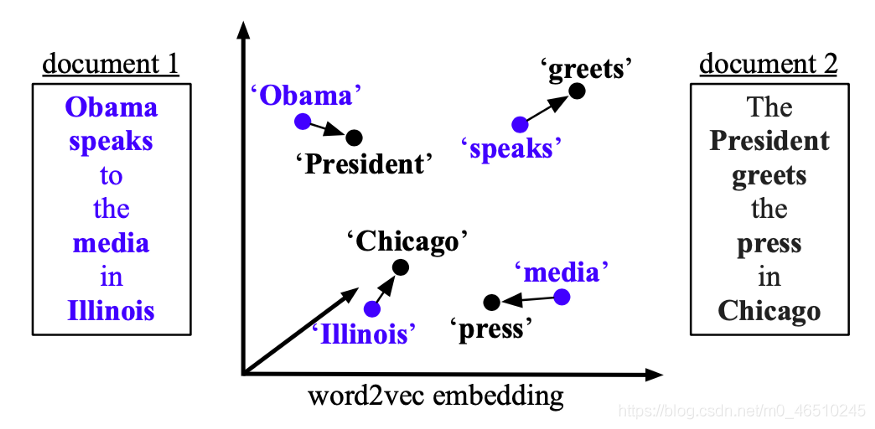
檔案分類和檔案檢索已顯示出廣泛的應用, 檔案分類的重要部分是正確生成檔案表示, 馬特·庫斯納(Matt J. Kusner)等人在2015年提出了Word Mover’s Distance(WMD)[1],其中將詞嵌入技術用于計算兩個檔案之間的距離, 使用給定的預訓練單詞嵌入,可以通過計算“一個檔案的嵌入單詞需要“移動”以到達另一檔案的嵌入單詞所需的最小距離”來用語意含義來度量檔案之間的差異,
在以下各節中,我們將討論WMD的原理,WMD的約束和近似,預取和修剪,WMD的性能,
WMD原理
如前所述,WMD嘗試測量兩個檔案的語意距離,并且語意測量是通過word2vec嵌入實作的, 具體而言,在他們的實驗中使用了跳過語法word2vec, 一旦獲得單詞嵌入,檔案之間的語意距離就由以下三個部分定義:檔案表示,相似性度量和(稀疏)流矩陣,
文本的文字表示
文本檔案用向量d表示,其中每個元素表示檔案中單詞的歸一化頻率,即
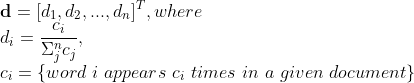
注意,檔案表示d是高維空間中的稀疏向量,
語意相似性度量定義
兩個給定單詞x_i和x_j在嵌入空間中的歐幾里得距離定義如下:
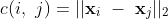
在WMD中,x_i和x_j來自不同的檔案,而c(i,j)是從單詞x_i到x_j的“移動成本”,
流矩陣定義
假設有一個原始檔案A和一個目標檔案B,定義了流矩陣T, 流矩陣中的每個元素T _ {ij}表示單詞i(在檔案A中)轉換為單詞j(在檔案B中)的次數,然后通過詞匯中單詞的總數對值進行歸一化, 也就是說,
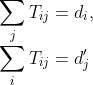
因此,語意距離定義如下:
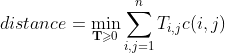
通過調整T中的值,可以獲得兩個檔案之間的語意距離, 距離也是將所有單詞從一個檔案移動到另一個檔案所需的最小累積成本,
約束和下界近似
最低累計成本有兩個限制,即
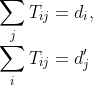
對于檔案A中的任何單詞i,檔案B中的任何單詞j
總的來說,受約束的最小累積成本的計算復雜度為O(p3logp),其中p是檔案中唯一單詞的數量, 也就是說,WMD可能不適用于大型檔案或具有大量唯一單詞的檔案, 在本文中,作者提出了兩種加快WMD計算的方法, 兩種加速方法均導致實際WMD值近似,
Word centroid distance(WCD)
通過使用三角不等式,可以證明累積成本始終大于或等于由單詞嵌入的平均值加權的檔案向量之間的歐幾里得距離,這樣,計算復雜度降低到O(dp)(在此,d代表檔案向量d的維,)
Relaxed WMD(RWMD)
目標有兩個限制,如果洗掉一個約束,則累積成本的最佳解決方案是將一個檔案中的每個單詞都移動到另一個檔案中最相似的單詞上,這意味著成本最小化問題變成了在嵌入空間中找到兩個單詞嵌入的最小歐幾里得距離,因此,通過洗掉一個約束并保留另一個約束,可以得到兩個近似的下限:我們稱它們為l1(對i保持約束)和l2(對j保持約束),更嚴格的近似值l可以定義為:
l = max(l1,l2)
利用這種近似的累積成本(作者稱為“松弛WMD”(RWMD)),計算復雜度降至O(p2),
預取和修剪
為了找到有效時間的查詢檔案的k個最近鄰居,可以同時使用WCD和RWMD來減少計算成本,
- 使用WCD估計每個檔案到查詢檔案之間的距離,
- 按升序對估計的距離進行排序,然后使用WMD計算到這些檔案的前k個確切的距離,
- 遍歷其余檔案(不在上一步的前k個檔案中),計算RWMD下限,
- 如果檔案(到查詢檔案)的RWMD近似值大于到前k個檔案的所有計算的WMD距離(在步驟2中),則意味著該檔案不得位于查詢文
- k個最近鄰居中,因此 可以修剪, 否則,將計算確切的WMD距離并更新到k個最近的鄰居,
WMD性能表現
作者在kNN背景關系中對八個檔案資料集評估了WMD性能,并將其與BOW,TFIDF,BM25 LSI,LDA,mSDA和CCG進行了比較, 他們的實驗表明,WMD在8個資料集中的6個資料集中表現最佳, 對于其余兩個資料集,即使WMD的性能不佳,錯誤率也非常接近最佳性能者,
一個有趣的實驗結果是作者進行了一項實驗,如果下限用于最近鄰居檢索,則評估下限的緊密度與kNN錯誤率之間的關系, 它表明緊密度并不能直接轉化為檢索精度, 在作者的陳述中,一次僅受到一個約束的RWMD的緊密度(稱為RWMD_c1和RWMD_c2)明顯高于WCD,但就kNN精度而言,RWMD_c1和RWMD_c2的性能都比WCD差, 就我的新觀點而言,這可能是由于對RWMD_c1和RWMD_c2施加了不對稱約束, 因為僅剩下一個約束得出距離度量的非嚴格定義,所以RWMD_c1和RWMD_c2都不是嚴格的距離近似值,
潛在的作業擴展
WMD在檔案分類任務中表現出色, 我認為,可以做一些試驗來進一步探究WMD,
作者使用了不同的資料集進行單詞嵌入生成,但是嵌入方法已通過skip-gram固定在word2vec上, 通過將word2vet更改為其他方法(例如GloVe),看到嵌入方法對WMD的重要性將很有趣,
請注意,WMD無法處理詞匯量(OOV)資料,并且在距離計算中遇到時會直接丟棄OOV單詞, 這可能是WMD性能未超過所有資料集的所有其他方法的原因, 可以基于背景關系資訊構建OOV詞的嵌入, 例如,BiLSTM語言模型可以幫助生成OOV詞嵌入[2], 同樣,位元組對編碼(BPE)也可以建立OOV詞嵌入,
參考
[1]From Word Embeddings To Document Distances http://proceedings.mlr.press/v37/kusnerb15.pdf
[2] Language Modelling for Handling Out-of-Vocabulary Words in Natural Language Processing https://www.researchgate.net/publication/335757797_Language_Modelling_for_Handling_Out-of-Vocabulary_Words_in_Natural_Language_Processing?showFulltext=1&linkId=5d7a26a04585151ee4afb0c5
[3] WMD 代碼 https://github.com/mkusner/wmd
作者:Adjacent
deephub翻譯組
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/138338.html
標籤:其他
上一篇:華為十年技術專家總結:進階成為架構師需要掌握哪些技能?從0到1
下一篇:按關鍵詞搜索采集新聞資訊文章教程