9 月初,我對 python 爬蟲 燃起興趣,但爬取到的資料多通道實時同步讀寫用檔案并不方便,于是開始用起mysql,這篇筆記,我將整理近一個月的實戰中最常用到的 mysql 陳述句,同時也將涉及到如何在python3中與 mysql 實作資料交換,
關于工具/庫,特別說明下:
1、我安裝了 mysql ,并直接采用管理員身份運行命令列提示符(cmd)查看 mysql,并沒有安裝任何 mysql 的可視化圖形界面工具,
2、在 python 腳本中,我采用 pymysql 和 sqlalchemy 這兩個庫與 mysql 建立連接,用 pandas 來處理資料,
一、建立連接與資料互動
與 mysql 互動的方式,我目前共使用 4 種,其中采用管理員身份運行命令列提示符(cmd)查看 mysql,其操作圖示可另寫一篇,這里就不占篇幅了,mysql的可視化圖形界面工具,我目前并沒有用到,也沒有迫切使用它的需要,另外 3 種方式都是通過 python 腳本進行,
情境A:python 演算得出資料,想要寫入資料庫
python 腳本已得到表格類大量資料,想要一次性寫入資料庫,常用代碼如下:
import pandas as pd
# 與 mysql 建立連接
from sqlalchemy import create_engine
conn_eng = create_engine('mysql+pymysql://username:password@localhost:3306/databasename',encoding='utf8')
# 呼叫 pandas 的方法,資料寫入mysql
pd.io.sql.to_sql(your_df, "table_name", conn_eng, if_exists='append',index=False)
表格類資料,我用的是 pandas 的 dataframe 結構,pd.io.sql.to_sql() 的引數還有許多其它用途,但上面這種是我個人使用最高頻的,效果是:無需自己提前建表,將自動建新表,美中不足是:表的列屬性自動生成,通常不合心意,還需檢查和修改,
如果不想用 pd.io.sql.to_sql() 或者想更精細、復雜的操作,則用到下面的情境C,
情境B:python 腳本想從 mysql 拿到資料
如果已經存在某個表格,想要向該表格提交某條指令,需回傳資料,我用的是 pandas的read_sql () ,回傳的資料型別是 pandas 的 dataframe,sql 查詢陳述句挺好寫的,具體總結在本文下方,
import pymysql
# 與 mysql 建立連接
conn = pymysql.connect('localhost','username','password','databasename')
# sql 陳述句定義為一個字串
sql_search = 'select question_id from topic_monitor where is_title=0 ;'
# 呼叫 pandas 的 read_sql() 方法拿到 dataframe 結構的資料
question_ids = pd.read_sql(sql_search,conn)
# 關閉連接
conn.close()
情境C:python 腳本單方面向 mysql 發出指令,無需拿到資料
如果已經存在某個表格,想要向該表格提交某條指令而無需回傳資料時,比如:建表、對資料的增改刪、對列的名稱、列的屬性修改等,代碼如下,
import pymysql
# 與 mysql 建立連接
conn = pymysql.connect('localhost','username','password','databasename')
cursor = conn.cursor()
# sql 陳述句定義為一個字串,插入一行資料
sql_insert = 'INSERT INTO questions(q_id,q_title,q_description,q_keywords,q_people,q_pageview,time) VALUES( "'\
+ str(quesition_id) + '", "' + str(one[0])+ '", "' + str(one[1]) + '", "' + str(one[2]) + '", "' \
+ str(one[3]) + '", "' + str(one[4]) + '", "' + str(datetime.datetime.now()) + '");'
# sql 陳述句定義為一個字串,修改某個資料(另一個表格)
sql_update = 'update topic_monitor SET is_title="1" where question_id = "' + str(quesition_id) + '";'
# 提交指令
cursor.execute(sql_insert)
cursor.execute(sql_update)
conn.commit()
# 插入一行資料;僅當該資料與表格已有資料不重復時才插入,否則就不會插入
sql_insert = 'INSERT INTO `topic_monitor`(question_id,is_title,q_type,topic_id,time) SELECT "'\
+ x[0] + '", "0", "0","' + str(topic_id) + '", "'+ str(now) + '" FROM DUAL WHERE NOT EXISTS(\
SELECT question_id FROM topic_monitor WHERE question_id = "' + x[0] + '")'
cursor.execute(sql_insert)
conn.commit()
# 關閉連接
cursor.close()
conn.close()
通過上面幾種實用情況可以看到,python 與 mysql 實作互動的程序,通常分為:建立連接、把sql陳述句定義為字串,提交指令、關閉連接,核心的技能在于 sql陳述句;除了定義sql陳述句字串,其余3個處理都是固定的寫法,
我在最初一個月的實踐中,最常出現的錯誤有:
- 值的參考沒有加上引號;
- 符號錯亂:多一個符號,少一個符號;
- 值的型別不符合:不管 mysql 表格中該值是數,還是文本,在定義 sql 陳述句的字串時,對每個值都需要轉化為字串;
- 拷貝自己的代碼時,忘記修改databasename,
二、sql陳述句:搜索查詢
搜索是指在資料庫的某個表格中查詢符合特定條件的資料,并回傳查詢結果,其基本結構為:
SELECT 【范圍】FROM table_name 【條件】; 其中,范圍是必須指定的,而條件可有可無,
變數A:范圍,是指回傳查詢結果的范圍,
回傳該表格的所有欄位,用 * 表達:
SELECT * FROM table_name ;
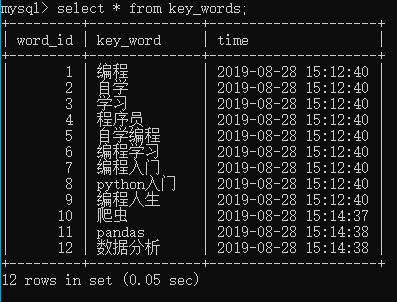
僅回傳該表格的某個欄位:
SELECT column_name FROM table_name ;
僅回傳該表格的多個欄位:
SELECT column_name_1,column_name_3,column_name_3 FROM table_name ;
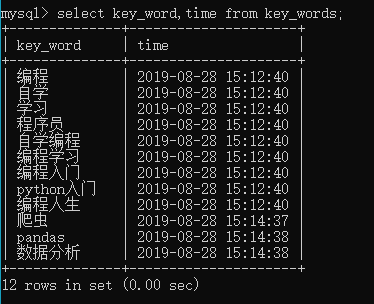
僅回傳符合條件的資料個數:
SELECT count(*) FROM table_name ;
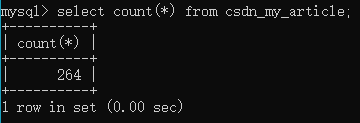
變數B:條件是指,期望回傳的資料滿足哪些條件,
不限定條件:
SELECT * FROM table_name ;
數值類:某個欄位(數值型別的,比如double或者int),數值比較的運算子都可以使用比如,大于>,小于<,等于 = ,大于等于 >= ,小于等于 <= :
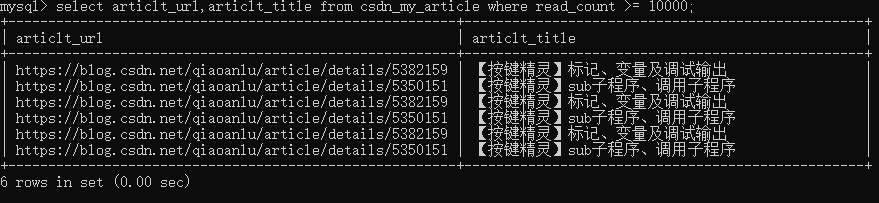
SELECT * FROM table_name WHERE num_column_name >= 1;
文本類:某個欄位(字串型別的,比如char,text):
SELECT * FROM table_name WHERE str_column_name like “%your_str%”;
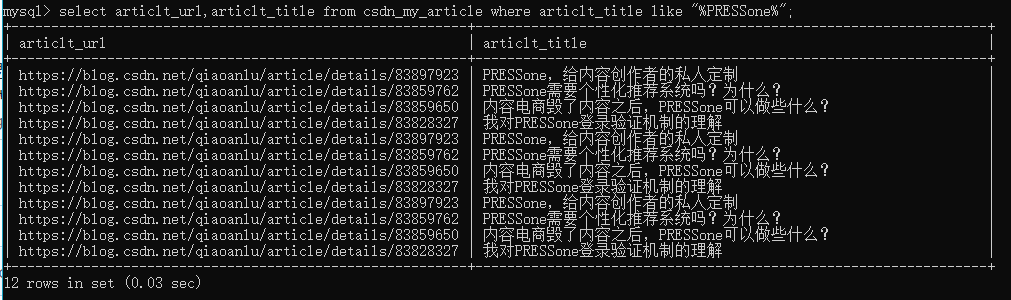
也可以表達多個條件,and,or等可用于表達條件之間的關系:
SELECT * FROM table_name WHERE num_column_name_1 >= 1 and str_column_name like “%your_str%” ;
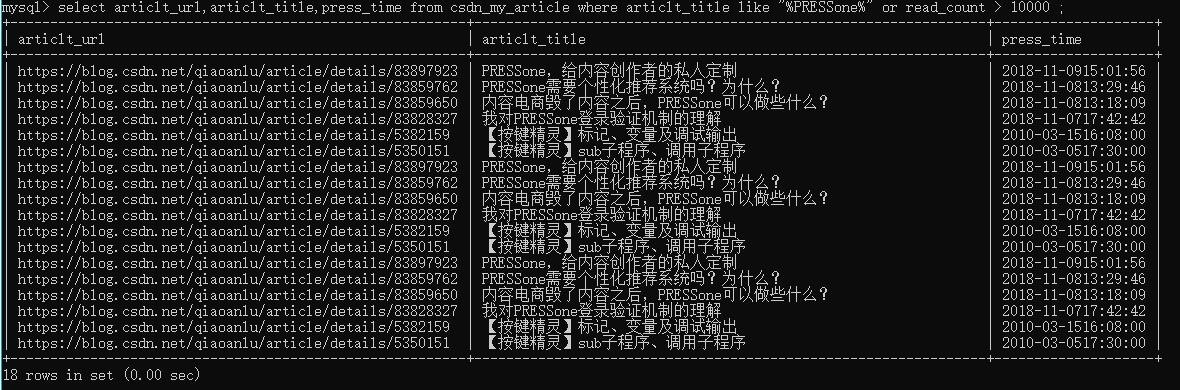
三、sql陳述句:修改表屬性
橫向的一整條資料,叫做行;豎向的一整條資料,叫作列,列的名字,叫做 column,這是通用的知識點,
這段時間的實戰中,我完全沒有用到修改表的名稱、重設index等知識點,最常用的,就是對列進行操作,每個列具備:列的名稱、列的屬性、列的數值,
列的名稱,需要留心不使用保留詞,我的技巧是,盡量用一些_來表達該資料,比如 article_title,press_date 這種命名雖然稍長,但易讀,也不會裝上保留詞,
列的屬性包括:型別,最大長度,是否為空,默認值,是否重復,是否為索引,通常,直接通過 pandas 的 pd.io.sql.to_sql() 一次性創建表格并保存資料時,列的默認屬性并不合需求,要么提前自己定義表的結構,設定好每列屬性;要么事后檢查列屬性,并逐列修改,所以,列的屬性設定、修改是高頻基礎知識點,
列的數值,即除了列名稱外的、該列其它值,修改某個值,也是高頻操作,不過我把這個知識點放到第四部分了,
對列的名稱、列的屬性進行修改,主要的關鍵詞都是 ALTER,具體又分為以下幾種情況,
情境A:新增一列,關鍵詞 ADD
在你所指定的 column_name 后面定義列的屬性,
ALTER TABLE table_name ADD COLUMN column_name char(20);
情境B:修改某列的名稱,關鍵詞 CHANGE
在修改列名的同時也可以重新指定列的屬性,
ALTER TABLE table_name CHANGE old_column_name new_column_name char(50);
情境C:修改某列的屬性,關鍵詞是 MODIFY
ALTER TABLE table_name MODIFY column_name char(100);
四、sql陳述句:資料的增改刪
通常提到資料庫操作時,四字以蔽之:增刪改查,
- 查詢,請看第二部分,關鍵詞是
SELECT, - 對資料所依賴的屬性的增、改,請看第三部分,關鍵詞是
ALTER, - 資料的增加,在第一部分的資料互動中也給出實體,就不重復了,關鍵詞是
INSERT, - 資料的修改,關鍵詞是
UPDATE, - 資料(甚至表格、庫)的洗掉,關鍵詞是
DELETE,
資料的修改,副關鍵詞是 set ,
UPDATE table_name SET columns_name = new_value 【條件】;
新數值如果是數值型別的,則直接寫數值即可;如果是文本型別的,必須要加上雙引號,比如,“your_new_value”,
如果把【條件】部分不寫,就相當于修改整列的值;想要修改特定范圍,就要用到條件運算式,這和前面的查詢部分是一致的,就不再重復,
資料的洗掉,對于新手來說,是必須警惕的操作,因為一旦誤操作,你將無力挽回,即便是職業程式員,也可能犯下無疑刪庫的慘劇,其基本陳述句為:
DELETE FROM table_name【條件】;
想要修改特定范圍,就要用到條件運算式,這和前面的查詢部分也是一致的,稍微啰嗦兩句:不要對自己設定的條件太自信,最好先用搜索陳述句檢查一下,然后再執行洗掉陳述句,
- 洗掉單行資料:添加能唯一標識該行資料的條件陳述句,
- 洗掉多行資料:添加能標識該范圍的條件陳述句,
- 洗掉整張表格:你是認真的嗎?沒有寫錯表格名字吧?! 做這項操作前,必須確認清楚自己的意圖,畢竟一旦發生,無可挽回,
如果條件留空,將保留表結構,而洗掉所有資料行,想要洗掉整張表格,什么都不留下,則執行:
DELETE TABLE table_name;
俗稱的“刪庫”就是刪掉整個資料庫,雖然實戰中幾乎不會用到,但作為新手經常手誤,在練習階段安全起見,最好還是專門創建一個 database 用于練手,練完直接刪掉整個練習庫:
DELETE DATABASE database_name;
如果簡單總結下過去一個月,使用mysql的體驗,那就是:除了mysql 的安裝激活太麻煩,資料的增刪改查比操作文本方便太多了!!完全值得容忍安裝激活的麻煩,另外 mysql 常用語法確實簡單、非常有規律,
希望我的總結帶給你幫助,鼓勵我繼續分享,那就請點個贊吧!勘誤請留言,或挪步我的github:https://github.com/liujuanjuan1984/ucanuupnobb/issues
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/125644.html
標籤:MySQL
上一篇:MySQL問題記錄——ERROR 1728 (HY000)
下一篇:MySQL學習——操作存盤程序