本篇博客是Redis系列的第4篇,主要講解下Redis的主從復制機制,
本系列的前3篇可以點擊以下鏈接查看:
Redis系列(一):Redis簡介及環境安裝
Redis系列(二):Redis的5種資料結構及其常用命令
Redis系列(三):Redis的持久化機制(RDB、AOF)
Redis的主從復制是面試中經常會被問的,我最近面試的幾家公司只要聊到Redis,都會問我主從復制的原理,
1. 為什么需要主從復制?
在本系列的上一篇博客中,我們講到了Redis的持久化機制,它很好的解決了單臺Redis服務器由于意外情況導致Redis服務器行程退出或者Redis服務器宕機而造成的資料丟失問題,
但持久化機制還原資料有個前提:你的Redis服務器得能正常啟動,
如果遇到極端的斷電情況(雖然概率小,但是有可能),Redis服務器啟都啟動不了,怎么還原資料?怎么保證它的高可用,
就算Redis服務器能啟動了,網路連接也有崩掉的可能,我不信你沒看到過電纜被挖斷導致的某些服務不可用的新聞,
正是由于有這樣的風險,所以生產環境Redis服務器不可能使用單臺的,那既然使用多臺Redis服務器,多臺Redis服務器之間的資料如何同步呢?
這就需要用到Redis的復制機制,
還有個原因就是,雖然Redis的性能很好,但單臺畢竟還是有瓶頸的,使用主從復制可以實作讀寫分離,提高Redis的高可用性,即主服務器用來執行寫命令,多個從服務器用來執行讀命令,類似于資料庫的讀寫分離,
綜上所述,主從復制主要有以下2個使用場景:
- 資料備份
- 讀寫分離
2. 主從復制實踐
首先,我在本機開啟2個Redis實體(也可以搞2臺Redis服務器),分別為127.0.0.1:6379、127.0.0.1:6380,
然后,使用redis-cli連接Redis實體127.0.0.1:6380并執行如下命令:
SLAVEOF 127.0.0.1 6379
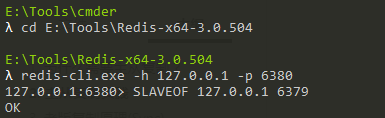
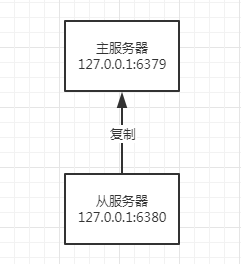
此時,我們稱127.0.0.1:6379為127.0.0.1:6380的主服務器(master),稱127.0.0.1:6380為127.0.0.1:6379的從服務器(slave),
2者之間的關系如下所示:
然后,我們在主服務器上執行如下寫命令:
SET msg "hello world"
此時,我們不僅能在主服務器上獲取到該值,也能在從服務器上獲取到該值:
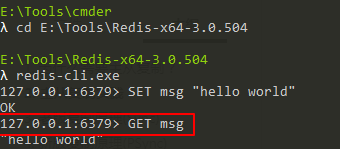
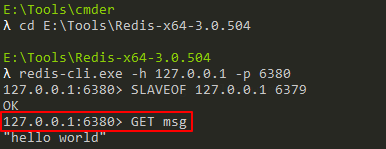
然后,我們在主服務器上執行如下洗掉命令:
DEL msg
此時,我們會發現不僅主服務器上的msg鍵被洗掉,從服務器上的msg也被洗掉:
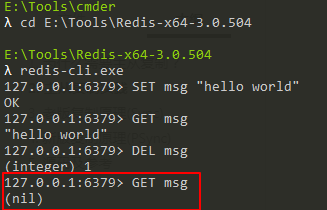
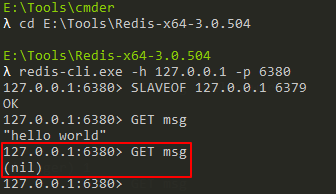
所以說,進行復制中的主從服務器雙方的資料庫將保存相同的資料,
值得注意的是,從服務器只能執行讀命令,執行寫命令時會報如下錯誤:

如果從服務器不想再復制主服務器,可以執行命令:SLAVEOF no one,
3. 舊版復制功能的實作(SYNC)
這里的舊版指的是Redis 2.8以前的版本,
Redis的復制功能分為以下2個操作:
- 同步:用于將從服務器的資料庫狀態更新至主服務器當前所處的資料庫狀態,
- 命令傳播:用于在主服務器的資料庫狀態被修改,導致主從服務器的資料庫狀態不一致時,讓主從服務器的資料庫狀態重新回到一致狀態,
3.1 同步
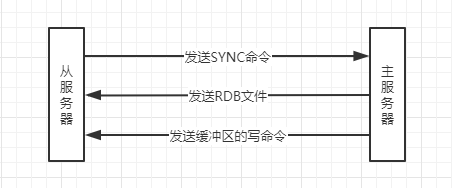
當客戶端向從服務器發送SLAVEOF命令,要求從服務器復制主服務器時,從服務器會向主服務器SYNC命令,該命令的執行步驟如下所示:
- 從服務器向主服務器發送
SYNC命令, - 主服務器收到
SYNC命令后,執行BGSAVE命令,在后臺生成RDB檔案,并使用一個緩沖區記錄從現在開始執行的所有寫命令, - 當主服務器的
BGSAVE命令執行完成,主服務器將生成的RDB檔案發送給從服務器,從服務器接收并載入這個RDB檔案,至此,從服務器的資料庫狀態和主服務器執行BGSAVE命令時的資料庫狀態一致, - 主服務器將記錄在緩沖區里面的所有寫命令發送給從服務器,從服務器接收并執行這些寫命令,至此,從服務器的資料庫狀態和主服務器當前的資料庫狀態一致,
SYNC命令執行期間,主從服務器的通信程序如下圖所示:
3.2 命令傳播
在同步操作執行完畢后,主從服務器的資料庫狀態達到一致狀態,當主服務器執行了客戶端發送的寫命令時,主服務器的資料庫就被修改了,導致主從服務器的資料庫狀態不再一致,
為了讓主從服務器的資料庫狀態再次回到一致狀態,主服務器需要對從服務器執行命令傳播操作:主服務器會將自己執行的寫命令,發送給從服務器執行,當從服務器執行了相同的寫命令后,主從服務器的資料庫狀態再次回到一致狀態,
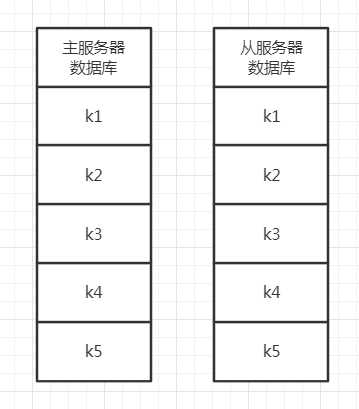
舉個具體的例子,比如主從服務器剛開始都擁有k1、k2、k3、k4、k5這5個鍵,然后客戶端往主服務器發送了命令DEL k3,此時主服務器會執行該條命令,并將該條命令傳播給從服務器執行,從而使主從服務器的資料庫狀態保持一致,
整個變化程序如下所示:
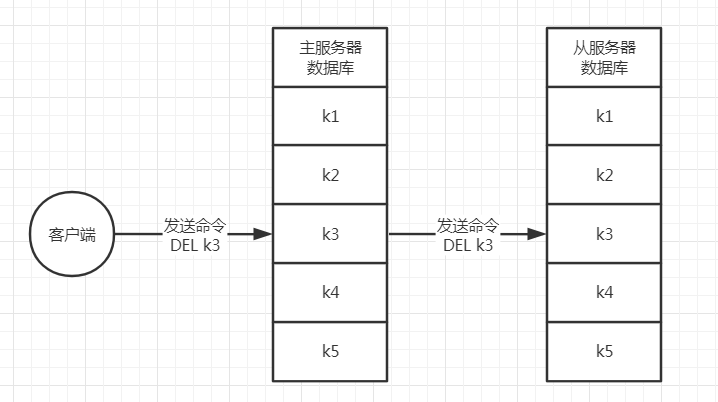
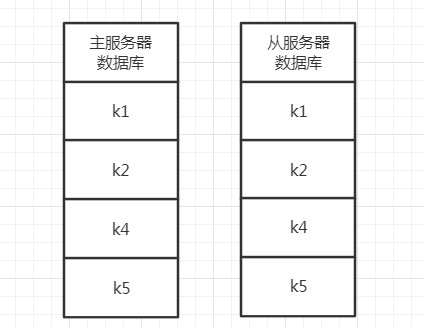
4. 舊版復制功能的缺陷
這里的舊版指的是Redis 2.8以前的版本,
在Redis 2.8以前,從服務器對主服務器的復制分為以下2種情況:
-
初次復制
從服務器以前沒有復制過任何主服務器,或者從服務器當前要復制的主服務器和上一次復制的主服務器不同,
-
斷線后重復制
處于命令傳播階段的主從服務器因為網路原因而中斷了復制,但從服務器通過重試又重新連上了主服務器,并繼續復制主服務器,
舊版復制功能可以很好的完成初次復制,但完成斷線后重復制的效率卻很低,
舉個具體的例子,從服務器B一直在復制著主服務器A,剛開始都是正常的,主服務器A執行的寫命令也都通過命令
傳播的方式傳遞給了從服務器B執行,但突然因為網路原因,主服務器A和從服務器B之間中斷了復制,在這期間,
假設主服務器又執行了10個寫命令,然后從服務器B通過重試又重新連上了主服務器A,繼續開始復制,那么它是
怎么復制的呢?
從服務器B會向主服務器A發送SYNC命令,主服務器A接收到命令后會執行BGSAVE命令,BGSAVE命令執行期間的
所有寫命令會被記錄到緩沖區,待BGSAVE命令執行完畢后,主服務器A會將生成的RDB檔案發送給從服務器B,
從服務器B接收并載入這個RDB檔案,然后主服務器A將緩沖區里的寫命令發送給從服務器B執行,至此,主從
服務器的資料庫狀態又恢復一致,后續又進入命令傳播階段,
也就是說,每次斷線后重復制,都要執行一次SYNC命令來一次全量復制,但其實從服務器B需要的只是斷開連接期間主服務器A執行的寫命令,按上面的例子,也就是只需要10個寫命令即可,
而SYNC命令又是一個非常耗費資源的操作:
- 主服務器需要執行
BGSAVE命令生成RDB檔案,這會耗費主服務器大量的CPU、記憶體和磁盤IO資源, - 主服務器需要將生成的RDB檔案發送給從服務器,這會耗費主從服務器大量的網路資源(帶寬和流量),
- 接收到RDB檔案的從服務器需要載入RDB檔案,在載入期間,從服務器會阻塞,沒辦法處理命令請求,
5. 新版復制功能的實作(PSYNC)
這里的新版指的是Redis 2.8以及之后的版本,
從Redis 2.8版本開始,Redis使用PSYNC命令代替SYNC命令來執行復制時的同步操作,
PSYNC命令有以下2種場景:
-
完整重同步
完整重同步用于處理初次復制,執行步驟和
SYNC命令的執行步驟基本一樣, -
部分重同步
部分重同步用于處理斷線后重復制,當從服務器在斷線后重新連接主服務器時,如果條件允許,主服務器可以將主從服務器連接斷開期間執行的寫命發送給從服務器,從服務器只要接收并執行這些寫命令,就可以將資料庫更新至主服務器當前所處的狀態,
仍然用上面舉的例子,新版復制,主服務器只需要把斷開期間執行的10個寫命令發送給從服務器即可,而不用生成并發送整個RDB檔案,性能大大提升,
主從服務器在執行部分重同步時的通信程序如下圖所示:
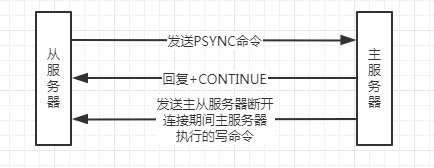
那么部分重同步是如何實作的呢?
部分重同步功能由以下3個部分組成:
- 主服務器和從服務器的復制偏移量
- 主服務器的復制積壓緩沖區
- 服務器的運行ID
接下來我們一一講解,
5.1 復制偏移量
執行復制的主服務器和從服務器會分別維護一個復制偏移量:
- 主服務器每次向從服務器傳播N個位元組的資料時,就將自己的復制偏移量的值加上N,
- 從服務器每次收到主服務器傳播來的N個位元組的資料時,就將自己的復制偏移量的值加上N,
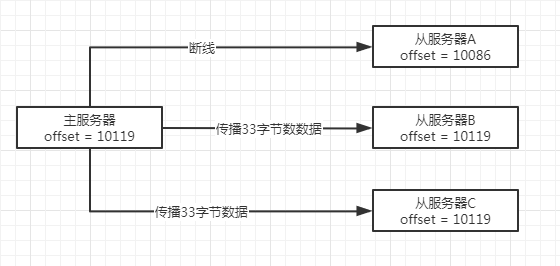
舉個例子,假設主服務器有3個從服務器,它們的復制偏移量都為10086,如下圖所示:
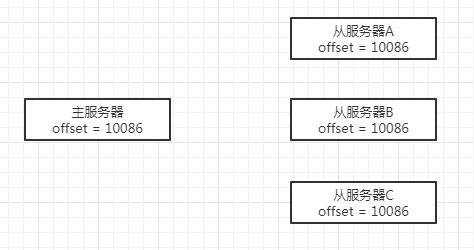
然后,主服務器向3個從服務器傳播了長度為33位元組的資料,那么主服務器的復制偏移量會加上33,變為10119,
從服務器A在這時剛好斷線了,沒有接收到資料,所以偏移量仍然為10086,
從服務器B和從服務器C正常接收到了資料,所以偏移量都更新為了10019,如下圖所示:
很顯然,通過對比主從服務器的復制偏移量,可以很容易地知道主從服務器是否處于一致狀態,
然后,從服務器A通過重試又重新連接到了主服務器,然后向主服務器發送PSYNC命令,并報告了自己當前的復制
偏移量為10086,主服務器此時需要處理2個問題:
- 該對從服務器A執行完整重同步還是部分重同步?
- 如果執行部分重同步,主服務器從哪里獲取到斷線期間從服務器A丟失的資料?
帶著這2個問題,我們看下復制積壓緩沖區,
5.2 復制積壓緩沖區
復制積壓緩沖區是主服務器維護的一個固定長度先進先出佇列,默認大小為1MB,
當主服務器進行命令傳播時,它不僅會將寫命令發送給所有從服務器,還會將寫命令入隊到復制積壓緩沖區,如下圖所示:

所以,主服務器的復制積壓緩沖區會保存著一部分最近傳播的寫命令,并且為佇列中的每個位元組記錄相應的復制偏移量,如下所示:
| 偏移量 | ... | 10087 | 10088 | 10089 | 10090 | 10091 | ... |
|---|---|---|---|---|---|---|---|
| 位元組值 | ... | '*' | 3 | '\r' | '\n' | '$' | ... |
當從服務器重新連接上主服務器時,會通過PSYNC命令將自己的復制偏移量offset發送給主服務器,主服務器會根據以下規則來決定對從服務器執行何種同步操作:
- 如果offset偏移量之后的資料仍然存在于復制積壓緩沖區,那么主服務器將對從服務器執行部分重同步操作,
- 如果offset偏移量之后的資料已經不存在于復制積壓緩沖區,那么主服務器將對從服務器執行完整重同步操作,
回到之前的例子:
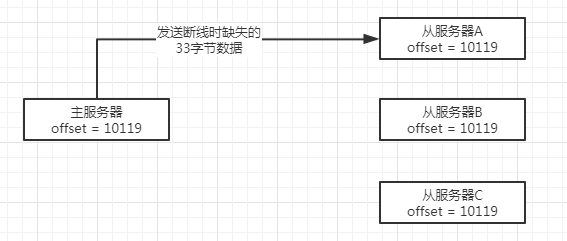
- 從服務器A重新連接上主服務器,向主服務器發送
PSYNC命令,報告自己的復制偏移量為10086, - 主服務器收到
PSYNC命令以及偏移量10086之后,會檢查偏移量10086之后的資料是否存在于復制積壓緩沖區,結果發現資料還在,于是主服務器向從服務器A發送+CONTINUE回復,表示資料同步將以部分重同步模式來進行, - 接著主服務器會將復制積壓緩沖區里10086偏移量之后的所有資料(偏移量為10087到10119)都發送給從服務器A,
- 從服務器A接收這33位元組的缺失資料,就回到與主服務器一致的狀態,
5.3 服務器運行ID
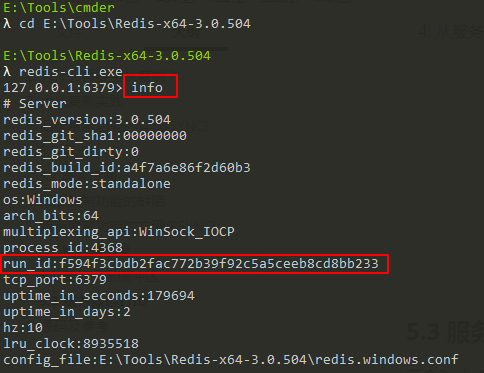
每個Redis服務器,不論主服務器還是從服務器,都會有自己的運行ID,運行ID在服務器啟動時自動生成,由40個十六進制字符組成,如下圖所示:
當從服務器對主服務器進行初次復制時,主服務器會將自己的運行ID傳送給從服務器,從服務器會將這個運行ID保存起來,
當從服務器斷線并重新連接上主服務器時,從服務器會把之前保存的運行ID發送給當前連接的主服務器:
- 如果從服務器之前保存的運行ID和當前連接的主服務器的運行ID相同,說明從服務器斷線前后復制的是同一臺主服務器,主服務器可以繼續嘗試執行部分重同步操作,
- 如果從服務器之前保存的運行ID和當前連接的主服務器的運行ID不相同,說明從服務器斷線前后復制的不是同一臺主服務器,主服務器將對從服務器執行完整重同步操作,
5.4 PSYNC命令執行細節
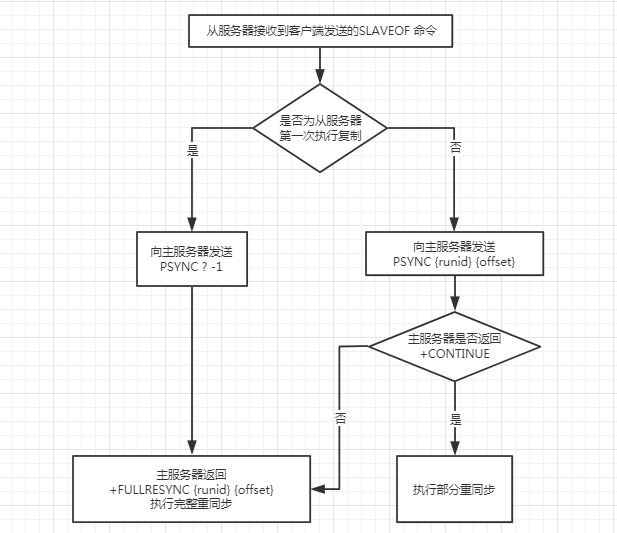
對于從服務器來說,呼叫PSYNC命令有以下2種情況:
-
如果從服務器以前沒有復制過任何主服務器,或者之前執行過
SLAVEOF on one命令,那么從服務器在開始一次新的復制時將向主服務器發送PSYNC ? -1命令,主動請求主服務器進行完整重同步, -
如果從服務器已經復制過某個主服務器,那么從服務器在開始一次新的復制時將向主服務器發送
PSYNC {runid} {offset}命令,其中runid是上一次復制的主服務器的運行ID,offset是從服務器當前的復制偏移量,
對于主服務器來說,接收到PSYNC命令后會向從服務器回傳以下3種回復中的一種:
- 如果主服務器回傳
+FULLRESYNC {runid} {offset},表示主服務器將與從服務器執行完整重同步操作,其中runid是主服務器的運行ID,從服務器會將這個ID保存起來,在下一次發送PSYNC命令時使用,offset是主服務器當前的復制偏移量,從服務器會將這個值作為自己的初始化偏移量, - 如果主服務器回傳
+CONTINUE,表示主服務器將與從服務器執行部分重同步操作,主服務器會將從服務器缺少的那部分資料發送給從服務器, 如果主服務器回傳-ERROR,表示主服務器的版本低于Redis 2.8,它識別不了PSYNC命令,從服務器將向主服務器發送SYNC命令,并與主服務器執行完整重同步操作,
以上描述流程可以使用以下流程圖來表示:
6. 原始碼及參考
黃健宏 《Redis設計與實作》
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/12774.html
標籤:NoSQL