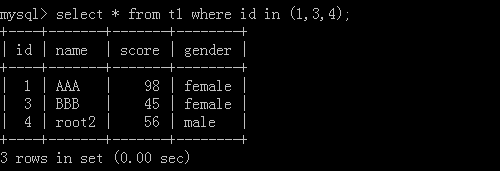
2.select * from t2 where id in (1,3,4);
執行結果:
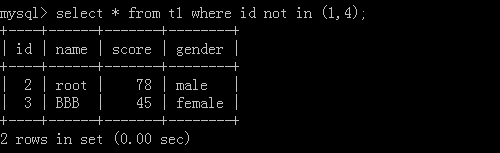
3.select * from t1 where id not in (1,4);
執行結果:
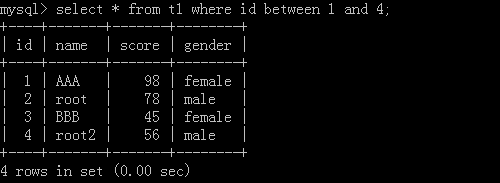
4.select * from t1 where id between 1 and 4; --->[1,4]
執行結果:
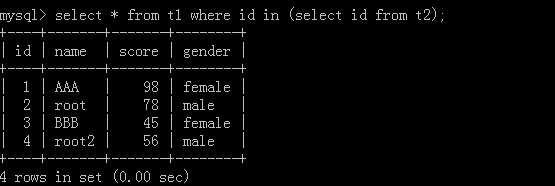
5. select * from t1 where id in (select score from t2);
t2表:

執行結果:
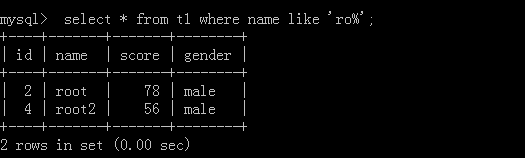
通配符:
'%':例如a%,a的后面可以去取任意個數的字符
'_':例如a_,a的后面只能取一個任意字符
1.select * from t1 where name like 'ro%';
執行結果:
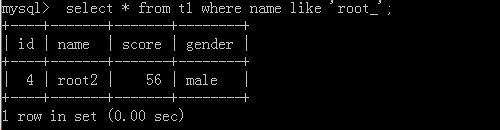
2.select * from t1 where name like 'root_';
執行結果:
限制:
比如說你去通過百度、谷歌查資料,它后面會給你分頁,一次看十條二十條,這樣不會讓電腦資源不夠導致崩潰,
原表格:
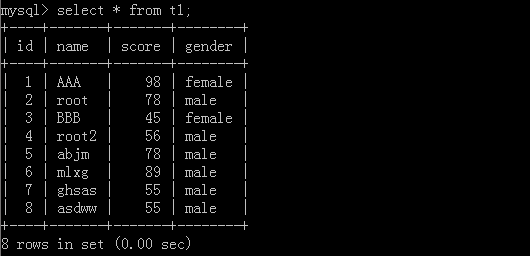
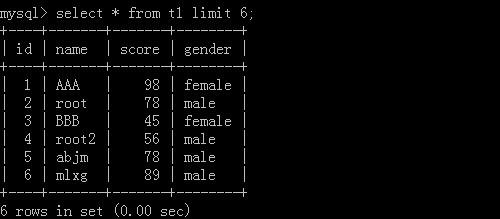
1.select * from t1 limit 6;
執行結果:
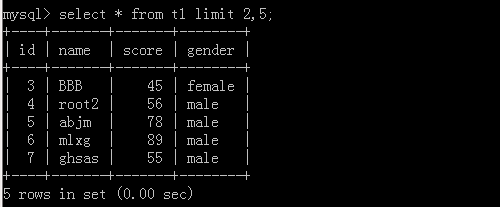
2.select * from t1 limit 2,5;
這里的2代表起始位址,5代表一共查幾筆資料
執行結果:
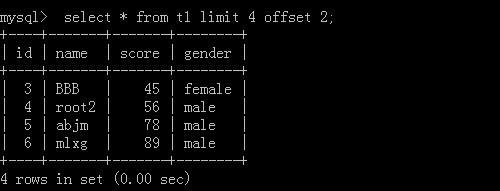
3.select * from t1 limit 10 offset 20;
這里表示從20開始,往后查10條資料
執行結果:
如果要查找后面10筆資料就要先把整筆資料進行翻轉再去查這10筆即可
排序:
從大到小查:
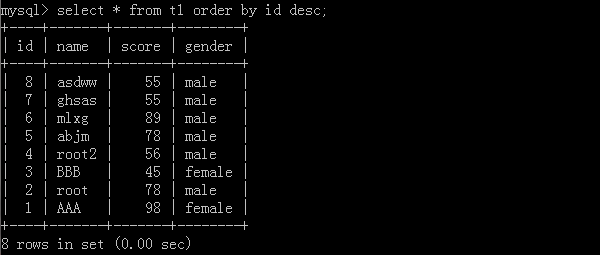
1.select * from t1 order by id desc;
利用id去進行從大到小排列資料,執行結果:
從小到大查:
2.select * from t1 order by id asc;
利用id去進行從小到大排列資料,執行結果:
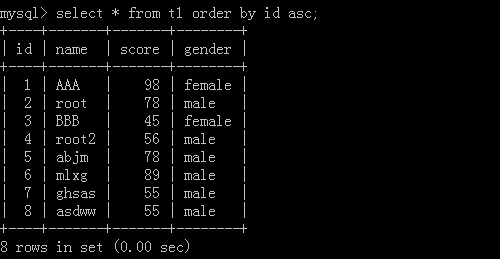
查后5筆資料:
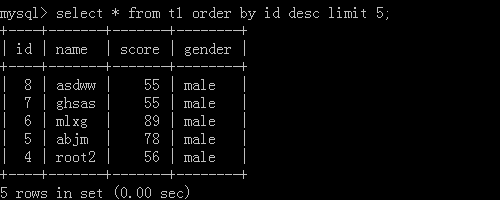
多列排序:
按排列優先順序去排,先把score按從大到小的方式排列,如果有score相同再去按它的id從小到大的方式排列
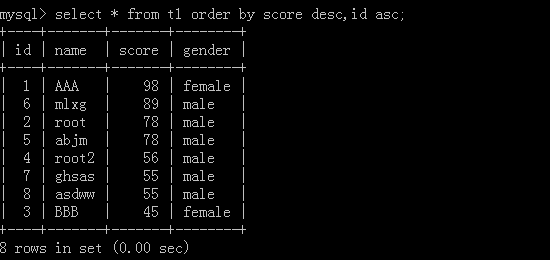
組合:
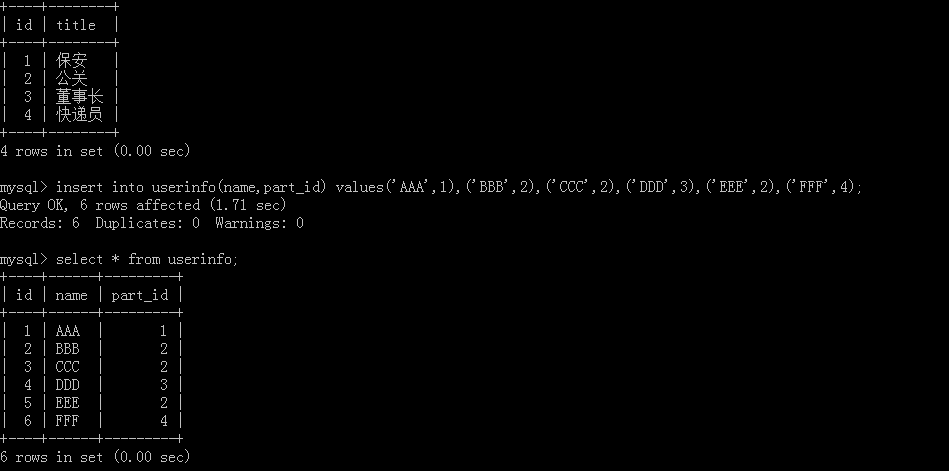
以員工和部門作為例子,先創建部門表:

再創建一個員工表:

添加員工資訊和部門資訊:


查看添加好的員工資訊表和部門資訊表:
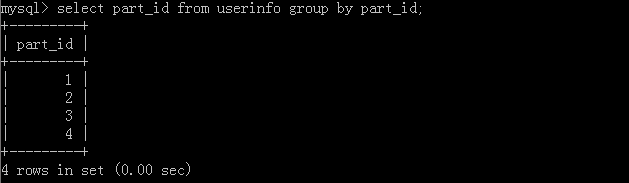
1.select part_id from userinfo group by part_id;
執行結果:
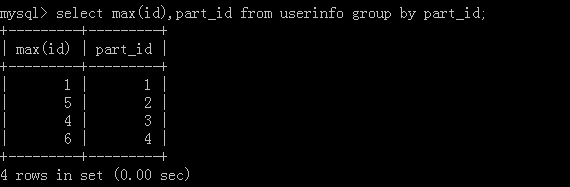
2.select max(id),part_id from userinfo group by part_id;
執行結果:
3.select min(id),part_id from userinfo group by part_id;
執行結果:

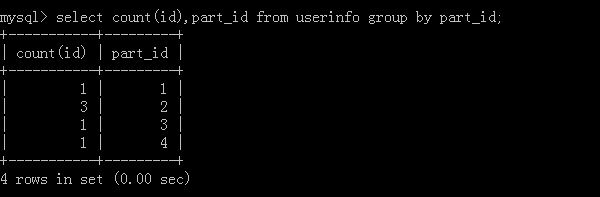
4.select count(id),part_id from userinfo group by part_id;
執行結果:
5.select sum(id),part_id from userinfo group by part_id;
執行結果:

6.select avg(id),part_id from userinfo group by part_id;
執行結果:

7.select count(id),part_id from userinfo group by part_id having count(id) > 1;
如果對于聚合函式結果進行二次篩選時就必須要用到having關鍵字,執行結果:

8.select count(id),part_id from userinfo where id = 1 or id < 4 group by part_id having count(id) > 1;
執行結果:

連表操作:
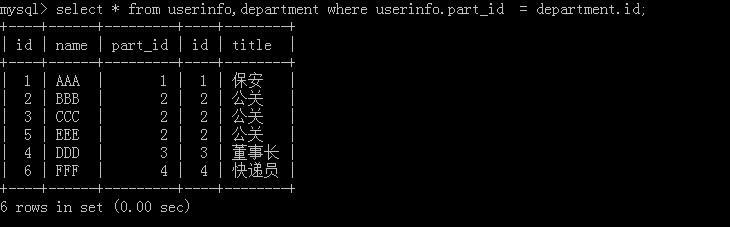
1.select * from userinfo,department where userinfo,part_id = department_id;
把兩張表進行一個連接操作,如果后面不加條件就會出現混亂,執行結果:
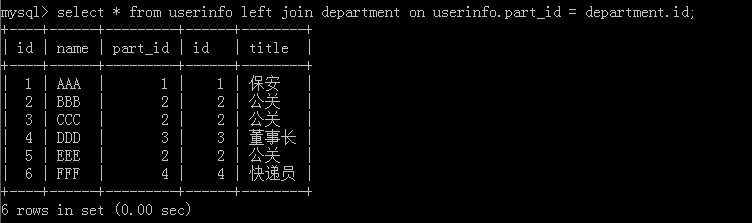
2.select * from userinfo left join department on userinfo.part_id = department.id;
這種方法按以前SQL版本效能上會有差異,但現在其實沒有太大的相差,但推薦使用這一個去進行表的連接,特點:左邊的表userinfo會全部顯示,執行結果:
3.select * from userinfo right join department on userinfo.part_id =department.id;
特點:右邊表department的資料會全部顯示
4.select * from userinfo inner join department where userinfo.part_id = department.id;
如果一個表連另外一張表的資料時,出現NULL時,就會把整行資料給隱藏掉
補充
使用union可以進行上下連表,如果兩張表它有重復的地方會自動去重
SELECT sid, sname FROM studenttable UNION SELECT tid, tname FROM teachertable;
若要想要達到去重的效果,可以在union后加上all
SELECT sid, sname FROM studenttable UNION ALL SELECT tid, tname FROM teachertable;
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/124368.html
標籤:MySQL
上一篇:Mysql 控制結構初識
下一篇:MySQL復習值代碼知識點(1)