ubuntu系統下配置caffe的GPU環境,訓練mobileNet-SSD并在EAIDK-310嵌入式上推理
- 前言
- 一、NVIDIA顯卡驅動及KUDA的安裝
- 1.安裝gpu驅動
- 2.安裝cuda和cudnn
- 二、ubuntu安裝GPU版caffe
- (一) 安裝依賴庫:
- (二) 下載原始碼并切換到 ssd 分支
- (三) 修改組態檔
- 1.修改Makefile.config檔案
- 2.修改Makefile檔案
- (四) 編譯及測驗caffe
- 三、anaconda3環境下安裝gpu版caffe
- (一) ubuntu系統安裝anaconda3
- 1.下載及安裝
- 2.創建虛擬環境
- (二) 虛擬環境下安裝caffe
- 四、caffe環境下訓練MobileNet—SSD
前言
如果沒有安裝好ubuntu系統或者系統崩潰需要重裝的可以參考上一篇博客:ubuntu+win10雙系統安裝,
一、NVIDIA顯卡驅動及KUDA的安裝
1.安裝gpu驅動
這里推薦一個簡單的安裝方法,打開選單,找到軟體和更新,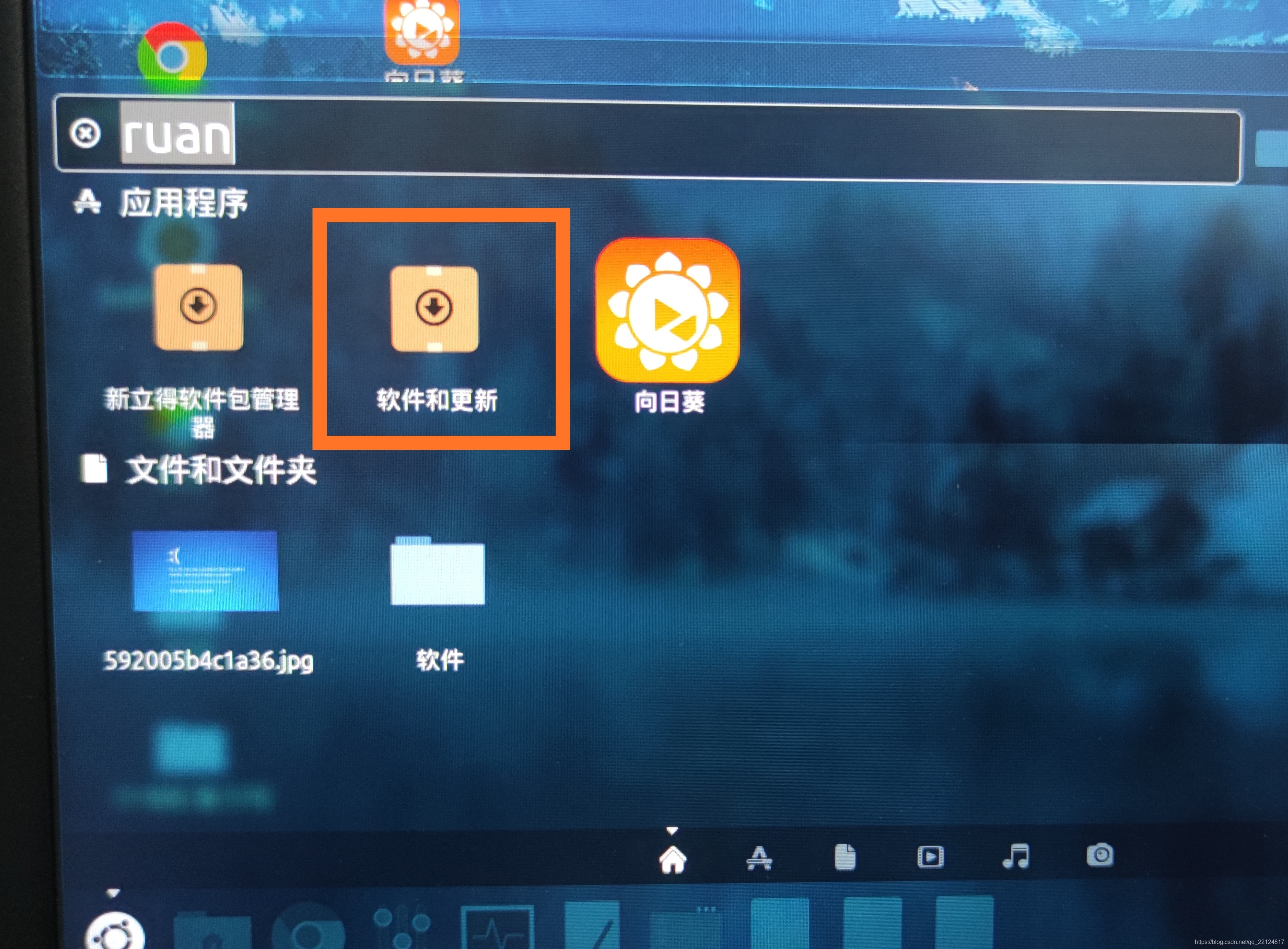
找到附加驅動,這里會自動推薦適合GPU的驅動,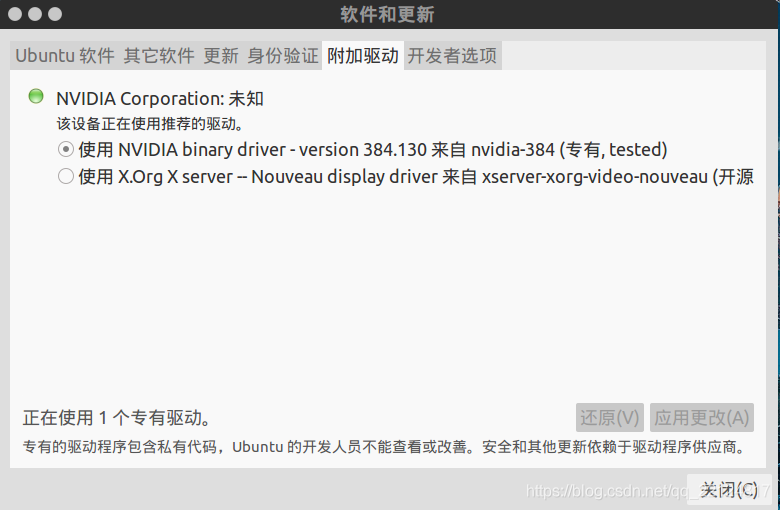
選擇使用NVIDIA驅動,點擊右下角的應用更改,系統會自動安裝顯卡驅動并重啟,
若此方法失敗,則可參考網上安裝gpu驅動的教程,教程有很多,這里不再贅述,
驗證是否成功安裝:nvidia-smi
nvidia-smi
顯示如下圖則說明安裝成功,注意版本,我這里是Driver Version: 384.130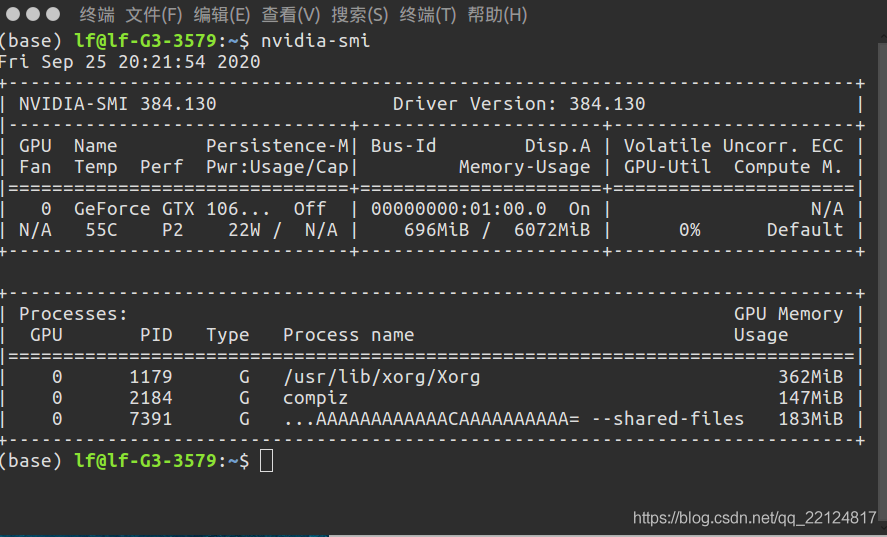
2.安裝cuda和cudnn
版本問題
cada: cuda_8.0.44_linux.run
cudnn:cudnn-8.0-linux-x64-v5.1.tgz
- 如沒有使用此版本以及上面的顯卡驅動版本,不保證能配置成功,本人經過長達兩周的時間摸索此對應的版本,推薦CUDA官網,cudnn的安裝下載,若有需要,可參考百度云,
- 至于安裝教程,網上很多,這里推薦一篇教程,
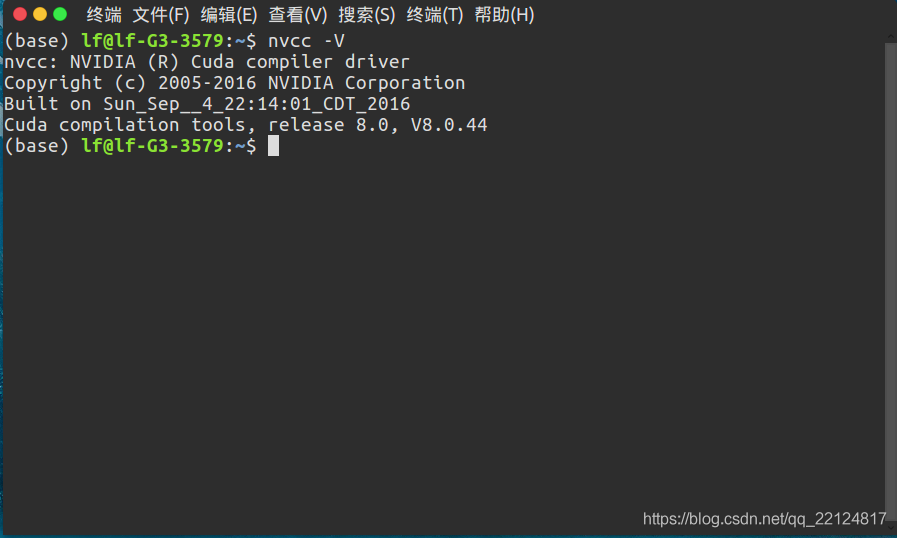
- 查看是否安裝成功:nvcc -V
二、ubuntu安裝GPU版caffe
(一) 安裝依賴庫:
1.安裝指令如下:
sudo apt-get install libprotobuf-dev //(16.04默認版本2.6.1,不能升級)
sudo apt-get install libleveldb-dev
sudo apt-get install libsnappy-dev
sudo apt-get install libopencv-dev
sudo apt-get install libhdf5-serial-dev
sudo apt-get install protobuf-compiler
sudo apt-get install --no-install-recommends libboost-all-dev
sudo apt-get install libatlas-base-dev
sudo apt-get install python-dev
sudo apt-get install libgflags-dev
sudo apt-get install libgoogle-glog-dev
sudo apt-get install liblmdb-dev
2.特別注意
本人安裝時python版本是Ubuntu16.04自帶的Python2.7,如果需要其他python版本,建議參考后面第三節anaconda虛擬環境下的安裝,
安裝完成后確認python版本,直接輸入python:
python
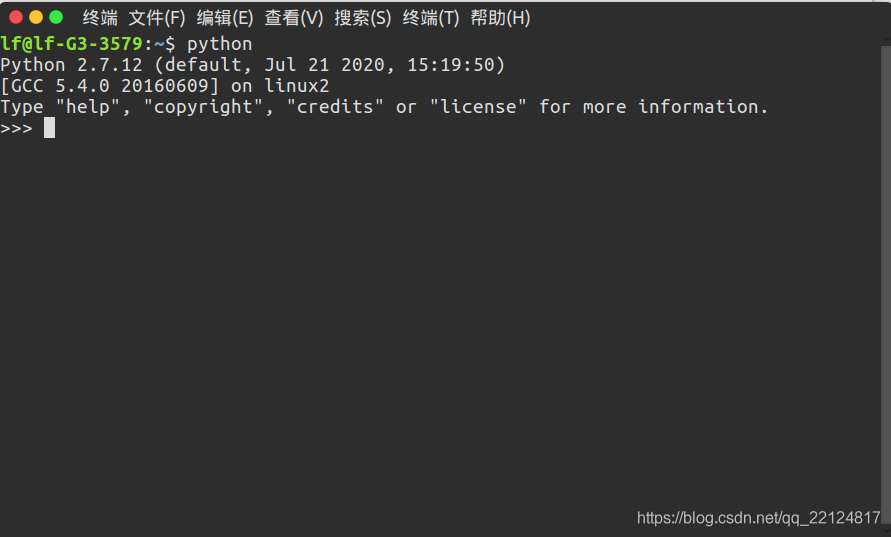
這里我只有用opencv2.4.9.1才編譯成功,及Ubuntu16.04默認安裝的版本,
安裝完成后確認opencv版本,接著輸入:
import cv2
cv2.__version__
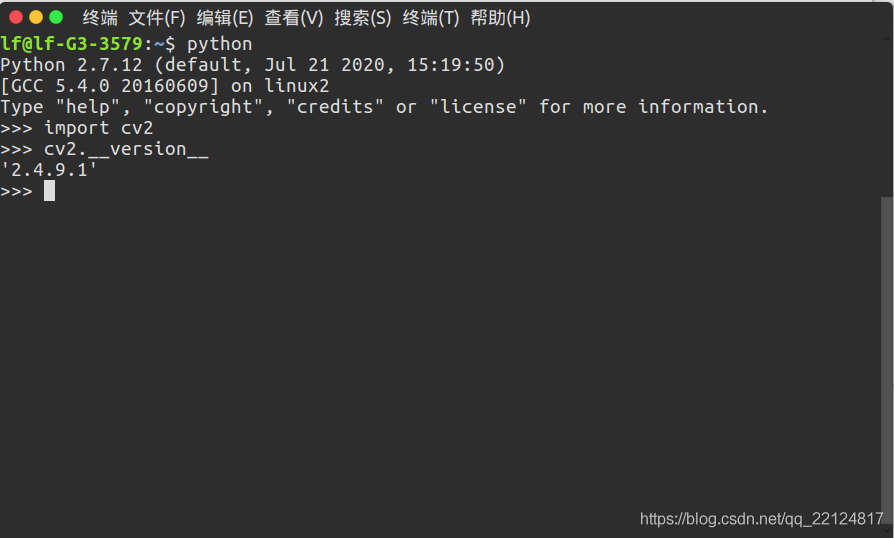
(二) 下載原始碼并切換到 ssd 分支
1.下載碼源
在主目錄下(我的是/home/xxx,xxx為用戶名)打開命令視窗,依次輸入:
下載github上的caffe專案:
git clone https://github.com/weiliu89/caffe.git
若后面編譯不成功,也可以下載這里編譯好的caffe,
切換到caffe檔案夾:
cd caffe
2.切換到 ssd 分支
git checkout ssd
3.安裝python依賴庫
切換到 caffe 下的 python 目錄下,下載 python 依賴庫(先安裝 pip)
cd python
sudo apt-get install python-pip
for req in $(catpython requirements.txt); do pip install $req; done
(三) 修改組態檔
(針對python2.7,opencv2.4.9.1d的環境修改)
1.修改Makefile.config檔案
先將Makefile.config.example復制并重命名為Makefile.config
復制指令如下:
cp Makefile.config.example Makefile.config
然后修改Makefile.config檔案,修改后如下:
## Refer to http://caffe.berkeleyvision.org/installation.html
# Contributions simplifying and improving our build system are welcome!
# cuDNN acceleration switch (uncomment to build with cuDNN).
USE_CUDNN := 1
# CPU-only switch (uncomment to build without GPU support).
# CPU_ONLY := 1
# uncomment to disable IO dependencies and corresponding data layers
# USE_OPENCV := 0
# USE_LEVELDB := 0
# USE_LMDB := 0
# uncomment to allow MDB_NOLOCK when reading LMDB files (only if necessary)
# You should not set this flag if you will be reading LMDBs with any
# possibility of simultaneous read and write
# ALLOW_LMDB_NOLOCK := 1
# Uncomment if you're using OpenCV 3
# OPENCV_VERSION := 3
# To customize your choice of compiler, uncomment and set the following.
# N.B. the default for Linux is g++ and the default for OSX is clang++
# CUSTOM_CXX := g++
# CUDA directory contains bin/ and lib/ directories that we need.
CUDA_DIR := /usr/local/cuda
# On Ubuntu 14.04, if cuda tools are installed via
# "sudo apt-get install nvidia-cuda-toolkit" then use this instead:
# CUDA_DIR := /usr
# CUDA architecture setting: going with all of them.
# For CUDA < 6.0, comment the lines after *_35 for compatibility.
CUDA_ARCH := -gencode arch=compute_30,code=sm_30 \
-gencode arch=compute_35,code=sm_35 \
-gencode arch=compute_50,code=sm_50 \
-gencode arch=compute_52,code=sm_52 \
-gencode arch=compute_61,code=sm_61
# BLAS choice:
# atlas for ATLAS (default)
# mkl for MKL
# open for OpenBlas
# BLAS := atlas
BLAS := open
# Custom (MKL/ATLAS/OpenBLAS) include and lib directories.
# Leave commented to accept the defaults for your choice of BLAS
# (which should work)!
# BLAS_INCLUDE := /path/to/your/blas
# BLAS_LIB := /path/to/your/blas
# Homebrew puts openblas in a directory that is not on the standard search path
# BLAS_INCLUDE := $(shell brew --prefix openblas)/include
# BLAS_LIB := $(shell brew --prefix openblas)/lib
# This is required only if you will compile the matlab interface.
# MATLAB directory should contain the mex binary in /bin.
# MATLAB_DIR := /usr/local
# MATLAB_DIR := /Applications/MATLAB_R2012b.app
# NOTE: this is required only if you will compile the python interface.
# We need to be able to find Python.h and numpy/arrayobject.h.
PYTHON_INCLUDE := /usr/include/python2.7 \
/usr/local/lib/python2.7/dist-packages/numpy/core/include
# Anaconda Python distribution is quite popular. Include path:
# Verify anaconda location, sometimes it's in root.
# ANACONDA_HOME := $(HOME)/anaconda2
# PYTHON_INCLUDE := $(ANACONDA_HOME)/include \
$(ANACONDA_HOME)/include/python2.7 \
$(ANACONDA_HOME)/lib/python2.7/site-packages/numpy/core/include \
# Uncomment to use Python 3 (default is Python 2)
# PYTHON_LIBRARIES := boost_python3 python3.5m
# PYTHON_INCLUDE := /usr/include/python3.5m \
# /usr/lib/python3.5/dist-packages/numpy/core/include
# We need to be able to find libpythonX.X.so or .dylib.
PYTHON_LIB := /usr/lib
# PYTHON_LIB := $(ANACONDA_HOME)/lib
# Homebrew installs numpy in a non standard path (keg only)
# PYTHON_INCLUDE += $(dir $(shell python -c 'import numpy.core; print(numpy.core.__file__)'))/include
# PYTHON_LIB += $(shell brew --prefix numpy)/lib
# Uncomment to support layers written in Python (will link against Python libs)
# WITH_PYTHON_LAYER := 1
# Whatever else you find you need goes here.
INCLUDE_DIRS := $(PYTHON_INCLUDE) /usr/local/include \
/usr/include/hdf5/serial
LIBRARY_DIRS := $(PYTHON_LIB) /usr/local/lib /usr/lib \
/usr/lib/x86_64-linux-gnu/hdf5/serial
# If Homebrew is installed at a non standard location (for example your home directory) and you use it for general dependencies
# INCLUDE_DIRS += $(shell brew --prefix)/include
# LIBRARY_DIRS += $(shell brew --prefix)/lib
# Uncomment to use `pkg-config` to specify OpenCV library paths.
# (Usually not necessary -- OpenCV libraries are normally installed in one of the above $LIBRARY_DIRS.)
# USE_PKG_CONFIG := 1
# N.B. both build and distribute dirs are cleared on `make clean`
BUILD_DIR := build
DISTRIBUTE_DIR := distribute
# Uncomment for debugging. Does not work on OSX due to https://github.com/BVLC/caffe/issues/171
# DEBUG := 1
# The ID of the GPU that 'make runtest' will use to run unit tests.
TEST_GPUID := 0
# enable pretty build (comment to see full commands)
Q ?= @
2.修改Makefile檔案
(這里代碼有點多,避免一行行的去查找修改,這里直接給出修改好的Makefile檔案,)
(四) 編譯及測驗caffe
- 在caffe目錄下編譯:
make pycaffe -j8
make all -j8
make test -j8
make runtest -j8
時間較長,請耐心等待,-j8是指多核同時編譯,可節省時間,根據自己電腦設定-j**,出現pass則編譯成功,
- 測驗:
添加環境變數,注意caffe的路徑:
cd caffe/python
export PYTHONPATH=~/caffe/python:$PYTHONPATH
進入 python 環境,輸入:import caffe 如果沒有報錯,證明安裝成功,若編譯通過但是匯入失敗,則make pycaffe一下,
- 匯入環境變數:
sudo echo export PYTHONPATH=“~/caffe/python" >>~/.bashrc
source ~/.bashrc #使環境變數生效
或者:
echo "export CAFFE_ROOT=~/caffe" >> ~/.bashrc
echo "export PYTHONPATH=${CAFFE_ROOT}/python:$PYTHONPATH" >> ~/.bashrc
source ~/.bashrc
如出錯參考鏈接 ,
重新打開一個終端視窗,輸入python,再輸入caffe,不出錯則添加環境變數成功,
三、anaconda3環境下安裝gpu版caffe
(一) ubuntu系統安裝anaconda3
(因為這里主要介紹anaconda3下的caffe環境配置,至于anaconda3的安裝,不做過多的贅述,)
1.下載及安裝
下載:anaconda安裝包下載,推薦官網,或者百度云,提取碼:zu0i,
安裝:網上很多教程,這里推薦一篇,
是否安裝成功:安裝完成后需要添加環境變數,查看環境變數終端輸入:
sudo gedit ~/.bashrc
打開.bashrc后看最后是否有如下字樣代碼
## >>> conda initialize >>>
## !! Contents within this block are managed by 'conda init' !!
__conda_setup="$('/home/×××/anaconda3/bin/conda' 'shell.bash' 'hook' 2> /dev/null)"
if [ $? -eq 0 ]; then
eval "$__conda_setup"
else
if [ -f "/home/×××/anaconda3/etc/profile.d/conda.sh" ]; then
. "/home/×××/anaconda3/etc/profile.d/conda.sh"
else
export PATH="/home/×××/anaconda3/bin:$PATH"
fi
fi
unset __conda_setup
## <<< conda initialize <<<
若沒有則復制進去,注意×××是自己的用戶名,
安裝完成后,終端命令列前出現默認環境(base),輸入conda不報錯說明安裝成功,
2.創建虛擬環境
- 創建名為
caffe的python2.7的虛擬環境并切換至該環境:
conda create -n caffe python=2.7
conda activate caffe
(二) 虛擬環境下安裝caffe
-
安裝依賴檔案如第二節所示,但是我遇到的問題是
sudo apt-get安裝的opencv庫在conda虛擬環境下無法呼叫,重新編譯安裝的opencv庫與我想安裝的caffe環境又有沖突,導致caffe編譯失敗,
這里給出我的解決方法:
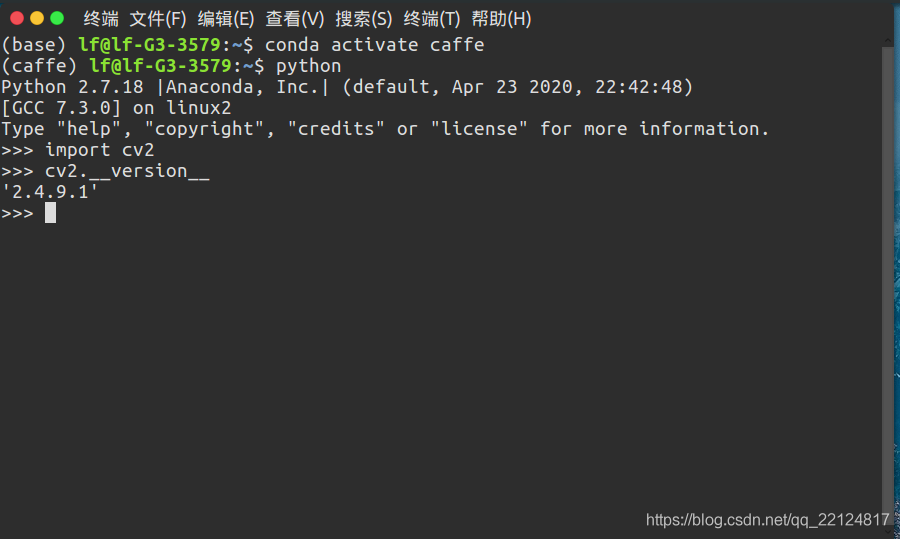
將usr/lib/python2.7/dist-packages目錄下的cv.py,cv.pyc和cv2.x86_64-linux-gnu.so三個檔案復制到anaconda3/envs/caffe/lib/python2.7/dist-packages檔案夾下,并將cv2.x86_64-linux-gnu.so改名為cv2.so
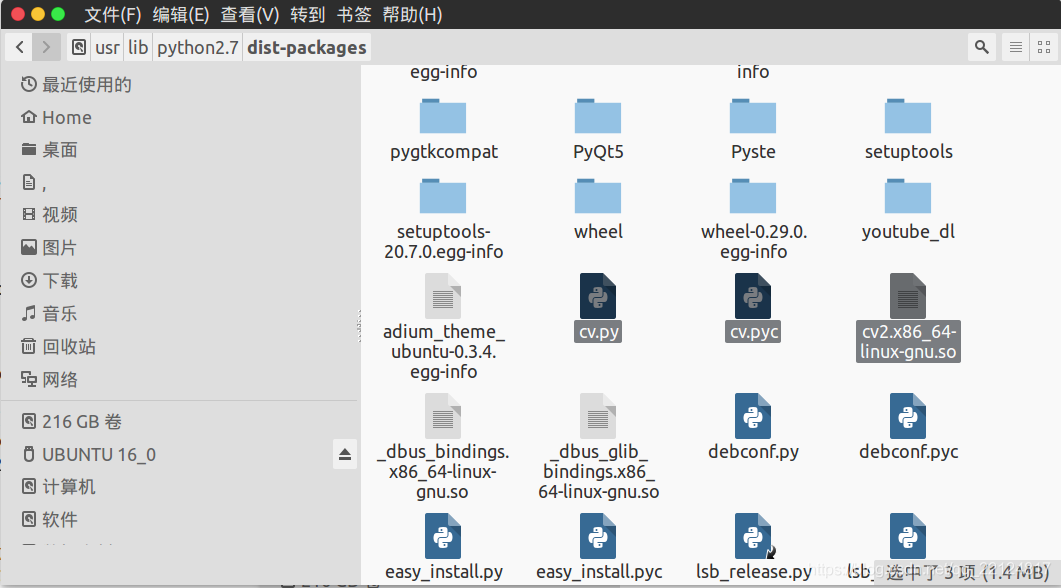
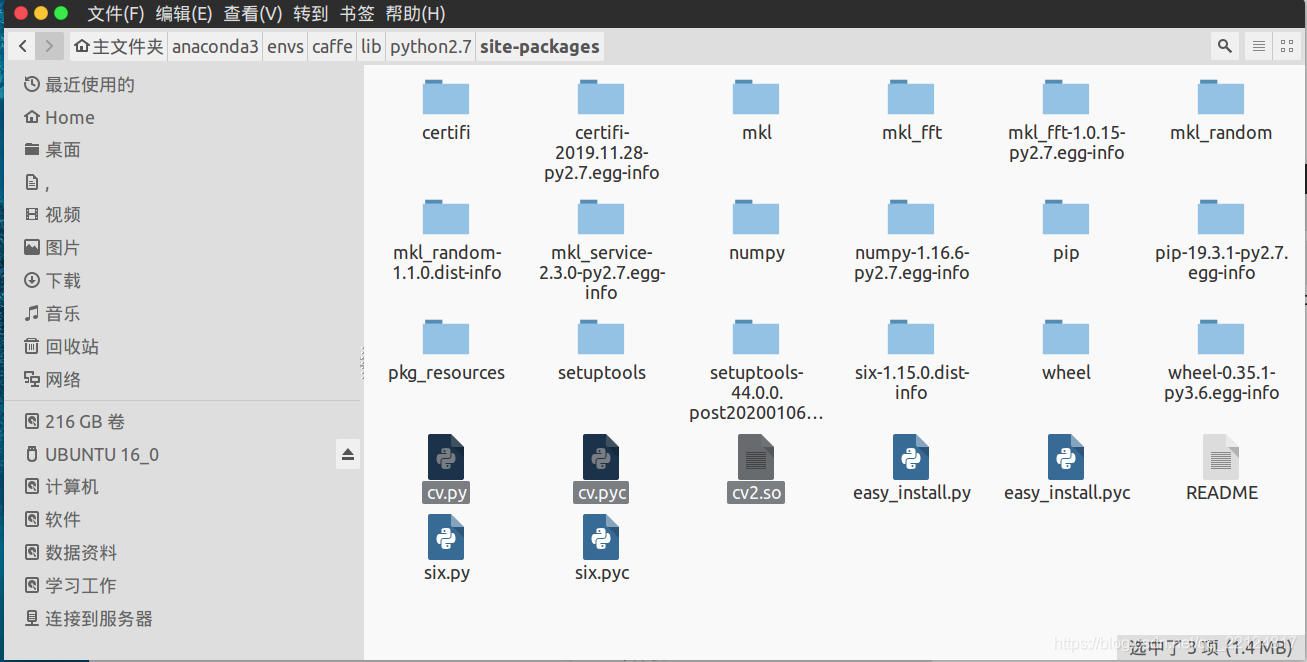
至此,caffe下的cv2版本才符合要求,如圖所示:
-
下載碼源(與前面一致)
在主目錄下(我的是/home/xxx/my_code,xxx為用戶名)打開命令視窗,依次輸入:
下載github上的caffe專案:git clone https://github.com/weiliu89/caffe.git切換到caffe檔案夾:
cd caffe -
切換到 ssd 分支
git checkout ssd
- 安裝python依賴庫
切換到 caffe 下的 python 目錄下,下載 python 依賴庫(先安裝 pip)
cd python
sudo apt-get install python-pip
for req in $(catpython requirements.txt); do pip install $req; done
- 修改組態檔
首先是Makefile.config檔案,將python的路徑改成anaconda下虛擬環境的python,其他的不變,
修改后如下:
## Refer to http://caffe.berkeleyvision.org/installation.html
# Contributions simplifying and improving our build system are welcome!
# cuDNN acceleration switch (uncomment to build with cuDNN).
USE_CUDNN := 1
# CPU-only switch (uncomment to build without GPU support).
# CPU_ONLY := 1
# uncomment to disable IO dependencies and corresponding data layers
# USE_OPENCV := 0
# USE_LEVELDB := 0
# USE_LMDB := 0
# uncomment to allow MDB_NOLOCK when reading LMDB files (only if necessary)
# You should not set this flag if you will be reading LMDBs with any
# possibility of simultaneous read and write
# ALLOW_LMDB_NOLOCK := 1
# Uncomment if you're using OpenCV 3
# OPENCV_VERSION := 3
# To customize your choice of compiler, uncomment and set the following.
# N.B. the default for Linux is g++ and the default for OSX is clang++
# CUSTOM_CXX := g++
# CUDA directory contains bin/ and lib/ directories that we need.
CUDA_DIR := /usr/local/cuda
# On Ubuntu 14.04, if cuda tools are installed via
# "sudo apt-get install nvidia-cuda-toolkit" then use this instead:
# CUDA_DIR := /usr
# CUDA architecture setting: going with all of them.
# For CUDA < 6.0, comment the lines after *_35 for compatibility.
CUDA_ARCH := -gencode arch=compute_30,code=sm_30 \
-gencode arch=compute_35,code=sm_35 \
-gencode arch=compute_50,code=sm_50 \
-gencode arch=compute_52,code=sm_52 \
-gencode arch=compute_61,code=sm_61
# BLAS choice:
# atlas for ATLAS (default)
# mkl for MKL
# open for OpenBlas
# BLAS := atlas
BLAS := open
# Custom (MKL/ATLAS/OpenBLAS) include and lib directories.
# Leave commented to accept the defaults for your choice of BLAS
# (which should work)!
# BLAS_INCLUDE := /path/to/your/blas
# BLAS_LIB := /path/to/your/blas
# Homebrew puts openblas in a directory that is not on the standard search path
# BLAS_INCLUDE := $(shell brew --prefix openblas)/include
# BLAS_LIB := $(shell brew --prefix openblas)/lib
# This is required only if you will compile the matlab interface.
# MATLAB directory should contain the mex binary in /bin.
# MATLAB_DIR := /usr/local
# MATLAB_DIR := /Applications/MATLAB_R2012b.app
# NOTE: this is required only if you will compile the python interface.
# We need to be able to find Python.h and numpy/arrayobject.h.
PYTHON_INCLUDE := /usr/include/python2.7 \
/usr/local/lib/python2.7/dist-packages/numpy/core/include
# Anaconda Python distribution is quite popular. Include path:
# Verify anaconda location, sometimes it's in root.
ANACONDA_HOME := /home/lf/anaconda3/envs/caffe
PYTHON_INCLUDE := $(ANACONDA_HOME)/include \
$(ANACONDA_HOME)/include/python2.7 \
$(ANACONDA_HOME)/lib/python2.7/site-packages/numpy/core/include \
# Uncomment to use Python 3 (default is Python 2)
# PYTHON_LIBRARIES := boost_python3 python3.5m
# PYTHON_INCLUDE := /usr/include/python3.5m \
# /usr/lib/python3.5/dist-packages/numpy/core/include
# We need to be able to find libpythonX.X.so or .dylib.
# PYTHON_LIB := /usr/lib
PYTHON_LIB := $(ANACONDA_HOME)/lib
LINKFLAGS := -Wl,-rpath,$(ANACONDA_HOME)/lib
# Homebrew installs numpy in a non standard path (keg only)
# PYTHON_INCLUDE += $(dir $(shell python -c 'import numpy.core; print(numpy.core.__file__)'))/include
# PYTHON_LIB += $(shell brew --prefix numpy)/lib
# Uncomment to support layers written in Python (will link against Python libs)
WITH_PYTHON_LAYER := 1
# Whatever else you find you need goes here.
INCLUDE_DIRS := $(PYTHON_INCLUDE) /usr/local/include \
/usr/include/hdf5/serial
LIBRARY_DIRS := $(PYTHON_LIB) /usr/local/lib /usr/lib \
/usr/lib/x86_64-linux-gnu/hdf5/serial
# If Homebrew is installed at a non standard location (for example your home directory) and you use it for general dependencies
# INCLUDE_DIRS += $(shell brew --prefix)/include
# LIBRARY_DIRS += $(shell brew --prefix)/lib
# Uncomment to use `pkg-config` to specify OpenCV library paths.
# (Usually not necessary -- OpenCV libraries are normally installed in one of the above $LIBRARY_DIRS.)
# USE_PKG_CONFIG := 1
# N.B. both build and distribute dirs are cleared on `make clean`
BUILD_DIR := build
DISTRIBUTE_DIR := distribute
# Uncomment for debugging. Does not work on OSX due to https://github.com/BVLC/caffe/issues/171
# DEBUG := 1
# The ID of the GPU that 'make runtest' will use to run unit tests.
TEST_GPUID := 0
# enable pretty build (comment to see full commands)
Q ?= @
其次是Makefile檔案,代碼比較多,避免一行行的去查找修改,這里直接給出修改好的Makefile檔案,)
剩下的編譯程序也是完全一樣,請參考前面部分,
至此,anconda下的caffe環境就安裝好了,
四、caffe環境下訓練MobileNet—SSD
本人安裝ubuntu下的caffe環境主要是利用自己的資料集訓練MobileNetSSD model,這部分可以參考鏈接,
最后,將訓練的模型.caffemodel模型檔案轉化成.tmfile檔案,在eaidk-310平臺上做推理,這部分內容可以參考下一篇博客,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/137394.html
標籤:其他
下一篇:聊聊近況,說說新作業