專案背景
最近,做一個按優先級和時間先后排隊的需求,用 Redis 的 sorted set 做排隊佇列,
主要使用的 Redis 命令有, zadd, zcount, zscore, zrange 等,
測驗完畢后,發到線上,發現有大量介面請求回傳超時熔斷(超時時間為3s),
Error日志列印的例外堆疊為:
redis.clients.jedis.exceptions.JedisConnectionException: Could not get a resource from the pool
Caused by: redis.clients.jedis.exceptions.JedisConnectionException: java.net.ConnectException: Connection timed out (Connection timed out)
Caused by: java.net.ConnectException: Connection timed out (Connection timed out)
且有一個怪異的現象,只有寫庫的邏輯報錯,即 zadd 操作,像 zadd, zcount, zscore 這些操作全部能正常執行,
還有就是報錯和正常執行交錯持續,即假設每分鐘有1000個 Redis 操作,其中900個正常,100個報錯,而不是報錯后,Redis 就不能正常使用了,
問題排查
1.連接池泄露?
從上面的現象基本可以排除連接池泄露的可能,如果連接未被釋放,那么一旦開始報錯,后面的 Redis 請求基本上都會失敗,而不是有90%都可正常執行,
但 Jedis 客戶端據說有高并發下連接池泄露的問題,所以為了排除一切可能,還是升級了 Jedis 版本,發布上線,發現沒什么用,
2.硬體原因?
排查 Redis 客戶端服務器性能指標,CPU利用率10%,記憶體利用率75%,磁盤利用率10%,網路I/O上行 1.12M/s,下行 2.07M/s,介面單實體QPS均值300左右,峰值600左右,
Redis 服務端連接總數徘徊在2000+,CPU利用率5.8%,記憶體使用率49%,QPS1500-2500,
硬體指標似乎也沒什么問題,
3.Redis引數配置問題?
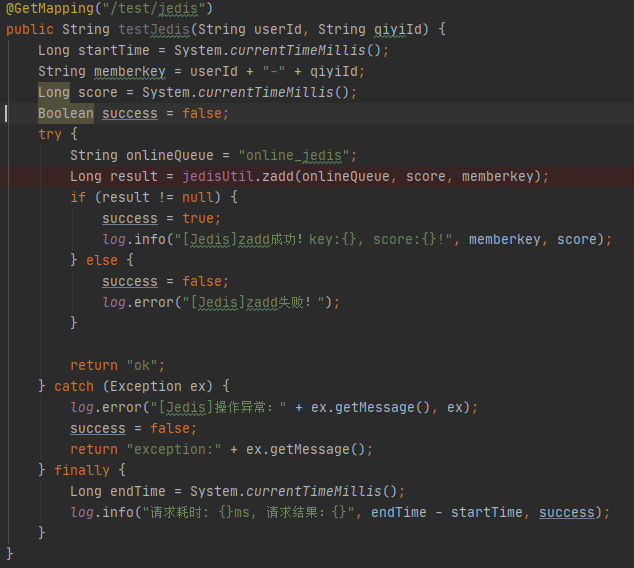
1 JedisPoolConfig config = new JedisPoolConfig(); 2 config.setMaxTotal (200); // 最大連接數 3 config.setMinIdle (5); // 最小空閑連接數 4 config.setMaxIdle (50); // 最大空閑連接數 5 config.setMaxWaitMillis (1000 * 1); // 最長等待時間 6 config.setTestOnReturn (false); 7 config.setTestOnBorrow (false); 8 config.setTestWhileIdle (true); 9 config.setTimeBetweenEvictionRunsMillis (30 * 1000); 10 config.setNumTestsPerEvictionRun (50);
基本上大部分公司的配置包括網上博客提供的配置其實都和上面差不多,看不出有什么問題,
這里我嘗試把最大連接數調整到500,發布到線上,并沒什么卵用,報錯數反而變多了,
4.連接數統計
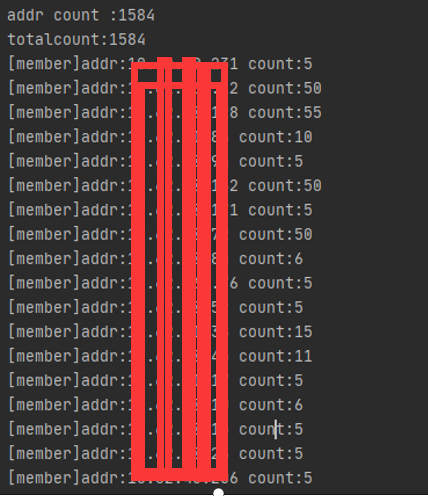
在 Redis Master 庫上執行命令:client list,列印出當前所有連接到服務器的客戶端IP,并過濾出當前服務的IP地址的連接,
發現均未達到最大連接數,確實排除了連接泄露的可能,
5.最大連接數調優和壓測
既然連接遠未打滿,說明不需要設定那么大的連接數,而 Redis 服務端又是單執行緒讀寫,客戶端創建過多連接,只會耗費資源,反而拖累性能,
使用以上代碼,在本機使用 JMeter 壓測300個執行緒,連續請求30秒,
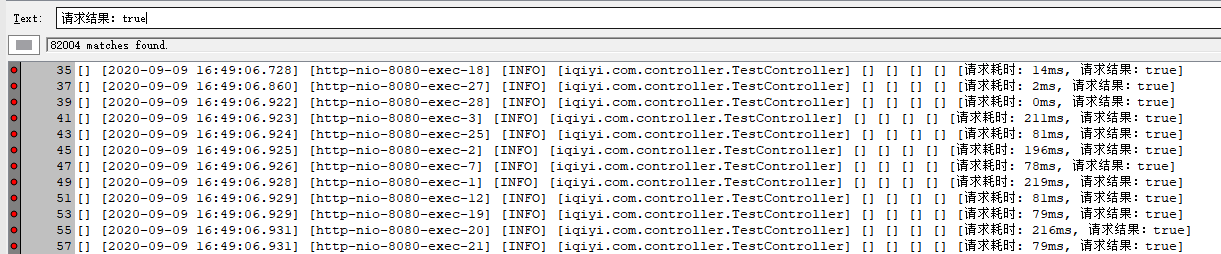
首先把最大連接數設為500,成功率:99.61%
請求成功:82004次,TP90耗時目測在50-80ms左右,
請求失敗322次,全部為請求服務器超時:socket read timeout,耗時2s后,由 Jedis 自行熔斷,
(這種情況造成資料不一致,實際上服務端已執行了命令,只是客戶端讀取回傳結果超時),

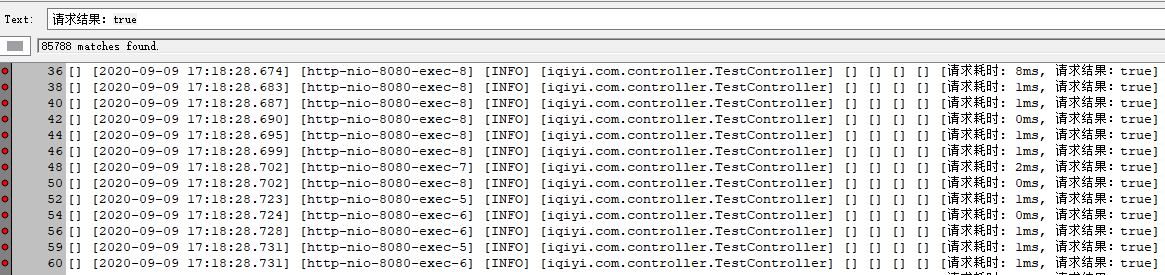
再把最大連接數設為20,成功率:98.62%(有一定幾率100%成功)
請求成功:85788次,TP90耗時在10ms左右,
請求失敗:1200次,全部為等待客戶端連接超時:Caused by: java.util.NoSuchElementException: Timeout waiting for idle object,熔斷時間為1秒,
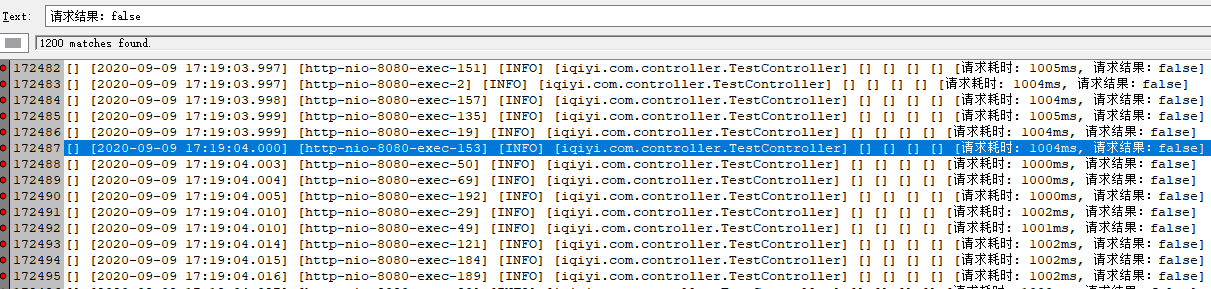
再將最大連接數調整為50,成功率:100%
請求成功:85788次, TP90耗時10ms,
請求失敗:0次,
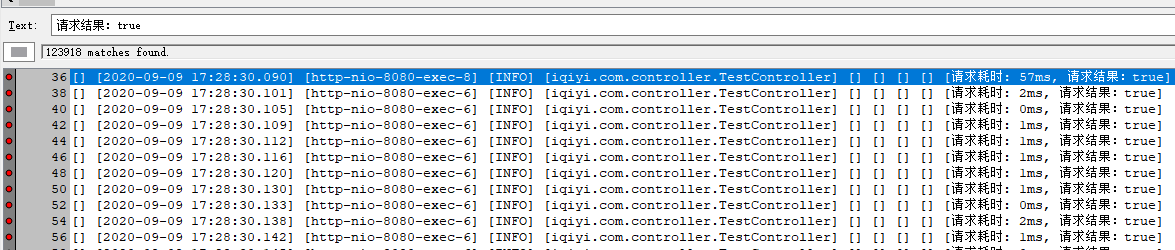
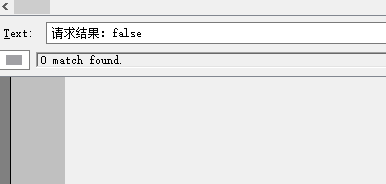
綜上,Redis 服務端單執行緒讀寫,連接數太多并沒卵用,反而會消耗更多資源,最大連接數配置太小,不能滿足并發需求,執行緒會因為拿不到空閑連接而超時退出,
在滿足并發的前提下,maxTotal連接數越小越好,在300執行緒并發下,最大連接數設為50,可以穩定運行,
基于以上結論,嘗試調整 Redis 引數配置并發布上線,但以上實驗只執行了 zadd 命令,仍未解決一個問題:為什么只有寫庫報錯?
果然,發布上線后,介面超時次數有所減少,回應時間有所提升,但仍有報錯,沒能解決此問題,
6.插曲 - Redis鎖
在優化此服務的同時,把同事使用的另一個 Redis 客戶端一起優化了,結果同事的介面過了一天開始大面積報錯,介面回應時間達到8個小時,
排查發現,同事的介面僅使用 Redis 作為分布式鎖,而這個 RedisLock 類是從其他服務拿過來直接用的,自旋時間設定過長,這個介面又是超高并發,
最大連接數設為50后,鎖資源競爭激烈,直接導致大部分執行緒自旋把連接池耗盡了,于是又緊急把最大連接池恢復到200,問題得以解決,
由此可見,在分布式鎖的場景下,配置不能完全參考讀寫 Redis 操作的配置,
7.排查服務端持久化
在把客戶端研究了好幾遍之后,發現并沒有什么可以優化的了,于是開始懷疑是服務端的問題,
持久化是一直沒研究過的問題,在查閱了網上的一些博客,發現持久化確實有可能阻塞讀寫IO的,
“1) 對于沒有持久化的方式,讀寫都在資料量達到800萬的時候,性能下降幾倍,此時正好是達到記憶體10G,Redis開始換出到磁盤的時候,并且從那以后再也沒辦法重新振作起來,性能比Mongodb還要差很多,
2) 對于AOF持久化的方式,總體性能并不會比不帶持久化方式差太多,都是在到了千萬資料量,記憶體占滿之后讀的性能只有幾百,
3) 對于Dump持久化方式,讀寫性能波動都比較大,可能在那段時候正在Dump也有關系,并且在達到了1400萬資料量之后,讀寫性能貼底了,在Dump的時候,不會進行換出,而且所有修改的資料還是創建的新頁,記憶體占用比平時高不少,超過了15GB,而且Dump還會壓縮,占用了大量的CPU,也就是說,在那個時候記憶體、磁盤和CPU的壓力都接近極限,性能不差才怪,” ---- 參考自lovecindywang 的博客園博客
“記憶體越大,觸發持久化的操作阻塞主執行緒的時間越長
Redis是單執行緒的記憶體資料庫,在redis需要執行耗時的操作時,會fork一個新行程來做,比如bgsave,bgrewriteaof, Fork新行程時,雖然可共享的資料內容不需要復制,但會復制之前行程空間的記憶體頁表,這個復制是主執行緒來做的,會阻塞所有的讀寫操作,并且隨著記憶體使用量越大耗時越長,例如:記憶體20G的redis,bgsave復制記憶體頁表耗時約為750ms,redis主執行緒也會因為它阻塞750ms,” ---- 參考自CSDN博客
而我們的Redis實體總記憶體20G,記憶體使用了50%,keys數量達4000w,
主從集群,從庫不做持久化,主庫使用RDB持久化,rdb的save引數是默認值,(這也恰好能解釋通為什么寫庫報錯,讀庫正常)
且此 Redis 已使用了幾年,里面可能存在大量的key已經不使用了,但未設定過期時間,
然而,像 Redis、MySQL 這種都是由資料中臺負責,我們并無權查看服務端日志,這個事情也不好推動,中臺會說客戶端使用的有問題,建議調整引數,
所以最佳解決方案可能是,重新申請 Redis 實體,逐步把專案中使用的 Redis 遷移到新實體,并注意設定過期時間,遷移完成后,把老的 Redis 實體廢棄回收,
小結
1)如果簡單的在網上搜索,Could not get a resource from the pool , 基本都是些連接未釋放的問題,
然而很多原因可能導致 Jedis 報這個錯,這條資訊并不是例外堆疊的最頂層,
2)Redis其實只適合作為快取,而不是資料庫或是存盤,它的持久化方式適用于救救急啥的,不太適合當作一個普通功能來用,
3)還是建議任何資料都設定過期時間,哪怕設1年呢,不然老的專案可能已經都廢棄了,殘留在 Redis 里的 key,其他人也不敢刪,
4)不要存放垃圾資料到 Redis 中,及時清理無用資料,業務下線了,就把相關資料清理掉,
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/143020.html
標籤:NoSQL
下一篇:破解彩虹貓病毒