
隨著諸如Apache Flink,Apache Spark,Apache Storm之類的開源框架以及諸如Google Dataflow之類的云框架的增多,創建實時資料處理作業變得非常容易,這些API定義明確,并且諸如Map-Reduce之類的標準概念在所有框架中都遵循幾乎相似的語意,
但是,直到今天,實時資料處理領域的開發人員都在為該領域的某些特性而苦苦掙扎,因此,他們在不知不覺中創建了一條路徑,該路徑導致了應用程式中相當常見的錯誤,
讓我們看一下在設計實時應用程式時可能需要克服的一些陷阱,
活動時間
源生成資料的時間戳稱為“ 事件時間”,而應用程式處理資料的時間戳稱為“ 處理時間”,在實時資料流應用程式中,最常見的陷阱是無法區分這些時間戳,
讓我們詳細說明一下,
由于諸如代理中的GC較高或太多資料導致背壓之類的多個問題,資料佇列易出現延遲,我將事件表示為(E,P),其中E是事件時間戳(HH:MM:SS格式),P是處理時間戳,在理想世界中,E == P,但這在任何地方都不會發生,
假設我們收到以下資料
('05:00:00','05:00:02'),('05:00:01','05:00:03'),('05:00:01','05:00: 03'),('05:00:01','05:00:05'),
('05:00:02','05:00:05'),('05:00:02',' 05:00:05')
現在,我們假設有一個程式可以計算每秒接收到的事件數,根據事件時間,程式回傳
[05:00:00,05:00:01)= 1
[05:00:01,05:00:02)= 3
[05:00:02,05:00:03)= 2
但是,基于處理時間,輸出為
[5時○○分00秒,5點00分01秒)= 0
[5點00分01秒,5點00分02秒)= 0
[5點00分02秒,5時00分03秒)= 1
[05:00: 03,05:00:04)= 2
[05:00:04,05:00:05)= 0
[05:00:05,05:00:06)= 3
如您所見,這兩個都是完全不同的結果,
資料流中例外的延遲
大多數實時資料應用程式使用來自分布式佇列的資料,例如Apache Kafka,RabbitMQ,Pub / Sub等,佇列中的資料由其他服務生成,例如消費者應用程式的點擊流或資料庫的日志,
問題佇列容易受到延遲的影響,即使在幾十毫秒內,生成的事件也可能到達您的作業中,或者在最壞的情況下可能會花費一個多小時(極高的背壓),由于以下原因,資料可能會延遲:
- kafka上的高負載
- 生產者在其服務器中緩沖資料
- 由于應用程式中的背壓,消耗速度慢
假設資料將永遠不會延遲是一個巨大陷阱,開發人員應始終具有測量資料延遲的工具,例如,在Kafka,您應該檢查偏移量滯后,
您還應該監視作業中的背壓以及延遲(即事件時間與處理時間之間的差),沒有這些將導致資料意外丟失,例如10分鐘,時間視窗似乎沒有資料,并且視窗顯示10分鐘,之后,其期望值將是預期值的兩倍,
Joins
在批處理資料處理系統中,將兩個資料集合并起來比較簡單,在流處理世界中,情況變得有些麻煩,
//資料集的格式為(時間戳,鍵,值)
//資料組1 (05:00:
00,A,值A),
(05:00: 01,B,值B),(05:00: 04,C,值C),(05:00:04,D,值D)
//資料流2
(05:00:00,A,值A'),(05:00:02,B,值B' ),
(05:00:00,C,值C')
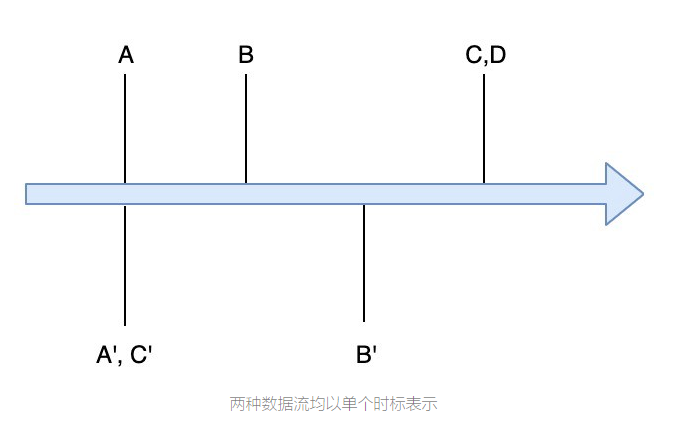
現在,我們將兩個資料流都放在它們的Key上,為簡單起見,我們將進行內部聯接,
Key A — 值A和值A'都同時到達,因此,我們可以輕松地將它們組合為一個函式并發出輸出
Key B — 值B比值B`早1秒,因此,我們需要在資料流1上等待至少1秒鐘,才能使連接正常作業,因此,您需要考慮以下內容-
- 那一秒鐘的資料將存盤在哪里?
- 如果1秒不是固定的延遲,并且在最壞的情況下不規則地增加到10分鐘怎么辦?
Key C —值C比值C'晚4秒鐘到達,這與以前相同,但是現在您在資料流1和2中都具有不規則的延遲,并且沒有固定的模式將其值設為1,
Key D —值D到達,但是沒有觀察到值D',考慮以下-
- 您要等多久才能獲得價值D`?
- 如果值D`可以從至少5秒到接近1小時的任何時間出現,該怎么辦?
- 如果這是一個外部聯接,而您必須決定何時單獨發出值D,該怎么辦?
- 如果在前一種情況下,在發出值D 1分鐘后到達值D`,該怎么辦?
以上所有問題的答案將取決于您的用例,重要的是要考慮所有這些問題,而不是忽略流系統的復雜性,
一定要注意 不要回避這些問題
配置
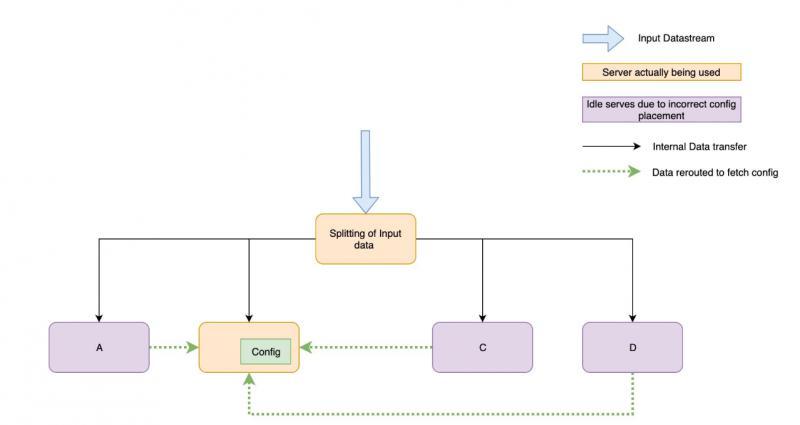
在標準微服務中,配置位于作業內部或資料庫中,您可以在資料流應用程式中執行相同的操作,但是,在繼續使用此方法之前,您需要考慮以下事項,
您將多久訪問一次配置?
如果需要為每個事件訪問配置,并且事件數量很多(超過一百萬RPM),那么您也可以嘗試其他方法,一種是將配置存盤在作業狀態中,這可以使用狀態處理在Flink和Spark中完成,可以使用檔案讀取器或Kafka中的其他流以狀態填充該配置,
在流處理世界中,針對每個事件進行資料庫呼叫可能會使您的應用程式變慢并導致背壓,選擇是使用快速資料庫,還是通過在應用程式內部存盤狀態來消除網路呼叫,
您的配置有多大?
如果配置很大,則僅當配置可以拆分到多個服務器時才應使用應用程式內狀態,例如,一個配置為每個用戶保留一些閾值,可以基于用戶ID密鑰將這樣的配置拆分到多臺計算機上,這有助于減少每臺服務器的存盤量,
如果無法在節點之間拆分配置,請首選資料庫,否則,所有資料將需要路由到包含配置的單個服務器,然后再次重新分發,唯一包含配置的服務器充當該方案的瓶頸,
設計實時資料流應用程式似乎很容易,但是開發人員會犯很多上述錯誤,特別是如果它們來自微服務領域,
重要的部分是了解資料流的基礎知識以及如何處理單個流,然后轉到處理多個聯接,實時配置更新等的復雜應用程式,
更多實時資料分析相關博文與科技資訊,歡迎關注 “實時流式計算”
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/12639.html
標籤:大數據