深圳租房分析(2/2)資料分析
1、資料處理分析準備 1.1、匯入資料 1.2、處理重復值 1.3、資料型別轉換 2、房源數量,位置分布分析 2.1、各城區房源數量對比(橫柱狀圖) 2.2、各戶型數量分析(橫柱狀圖) 2.3、各個城區平均租金(柱狀圖和折線圖) 2.4、面積區間分析(餅狀圖) 2.5、朝向對于價格影響(柱狀圖和折線圖) 3、結語
資料來源鏈家租房網站,隨機爬蟲了5000多資料,洗掉了資訊相同的一部分資訊,余下的會從五個維度進行分析!
01各個城區房源數量對比(橫柱狀圖) 02各種戶型之間數量對比(橫柱狀圖)(洗掉了部分數量太少的戶型) 03各個城區租金對比(柱狀圖和折線統計圖) 04面積區間分布圖(餅狀圖) 05房屋朝向不同的房屋價格對比(柱狀圖和折線統計圖) # 導包
import pandas as pd
import matplotlib. pyplot as plt
import numpy as np
import seaborn as sns
處理中文字符無法正常顯示
from pylab import mpl
# 設定顯示中文字體
mpl. rcParams[ "font.sans-serif" ] = [ "SimHei" ]
# 設定正常顯示符號
mpl. rcParams[ "axes.unicode_minus" ] = False
1、資料處理分析準備
1.1、匯入資料
data = pd. read_csv( "./shenzhenlianjia.csv" , encoding= 'gbk' )
data
城區 小區 面積 房間格局 方向 價格 0 大鵬新區 承翰半山海 36㎡ 1室1廳1衛 東南 1500 1 大鵬新區 承翰半山海 36㎡ 1室1廳1衛 西北 1800 2 大鵬新區 承翰半山海 36㎡ 1室1廳1衛 南 1800 3 大鵬新區 承翰半山海 36㎡ 1室1廳1衛 東南 1800 4 大鵬新區 承翰半山海 36㎡ 1室1廳1衛 東南 1800 ... ... ... ... ... ... ... 4320 福田區 特區報社宿舍樓 14㎡ 5室1廳2衛 西 2390 4321 南山區 佳兆業前海廣場一期 88㎡ 4室2廳1衛 東南 9500 4322 福田區 錦林新居 17㎡ 3室1廳1衛 南 2560 4323 福田區 眾孚大廈 7㎡ 4室1廳2衛 東南 1790 4324 龍崗區 東方半島花園A區 13㎡ 4室1廳2衛 西北 1660
4325 rows × 6 columns
1.2、處理重復值
# 檢測重復資料,
data. duplicated( )
data. shape
(4325, 6)
data = data. drop_duplicates( )
data = data[ data[ '城區' ] != '城區' ]
data
城區 小區 面積 房間格局 方向 價格 0 大鵬新區 承翰半山海 36㎡ 1室1廳1衛 東南 1500 1 大鵬新區 承翰半山海 36㎡ 1室1廳1衛 西北 1800 2 大鵬新區 承翰半山海 36㎡ 1室1廳1衛 南 1800 3 大鵬新區 承翰半山海 36㎡ 1室1廳1衛 東南 1800 6 大鵬新區 承翰半山海 36㎡ 1室1廳1衛 南 2000 ... ... ... ... ... ... ... 4320 福田區 特區報社宿舍樓 14㎡ 5室1廳2衛 西 2390 4321 南山區 佳兆業前海廣場一期 88㎡ 4室2廳1衛 東南 9500 4322 福田區 錦林新居 17㎡ 3室1廳1衛 南 2560 4323 福田區 眾孚大廈 7㎡ 4室1廳2衛 東南 1790 4324 龍崗區 東方半島花園A區 13㎡ 4室1廳2衛 西北 1660
2762 rows × 6 columns
data. shape
(2762, 6)
1.3、資料型別轉換
# 把面積轉化為陣列int
data_area_new = np. array( [ ] )
data_area = data[ '面積' ] . values
data_area
data
城區 小區 面積 房間格局 方向 價格 0 大鵬新區 承翰半山海 36㎡ 1室1廳1衛 東南 1500 1 大鵬新區 承翰半山海 36㎡ 1室1廳1衛 西北 1800 2 大鵬新區 承翰半山海 36㎡ 1室1廳1衛 南 1800 3 大鵬新區 承翰半山海 36㎡ 1室1廳1衛 東南 1800 6 大鵬新區 承翰半山海 36㎡ 1室1廳1衛 南 2000 ... ... ... ... ... ... ... 4320 福田區 特區報社宿舍樓 14㎡ 5室1廳2衛 西 2390 4321 南山區 佳兆業前海廣場一期 88㎡ 4室2廳1衛 東南 9500 4322 福田區 錦林新居 17㎡ 3室1廳1衛 南 2560 4323 福田區 眾孚大廈 7㎡ 4室1廳2衛 東南 1790 4324 龍崗區 東方半島花園A區 13㎡ 4室1廳2衛 西北 1660
2762 rows × 6 columns
for i in data_area:
data_area_new = np. append( data_area_new, np. array( i[ : - 1 ] ) )
data_area_new = data_area_new. astype( np. float64)
data. loc[ : , '面積' ] = data_area_new
dataprice = data[ '價格' ] . astype( np. float64)
data. loc[ : , '價格' ] = dataprice
data
城區 小區 面積 房間格局 方向 價格 0 大鵬新區 承翰半山海 36.0 1室1廳1衛 東南 1500.0 1 大鵬新區 承翰半山海 36.0 1室1廳1衛 西北 1800.0 2 大鵬新區 承翰半山海 36.0 1室1廳1衛 南 1800.0 3 大鵬新區 承翰半山海 36.0 1室1廳1衛 東南 1800.0 6 大鵬新區 承翰半山海 36.0 1室1廳1衛 南 2000.0 ... ... ... ... ... ... ... 4320 福田區 特區報社宿舍樓 14.0 5室1廳2衛 西 2390.0 4321 南山區 佳兆業前海廣場一期 88.0 4室2廳1衛 東南 9500.0 4322 福田區 錦林新居 17.0 3室1廳1衛 南 2560.0 4323 福田區 眾孚大廈 7.0 4室1廳2衛 東南 1790.0 4324 龍崗區 東方半島花園A區 13.0 4室1廳2衛 西北 1660.0
2762 rows × 6 columns
2、房源數量,位置分布分析
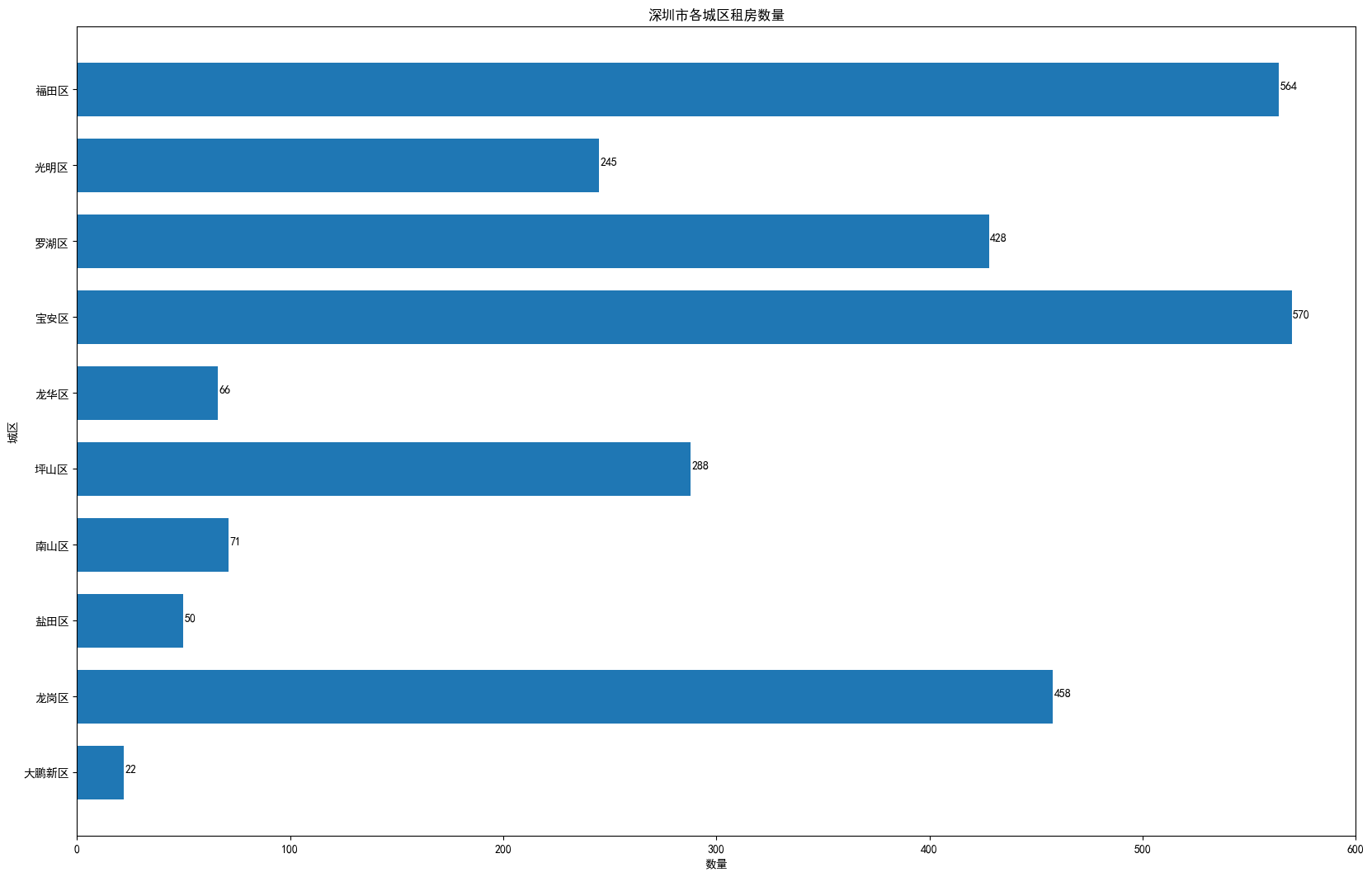
2.1、各城區房源數量對比(橫柱狀圖)
# 一共有10個城區
num = data[ '城區' ] . nunique( )
num
10
# 城區串列
area_df = pd. DataFrame( { '城區' : data[ '城區' ] . unique( ) , '數量' : [ 0 ] * num} )
area_df
城區 數量 0 大鵬新區 0 1 龍崗區 0 2 鹽田區 0 3 南山區 0 4 坪山區 0 5 龍華區 0 6 寶安區 0 7 羅湖區 0 8 光明區 0 9 福田區 0
grouparea = data. groupby( by= '城區' ) . count( )
grouparea
小區 面積 房間格局 方向 價格 城區 光明區 22 22 22 22 22 南山區 458 458 458 458 458 坪山區 50 50 50 50 50 大鵬新區 71 71 71 71 71 寶安區 288 288 288 288 288 鹽田區 66 66 66 66 66 福田區 570 570 570 570 570 羅湖區 428 428 428 428 428 龍華區 245 245 245 245 245 龍崗區 564 564 564 564 564
area_df[ '數量' ] = grouparea. values
area_df
城區 數量 0 大鵬新區 22 1 龍崗區 458 2 鹽田區 50 3 南山區 71 4 坪山區 288 5 龍華區 66 6 寶安區 570 7 羅湖區 428 8 光明區 245 9 福田區 564
area_df. sort_values( by= '數量' , ascending= False )
城區 數量 6 寶安區 570 9 福田區 564 1 龍崗區 458 7 羅湖區 428 4 坪山區 288 8 光明區 245 3 南山區 71 5 龍華區 66 2 鹽田區 50 0 大鵬新區 22
# 可視化展示
distance_type = area_df[ '城區' ]
num_type = area_df[ '數量' ]
plt. figure( figsize= ( 20 , 13 ) , dpi= 100 )
plt. barh( range ( 10 ) , num_type, height= 0.7 )
# 替換標簽
plt. yticks( range ( 10 ) , distance_type)
# x坐標延長
plt. xlim( 0 , 600 )
plt. xlabel( '數量' )
plt. ylabel( '城區' )
plt. title( '深圳市各城區租房數量' )
# 顯示數量
for x, y in enumerate ( num_type) :
plt. text( y+ 0.5 , x, '%s' % y)
plt. show( )
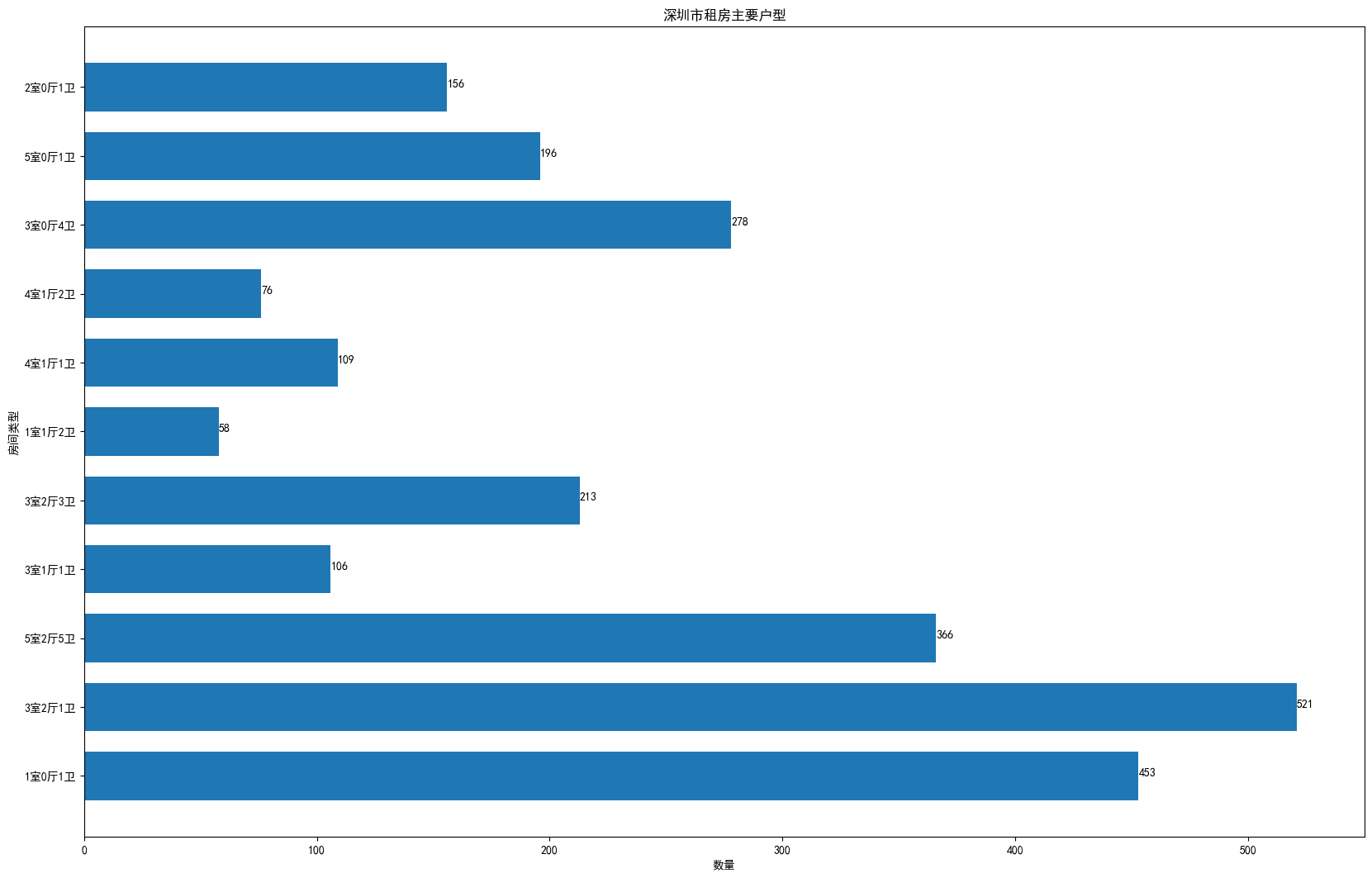
2.2、各戶型數量分析(橫柱狀圖)
這里的戶型太多了,有些戶型太少,所以進行了取舍,舍棄戶型數量小于的50的,只需要分析戶型大于50的!
num = data[ '房間格局' ] . nunique( )
num
52
room_df = pd. DataFrame( { '房間格局' : data[ '房間格局' ] . unique( ) , '數量' : [ 0 ] * num} )
room_df
房間格局 數量 0 1室1廳1衛 0 1 1室0廳1衛 0 2 2室2廳1衛 0 3 2室1廳1衛 0 4 3室2廳1衛 0 5 3室2廳2衛 0 6 4室2廳2衛 0 7 3室1廳3衛 0 8 3室1廳2衛 0 9 8室2廳5衛 0 10 5室2廳5衛 0 11 5室3廳5衛 0 12 3室1廳1衛 0 13 6室2廳4衛 0 14 6室2廳3衛 0 15 2室2廳2衛 0 16 3室2廳3衛 0 17 1室1廳2衛 0 18 4室2廳4衛 0 19 4室1廳1衛 0 20 4室1廳2衛 0 21 4室3廳4衛 0 22 5室1廳2衛 0 23 1室0廳0衛 0 24 3室0廳4衛 0 25 5室0廳1衛 0 26 5室1廳1衛 0 27 1室0廳2衛 0 28 5室0廳5衛 0 29 5室0廳4衛 0 30 1室1廳0衛 0 31 5室1廳3衛 0 32 2室1廳2衛 0 33 5室2廳4衛 0 34 1室2廳1衛 0 35 5室1廳4衛 0 36 5室0廳2衛 0 37 2室0廳1衛 0 38 4室0廳1衛 0 39 2室1廳0衛 0 40 4室1廳3衛 0 41 4室2廳1衛 0 42 5室1廳5衛 0 43 5室0廳3衛 0 44 未知室1廳1衛 0 45 未知室0廳0衛 0 46 5室2廳2衛 0 47 2室0廳2衛 0 48 6室1廳3衛 0 49 4室0廳4衛 0 50 2室2廳3衛 0 51 6室2廳2衛 0
grouproom = data. groupby( by= '房間格局' ) . count( )
grouproom
城區 小區 面積 方向 價格 房間格局 1室0廳0衛 21 21 21 21 21 1室0廳1衛 453 453 453 453 453 1室0廳2衛 1 1 1 1 1 1室1廳0衛 6 6 6 6 6 1室1廳1衛 521 521 521 521 521 1室1廳2衛 2 2 2 2 2 1室2廳1衛 5 5 5 5 5 2室0廳1衛 6 6 6 6 6 2室0廳2衛 1 1 1 1 1 2室1廳0衛 1 1 1 1 1 2室1廳1衛 366 366 366 366 366 2室1廳2衛 5 5 5 5 5 2室2廳1衛 106 106 106 106 106 2室2廳2衛 13 13 13 13 13 2室2廳3衛 1 1 1 1 1 3室0廳4衛 1 1 1 1 1 3室1廳1衛 213 213 213 213 213 3室1廳2衛 58 58 58 58 58 3室1廳3衛 3 3 3 3 3 3室2廳1衛 109 109 109 109 109 3室2廳2衛 76 76 76 76 76 3室2廳3衛 1 1 1 1 1 4室0廳1衛 6 6 6 6 6 4室0廳4衛 1 1 1 1 1 4室1廳1衛 278 278 278 278 278 4室1廳2衛 196 196 196 196 196 4室1廳3衛 3 3 3 3 3 4室2廳1衛 5 5 5 5 5 4室2廳2衛 31 31 31 31 31 4室2廳4衛 3 3 3 3 3 4室3廳4衛 1 1 1 1 1 5室0廳1衛 8 8 8 8 8 5室0廳2衛 2 2 2 2 2 5室0廳3衛 3 3 3 3 3 5室0廳4衛 4 4 4 4 4 5室0廳5衛 18 18 18 18 18 5室1廳1衛 47 47 47 47 47 5室1廳2衛 156 156 156 156 156 5室1廳3衛 13 13 13 13 13 5室1廳4衛 2 2 2 2 2 5室1廳5衛 3 3 3 3 3 5室2廳2衛 2 2 2 2 2 5室2廳4衛 1 1 1 1 1 5室2廳5衛 2 2 2 2 2 5室3廳5衛 1 1 1 1 1 6室1廳3衛 1 1 1 1 1 6室2廳2衛 1 1 1 1 1 6室2廳3衛 1 1 1 1 1 6室2廳4衛 1 1 1 1 1 8室2廳5衛 1 1 1 1 1 未知室0廳0衛 1 1 1 1 1 未知室1廳1衛 1 1 1 1 1
room_df[ '數量' ] = grouproom. values
room_df
房間格局 數量 0 1室1廳1衛 21 1 1室0廳1衛 453 2 2室2廳1衛 1 3 2室1廳1衛 6 4 3室2廳1衛 521 5 3室2廳2衛 2 6 4室2廳2衛 5 7 3室1廳3衛 6 8 3室1廳2衛 1 9 8室2廳5衛 1 10 5室2廳5衛 366 11 5室3廳5衛 5 12 3室1廳1衛 106 13 6室2廳4衛 13 14 6室2廳3衛 1 15 2室2廳2衛 1 16 3室2廳3衛 213 17 1室1廳2衛 58 18 4室2廳4衛 3 19 4室1廳1衛 109 20 4室1廳2衛 76 21 4室3廳4衛 1 22 5室1廳2衛 6 23 1室0廳0衛 1 24 3室0廳4衛 278 25 5室0廳1衛 196 26 5室1廳1衛 3 27 1室0廳2衛 5 28 5室0廳5衛 31 29 5室0廳4衛 3 30 1室1廳0衛 1 31 5室1廳3衛 8 32 2室1廳2衛 2 33 5室2廳4衛 3 34 1室2廳1衛 4 35 5室1廳4衛 18 36 5室0廳2衛 47 37 2室0廳1衛 156 38 4室0廳1衛 13 39 2室1廳0衛 2 40 4室1廳3衛 3 41 4室2廳1衛 2 42 5室1廳5衛 1 43 5室0廳3衛 2 44 未知室1廳1衛 1 45 未知室0廳0衛 1 46 5室2廳2衛 1 47 2室0廳2衛 1 48 6室1廳3衛 1 49 4室0廳4衛 1 50 2室2廳3衛 1 51 6室2廳2衛 1
room_df = room_df[ room_df[ '數量' ] > 50 ]
room_df
房間格局 數量 1 1室0廳1衛 453 4 3室2廳1衛 521 10 5室2廳5衛 366 12 3室1廳1衛 106 16 3室2廳3衛 213 17 1室1廳2衛 58 19 4室1廳1衛 109 20 4室1廳2衛 76 24 3室0廳4衛 278 25 5室0廳1衛 196 37 2室0廳1衛 156
num = room_df. shape[ 0 ]
num
11
house_type = room_df[ '房間格局' ]
num_type = room_df[ '數量' ]
# 繪圖
plt. figure( figsize= ( 20 , 13 ) , dpi= 100 )
plt. barh( range ( num) , num_type, height= 0.7 )
# 替換標簽
plt. yticks( range ( num) , house_type)
# 延長x軸
plt. xlim( 0 , 550 )
plt. xlabel( '數量' )
plt. ylabel( '房間型別' )
plt. title( '深圳市租房主要戶型' )
for x, y in enumerate ( num_type) :
plt. text( y, x, '%s' % y)
plt. show( )
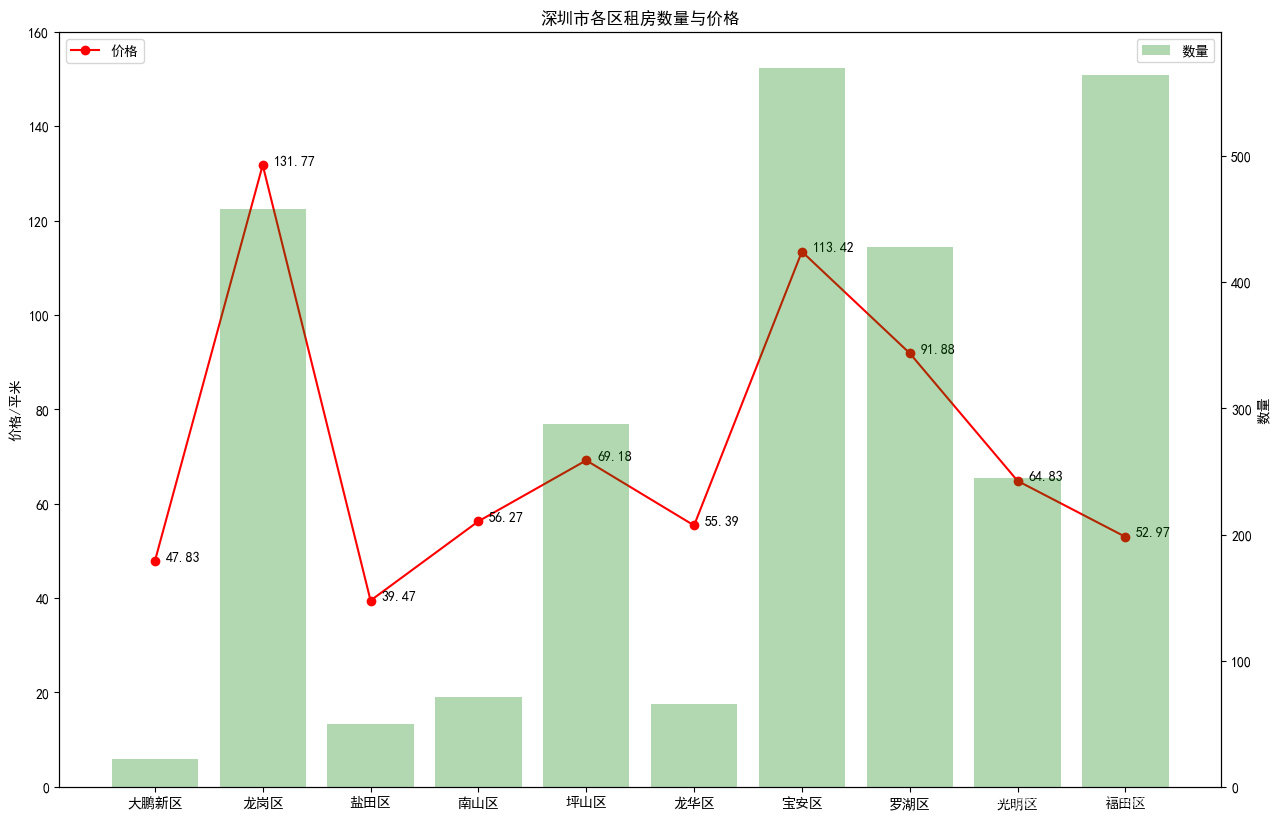
2.3、各個城區平均租金(柱狀圖和折線圖)
mean_df = pd. DataFrame(
{ '城區' : data[ '城區' ] . unique( ) , '房租總金額' : [ 0 ] * 10 , '總面積' : [ 0 ] * 10 } )
mean_df
城區 房租總金額 總面積 0 大鵬新區 0 0 1 龍崗區 0 0 2 鹽田區 0 0 3 南山區 0 0 4 坪山區 0 0 5 龍華區 0 0 6 寶安區 0 0 7 羅湖區 0 0 8 光明區 0 0 9 福田區 0 0
# 總價格
sum_price = data[ '價格' ] . groupby( data[ '城區' ] ) . sum ( )
sum_price
城區
光明區 87100.0
南山區 1786082.0
坪山區 135056.0
大鵬新區 318690.0
寶安區 992655.0
鹽田區 222521.0
福田區 1812617.0
羅湖區 1320652.0
龍華區 731725.0
龍崗區 1510020.0
Name: 價格, dtype: float64
# 總面積
sum_area = data[ '面積' ] . groupby( data[ '城區' ] ) . sum ( )
sum_area
城區
光明區 1821.0
南山區 13555.0
坪山區 3422.0
大鵬新區 5664.0
寶安區 14348.0
鹽田區 4017.0
福田區 15982.0
羅湖區 14374.0
龍華區 11286.0
龍崗區 28506.0
Name: 面積, dtype: float64
mean_df[ '總面積' ] = sum_area. values
mean_df[ '房租總金額' ] = sum_price. values
mean_df
城區 房租總金額 總面積 0 大鵬新區 87100.0 1821.0 1 龍崗區 1786082.0 13555.0 2 鹽田區 135056.0 3422.0 3 南山區 318690.0 5664.0 4 坪山區 992655.0 14348.0 5 龍華區 222521.0 4017.0 6 寶安區 1812617.0 15982.0 7 羅湖區 1320652.0 14374.0 8 光明區 731725.0 11286.0 9 福田區 1510020.0 28506.0
mean_df[ '每平米租金(元)' ] = round ( mean_df[ '房租總金額' ] / mean_df[ '總面積' ] , 2 )
mean_df
城區 房租總金額 總面積 每平米租金(元) 0 大鵬新區 87100.0 1821.0 47.83 1 龍崗區 1786082.0 13555.0 131.77 2 鹽田區 135056.0 3422.0 39.47 3 南山區 318690.0 5664.0 56.27 4 坪山區 992655.0 14348.0 69.18 5 龍華區 222521.0 4017.0 55.39 6 寶安區 1812617.0 15982.0 113.42 7 羅湖區 1320652.0 14374.0 91.88 8 光明區 731725.0 11286.0 64.83 9 福田區 1510020.0 28506.0 52.97
# 合并城區數量表
df_merge = pd. merge( area_df, mean_df)
df_merge
城區 數量 房租總金額 總面積 每平米租金(元) 0 大鵬新區 22 87100.0 1821.0 47.83 1 龍崗區 458 1786082.0 13555.0 131.77 2 鹽田區 50 135056.0 3422.0 39.47 3 南山區 71 318690.0 5664.0 56.27 4 坪山區 288 992655.0 14348.0 69.18 5 龍華區 66 222521.0 4017.0 55.39 6 寶安區 570 1812617.0 15982.0 113.42 7 羅湖區 428 1320652.0 14374.0 91.88 8 光明區 245 731725.0 11286.0 64.83 9 福田區 564 1510020.0 28506.0 52.97
# 可視化
num = df_merge[ '數量' ]
price = df_merge[ '每平米租金(元)' ]
l = [ i for i in range ( 10 ) ]
lx = df_merge[ '城區' ]
fig = plt. figure( figsize= ( 15 , 10 ) , dpi= 100 )
# 顯示折線圖
ax1 = fig. add_subplot( 111 )
ax1. plot( l, price, 'or-' , label= '價格' )
for i, ( _x, _y) in enumerate ( zip ( l, price) ) :
plt. text( _x+ 0.1 , _y, price[ i] )
ax1. set_ylim( [ 0 , 160 ] )
ax1. set_ylabel( '價格/平米' )
plt. legend( loc= 'upper left' )
# 繪制條形圖
ax2 = ax1. twinx( )
plt. bar( l, num, alpha= 0.3 , color= 'green' , label= '數量' )
ax2. set_ylabel( '數量' )
plt. legend( loc= 'upper right' )
plt. xticks( l, lx)
# for x,y in enumerate(num):
# plt.text(y,x,'%2f'%y)
plt. title( '深圳市各區租房數量與價格' )
plt. show( )
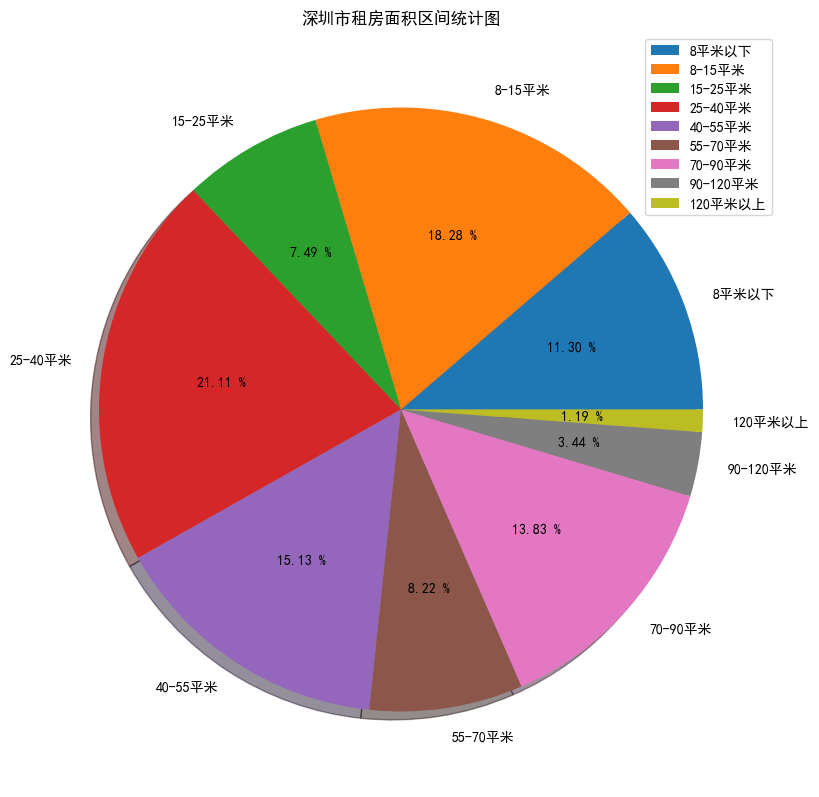
2.4、面積區間分析(餅狀圖)
# 查看房屋最貴,最便宜
print ( '房屋最貴是{}元每月' . format ( data[ '價格' ] . max ( ) ) )
print ( '房屋最便宜是{}元每月' . format ( data[ '價格' ] . min ( ) ) )
房屋最貴是180000.0元每月
房屋最便宜是950.0元每月
# 查看房屋的最大面積和最小面積
print ( '房屋最大面積是{}平方米' . format ( data[ '面積' ] . max ( ) ) )
print ( '房屋最小面積是{}平方米' . format ( data[ '面積' ] . min ( ) ) )
房屋最大面積是830.0平方米
房屋最小面積是5.0平方米
# 面積區間劃分
area_divide = [ 0 , 8 , 15 , 25 , 40 , 55 , 70 , 90 , 120 , 850 ]
area_cut = pd. cut( list ( data[ '面積' ] ) , area_divide)
area_cut_data = area_cut. describe( )
area_cut_data
counts freqs categories (0, 8] 312 0.112962 (8, 15] 505 0.182839 (15, 25] 207 0.074946 (25, 40] 583 0.211079 (40, 55] 418 0.151340 (55, 70] 227 0.082187 (70, 90] 382 0.138306 (90, 120] 95 0.034395 (120, 850] 33 0.011948
# 資料可視化,使用餅狀圖
area_percentage = ( area_cut_data[ 'freqs' ] . values) * 100
area_percentage
array([11.2961622 , 18.28385228, 7.49456915, 21.10789283, 15.1339609 ,
8.21868211, 13.83055757, 3.43953657, 1.19478639])
labels = [ '8平米以下' , '8-15平米' , '15-25平米' , '25-40平米' , '40-55平米' , '55-70平米' , '70-90平米' ,
'90-120平米' , '120平米以上' ]
plt. figure( figsize= ( 20 , 10 ) , dpi= 100 )
# 顯示的是圓形,如果不加,是橢圓形
plt. axes( aspect= 1 )
plt. pie( x= area_percentage, labels= labels, autopct= '%.2f %%' , shadow= True )
plt. legend( loc= 'best' )
plt. title( '深圳市租房面積區間統計圖' )
plt. show
<function matplotlib.pyplot.show(*args, **kw)>
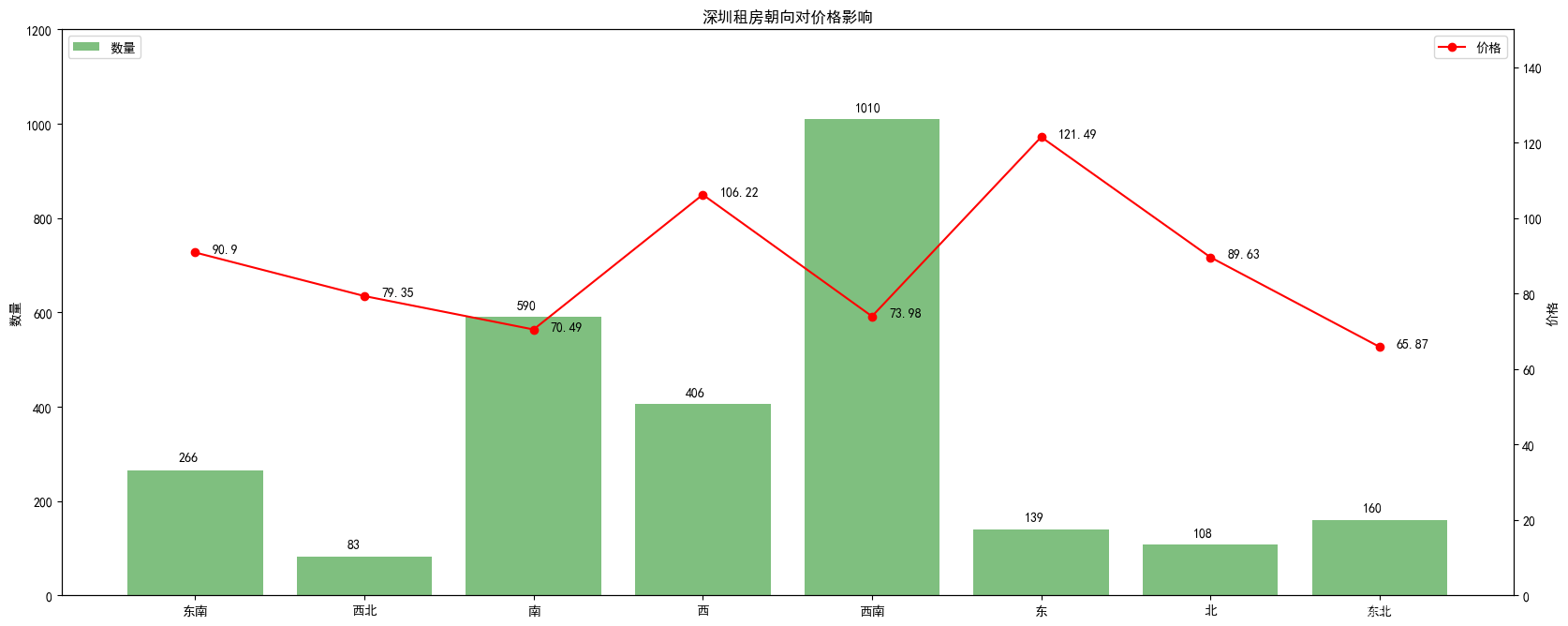
2.5、朝向對于價格影響(柱狀圖和折線圖)
face_df_value = data[ '方向' ] . unique( )
face_df_value
array(['東南', '西北', '南', '西', '西南', '東', '北', '東北'], dtype=object)
face_df = pd. DataFrame( { '方向' : data[ '方向' ] . unique( ) , '數量' : [
0 ] * face_df_value. shape[ 0 ] , '總價格' : [ 0 ] * face_df_value. shape[ 0 ] , '總面積' : [ 0 ] * face_df_value. shape[ 0 ] } )
face_df
方向 數量 總價格 總面積 0 東南 0 0 0 1 西北 0 0 0 2 南 0 0 0 3 西 0 0 0 4 西南 0 0 0 5 東 0 0 0 6 北 0 0 0 7 東北 0 0 0
num_sum = data. groupby( by= data[ '方向' ] ) . count( )
num_sum
城區 小區 面積 房間格局 價格 方向 東 266 266 266 266 266 東北 83 83 83 83 83 東南 590 590 590 590 590 北 406 406 406 406 406 南 1010 1010 1010 1010 1010 西 139 139 139 139 139 西北 108 108 108 108 108 西南 160 160 160 160 160
# 總價格
price_sum = data[ '價格' ] . groupby( by= data[ '方向' ] ) . sum ( )
price_sum
方向
東 846353.0
東北 259858.0
東南 2281168.0
北 1149286.0
南 3158155.0
西 388531.0
西北 332181.0
西南 501586.0
Name: 價格, dtype: float64
# 總面積
area_sum = data[ '面積' ] . groupby( by= data[ '方向' ] ) . sum ( )
area_sum
方向
東 9311.0
東北 3275.0
東南 32360.0
北 10820.0
南 42690.0
西 3198.0
西北 3706.0
西南 7615.0
Name: 面積, dtype: float64
# 賦值寫入
face_df[ '數量' ] = num_sum. values
face_df[ '總價格' ] = price_sum. values
face_df[ '總面積' ] = area_sum. values
face_df
方向 數量 總價格 總面積 0 東南 266 846353.0 9311.0 1 西北 83 259858.0 3275.0 2 南 590 2281168.0 32360.0 3 西 406 1149286.0 10820.0 4 西南 1010 3158155.0 42690.0 5 東 139 388531.0 3198.0 6 北 108 332181.0 3706.0 7 東北 160 501586.0 7615.0
# 平均價格
face_df[ '平均價格' ] = round ( face_df[ '總價格' ] / face_df[ '總面積' ] , 2 )
face_df
方向 數量 總價格 總面積 平均價格 0 東南 266 846353.0 9311.0 90.90 1 西北 83 259858.0 3275.0 79.35 2 南 590 2281168.0 32360.0 70.49 3 西 406 1149286.0 10820.0 106.22 4 西南 1010 3158155.0 42690.0 73.98 5 東 139 388531.0 3198.0 121.49 6 北 108 332181.0 3706.0 89.63 7 東北 160 501586.0 7615.0 65.87
# 準備資料
l = [ i for i in range ( 8 ) ]
_num = face_df[ '數量' ]
# _sumprice = face_df['總價格']
# _sumarea = face_df['總面積']
_meanprice = face_df[ '平均價格' ]
fig = plt. figure( figsize= ( 20 , 8 ) , dpi= 100 )
# 繪制數量柱狀圖
ax3 = fig. add_subplot( 111 )
ax3. bar( l, _num, label= '數量' , alpha= 0.5 , color= 'green' )
ax3. set_ylabel( '數量' )
ax3. set_ylim( 0 , 1200 )
plt. legend( loc= 'upper left' )
for x, y in enumerate ( _num) :
plt. text( x- 0.1 , y+ 18 , '%s' % y)
# 替換x標簽
plt. xticks( l, face_df[ '方向' ] )
# 繪制折線圖
ax4 = ax3. twinx( )
plt. plot( l, _meanprice, 'or-' , label= '價格' )
ax4. legend( loc= 'upper right' )
ax4. set_ylim( 0 , 150 )
ax4. set_ylabel( '價格' )
for i, ( _x, _y) in enumerate ( zip ( l, _meanprice) ) :
plt. text( _x+ 0.1 , _y- 0.1 , _meanprice[ i] )
plt. title( '深圳租房朝向對價格影響' )
plt. show( )
3、結語
主要來深圳一段時間,租房的問題是一個大問題,就自己爬取了一些資訊,然后就進行了一部分分析,采取的樣本并不是特別多,以上只是個人的資料分析與其他無關!