文章目錄
- AC自動機
- 原理
- 模板
- 例題
- HDU-2222Keywords Search
- HDU-2896病毒侵襲
- HDU-3065病毒侵襲持續中
- POJ-2778DNA Sequence
- HDU-2296Ring
AC自動機
AC自動機(Aho-Corasick automaton)是KMP的升級版,即KMP是單模匹配演算法,處理一個文本串中查找一個模式串的問題;而AC自動機能在一個文本串中同時查找多個不同的模式串,是多模匹配演算法,
其實KMP也能做多模匹配,對每一個模式串做一次KMP,復雜度是
O
(
k
(
n
+
m
)
)
O(k(n+m))
O(k(n+m));AC自動機演算法只需搜索一遍,搜索時匹配所有的模式串,復雜度是
O
(
k
m
+
n
m
)
O(km+nm)
O(km+nm),當
m
<
<
k
m<<k
m<<k時,AC自動機優勢很大,
原理
建議先了解KMP和字典樹,
那么如何同時匹配所有的模式串
P
P
P?
這時結合KMP和字典樹就可以開始秀了,如果把所有的
P
P
P做成一個字典樹,然后在匹配的時候查找這個
P
P
P對應的
n
e
x
t
next
next,即失敗指標
F
a
i
l
Fail
Fail,使當前字符失配時跳轉到具有最長公共前后綴的字符繼續匹配(同KMP),這樣就能實作同時搜索的快速匹配了,
步驟
- 構建字典樹
- 構造fail失敗指標
- 搜索待處理文本
Fail指標
同KMP的next一樣,Fail指標是AC自動機的核心,是在樹上指出失配后下一個跳轉的位置,而不用全部回溯,大大減少時間,那么Fail是怎么跳轉的?
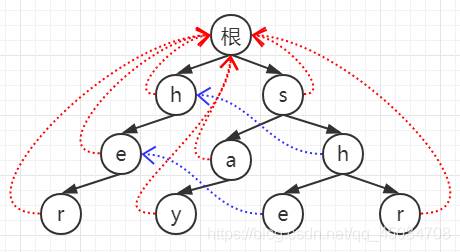
以HDU-2222的樣例為例說明,模式串P={“she”,“he”,“say”,“shr”,“her”},文本串S=“yasherhs”,
1.構建字典樹
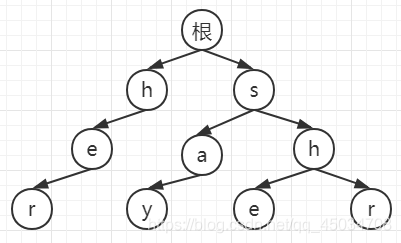
- 構造fail指標
2.1 用bfs實作,將root子節點入隊(第二層),并將其fail指向root,
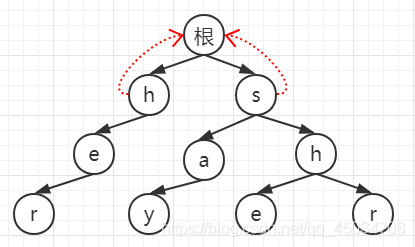
2.2 h出隊,父節點h的fail指標所指節點是root;此時root沒有對應為e的子節點,匹配失敗,則e的fail指標指向root,表示沒有匹配序列,然后入隊e;同樣的s出隊,其子節點a同理,
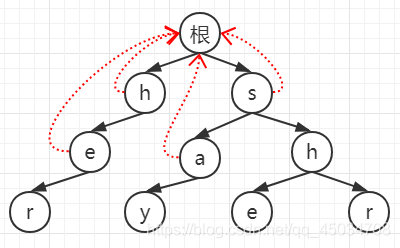
2.3 此時回圈到s的子節點h,父節點s的fail指標所指節點也是root,但與前面不同的是:root有值為h的子節點,匹配成功,此時fail應指向匹配節點,
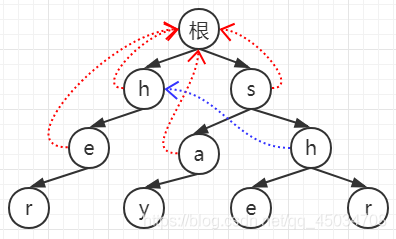
2.4 以此類推,求出所有fail指標,右側e的父節點h的fail指標所指節點是左側h,而左側h有值為e的子節點,匹配成功,即右側e的fail指向左側e(藍線),如圖,
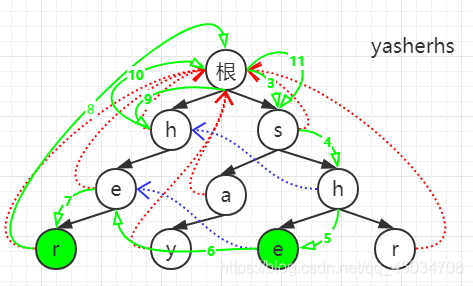
- 搜索待處理文本
①首先根結點下無y和a,第1、2條線還是指向根結點;
②從she開始一直可以匹配,即線3、4、5,到節點e(綠底),更新答案;
③下一個字符是r,匹配失敗,到fail指標所指節點(藍線所指),即線6;
④此時匹配到了r(線7),發現模式串末尾標記,更新答案;
⑤下一個字符h,失配,回到fail所指(線8)
⑥然后繼續匹配,成功(線9)
⑦繼續下一個字符s,失配回溯(線10)
⑧繼續匹配,成功(線11),最后一個字符結束,退出
模板
void insert(char* p) { //構建字典樹
int u = 0;
int ls = strlen(p);
for (int i = 0; i < ls; i++) {
int v = p[i] - 'a';
if (trie[u][v]==0)
trie[u][v] = ++pos;
u = trie[u][v];
}
cnt[u]++; //當前節點單詞數+1
}
void getFail() { //求fail
queue <int>q;
for (int i = 0; i < 26; i++) { //入隊root子節點(第二層)
if (trie[0][i]) {
fail[trie[0][i]] = 0;
q.push(trie[0][i]);
}
}
while (!q.empty()) {
int cur = q.front();//當前父節點
q.pop();
for (int i = 0; i < 26; i++) { //26個字母
if (trie[cur][i]) { //存在子節點,將其fail指向對應匹配節點(父節點fail所指節點的對應子節點)
fail[trie[cur][i]] = trie[fail[cur]][i];
q.push(trie[cur][i]);
}
else//若不存在相關子節點,字典樹中賦值為fail所指節點
trie[cur][i] = trie[fail[cur]][i];
}
}
}
int query(char* s) { //查詢s中出現幾個p
int cur = 0, ans = 0, ls = strlen(s);
for (int i = 0; i < ls; i++) {
cur = trie[cur][s[i] - 'a'];
for (int j = cur; j && cnt[j]; j = fail[j]) {//一直向下尋找,直到匹配失敗
ans += cnt[j]; //更新答案
cnt[j] = 0; //防止重復計算
}
}
return ans;
}
例題
HDU-2222Keywords Search
HDU-2222Keywords Search
Problem Description
In the modern time, Search engine came into the life of everybody like Google, Baidu, etc.
Wiskey also wants to bring this feature to his image retrieval system.
Every image have a long description, when users type some keywords to find the image, the system will match the keywords with description of image and show the image which the most keywords be matched.
To simplify the problem, giving you a description of image, and some keywords, you should tell me how many keywords will be match.
Input
First line will contain one integer means how many cases will follow by.
Each case will contain two integers N means the number of keywords and N keywords follow. (N <= 10000)
Each keyword will only contains characters ‘a’-‘z’, and the length will be not longer than 50.
The last line is the description, and the length will be not longer than 1000000.
Output
Print how many keywords are contained in the description.
Sample Input
1
5
she
he
say
shr
her
yasherhs
Sample Output
3
分析:
模板題,分析同上
#include<bits/stdc++.h>
using namespace std;
typedef long long ll;
const int maxn = 1000006;
int trie[maxn][26]; //字典樹
int cnt[maxn]; //記錄單詞出現次數
int fail[maxn]; //失敗時的回溯指標
int pos;
void insert(char* p) {
int u = 0;
int ls = strlen(p);
for (int i = 0; i < ls; i++) {
int v = p[i] - 'a';
if (trie[u][v] == 0)
trie[u][v] = ++pos;
u = trie[u][v];
}
cnt[u]++;
}
void getFail() {
queue <int>q;
for (int i = 0; i < 26; i++) {
if (trie[0][i]) {
fail[trie[0][i]] = 0;
q.push(trie[0][i]);
}
}
while (!q.empty()) {
int cur = q.front();
q.pop();
for (int i = 0; i < 26; i++) {
if (trie[cur][i]) {
fail[trie[cur][i]] = trie[fail[cur]][i];
q.push(trie[cur][i]);
}
else
trie[cur][i] = trie[fail[cur]][i];
}
}
}
int query(char* s) {
int cur = 0, ans = 0, ls = strlen(s);
for (int i = 0; i < ls; i++) {
cur = trie[cur][s[i] - 'a'];
for (int j = cur; j && cnt[j]; j = fail[j]) {
ans += cnt[j];
cnt[j] = 0;
}
}
return ans;
}
int main() {
int n, t;
char s[maxn], p[maxn];//不喜歡傳參,全域也行
scanf("%d", &t);
while (t--) {
scanf("%d", &n);
memset(trie, 0, sizeof(trie));
memset(cnt, 0, sizeof(cnt));
fail[0] = pos = 0;
for (int i = 0; i < n; i++) {
scanf("%s", p);
insert(p);
}
getFail();
scanf("%s", s);
printf("%d\n", query(s));
}
return 0;
}
HDU-2896病毒侵襲
HDU-2896病毒侵襲
Problem Description
當太陽的光輝逐漸被月亮遮蔽,世界失去了光明,大地迎來最黑暗的時刻,,,,在這樣的時刻,人們卻例外興奮——我們能在有生之年看到500年一遇的世界奇觀,那是多么幸福的事兒啊~~
但網路上總有那么些網站,開始借著民眾的好奇心,打著介紹日食的旗號,大肆傳播病毒,小t不幸成為受害者之一,小t如此生氣,他決定要把世界上所有帶病毒的網站都找出來,當然,誰都知道這是不可能的,小t卻執意要完成這不能的任務,他說:“子子孫孫無窮匱也!”(愚公后繼有人了),
萬事開頭難,小t收集了好多病毒的特征碼,又收集了一批詭異網站的原始碼,他想知道這些網站中哪些是有病毒的,又是帶了怎樣的病毒呢?順便還想知道他到底收集了多少帶病毒的網站,這時候他卻不知道何從下手了,所以想請大家幫幫忙,小t又是個急性子哦,所以解決問題越快越好哦~~
Input
第一行,一個整數N(1<=N<=500),表示病毒特征碼的個數,
接下來N行,每行表示一個病毒特征碼,特征碼字串長度在20—200之間,
每個病毒都有一個編號,依此為1—N,
不同編號的病毒特征碼不會相同,
在這之后一行,有一個整數M(1<=M<=1000),表示網站數,
接下來M行,每行表示一個網站原始碼,原始碼字串長度在7000—10000之間,
每個網站都有一個編號,依此為1—M,
以上字串中字符都是ASCII碼可見字符(不包括回車),
Output
依次按如下格式輸出按網站編號從小到大輸出,帶病毒的網站編號和包含病毒編號,每行一個含毒網站資訊,
web 網站編號: 病毒編號 病毒編號 …
冒號后有一個空格,病毒編號按從小到大排列,兩個病毒編號之間用一個空格隔開,如果一個網站包含病毒,病毒數不會超過3個,
最后一行輸出統計資訊,如下格式
total: 帶病毒網站數
冒號后有一個空格,
Sample Input
3
aaa
bbb
ccc
2
aaabbbccc
bbaacc
Sample Output
web 1: 1 2 3
total: 1
分析:
套AC自動機,把P構建字典樹,查詢時用vector記錄經過哪些單詞,注意初始化,
注意有坑最后輸出total要帶換行,字串是ASCLL碼范圍0-126,還有要排序,
#include<bits/stdc++.h>
using namespace std;
const int maxn = 100005;
int trie[maxn][130];
int fail[maxn], cnt[maxn];
int vis[maxn], tag[maxn];
int n, m, pos = 0, total = 0;
char s[maxn], p[202];
queue<int>q;
vector<int>ans;
void insert(int idx) {
int u = 0, lp = strlen(p);
for (int i = 0; i < lp; i++) {
int v = p[i];
if (trie[u][v] == 0)
trie[u][v] = ++pos;
u = trie[u][v];
}
cnt[u]++;
tag[u] = idx;
}
void getfail() {
for (int i = 0; i < 130; i++) {
if (trie[0][i]) {
fail[trie[0][i]] = 0;
q.push(trie[0][i]);
}
}
while (!q.empty()) {
int cur = q.front();
q.pop();
for (int i = 0; i < 130; i++) {
if (trie[cur][i]) {
fail[trie[cur][i]] = trie[fail[cur]][i];
q.push(trie[cur][i]);
}
else trie[cur][i] = trie[fail[cur]][i];
}
}
}
void query() {
int ls = strlen(s), u = 0;
for (int i = 0; i < ls; i++) {
u = trie[u][s[i]];
for (int j = u; j && !vis[j]&&cnt[j]; j = fail[j]) {
ans.push_back(tag[j]);
vis[j] = 1;
}
}
}
int main() {
scanf("%d", &n);
for (int i = 1; i <= n; i++) {
scanf("%s", p);
insert(i);
}
scanf("%d", &m);
getfail();
for (int i = 1; i <= m; i++) {
ans.clear();
memset(vis, 0, sizeof(vis));
scanf("%s", s);
query();
if (!ans.empty()) {
total++;
sort(ans.begin(), ans.end());
printf("web %d:", i);
for (int j = 0; j < ans.size(); j++)
printf(" %d", ans[j]);
printf("\n");
}
}
printf("total: %d\n", total);
return 0;
}
HDU-3065病毒侵襲持續中
HDU-3065病毒侵襲持續中
Problem Description
小t非常感謝大家幫忙解決了他的上一個問題,然而病毒侵襲持續中,在小t的不懈努力下,他發現了網路中的“萬惡之源”,這是一個龐大的病毒網站,他有著好多好多的病毒,但是這個網站包含的病毒很奇怪,這些病毒的特征碼很短,而且只包含“英文大寫字符”,當然小t好想好想為民除害,但是小t從來不打沒有準備的戰爭,知己知彼,百戰不殆,小t首先要做的是知道這個病毒網站特征:包含多少不同的病毒,每種病毒出現了多少次,大家能再幫幫他嗎?
Input
第一行,一個整數N(1<=N<=1000),表示病毒特征碼的個數,
接下來N行,每行表示一個病毒特征碼,特征碼字串長度在1—50之間,并且只包含“英文大寫字符”,任意兩個病毒特征碼,不會完全相同,
在這之后一行,表示“萬惡之源”網站原始碼,原始碼字串長度在2000000之內,字串中字符都是ASCII碼可見字符(不包括回車),
Output
按以下格式每行一個,輸出每個病毒出現次數,未出現的病毒不需要輸出,
病毒特征碼: 出現次數
冒號后有一個空格,按病毒特征碼的輸入順序進行輸出,
Sample Input
3
AA
BB
CC
ooxxCC%dAAAoen…END
Sample Output
AA: 2
CC: 1
Hint
Hit:
題目描述中沒有被提及的所有情況都應該進行考慮,比如兩個病毒特征碼可能有相互包含或者有重疊的特征碼段,
計數策略也可一定程度上從Sample中推測,
分析:
統計各單詞出現次數,記錄各單詞末尾節點對應單詞編號,查詢時若經過則維護更新對應單詞數量,
注意陣列大小和初始化,還有神坑多組資料!
#include<bits/stdc++.h>
using namespace std;
const int maxn = 50004;
int trie[maxn][130];
int fail[maxn], num[maxn], cnt[maxn];
char p[1003][55], s[2000006];
int n, pos;
void insert(int idx) {
int lp = strlen(p[idx]), u = 0;
for (int i = 0; i < lp; i++) {
int v = p[idx][i];
if (trie[u][v] == 0)
trie[u][v] = ++pos;
u = trie[u][v];
}
num[u] = idx; //對應單詞編號
}
void getfail() {
queue<int>q;
for (int i = 0; i < 130; i++) {
if (trie[0][i]) {
fail[trie[0][i]] = 0;
q.push(trie[0][i]);
}
}
while (!q.empty()) {
int cur = q.front();
q.pop();
for (int i = 0; i < 130; i++) {
if (trie[cur][i]) {
fail[trie[cur][i]] = trie[fail[cur]][i];
q.push(trie[cur][i]);
}
else trie[cur][i] = trie[fail[cur]][i];
}
}
}
void query() {
int u = 0, ls = strlen(s);
for (int i = 0; i < ls; i++) {
u = trie[u][s[i]];
for (int j = u; j; j = fail[j]) {
cnt[num[j]]++; //經過時更新數量++
}
}
}
int main() {
while (~scanf("%d", &n)) {
memset(trie, 0, sizeof(trie));
memset(cnt, 0, sizeof(cnt));
memset(num, 0, sizeof(num));
pos = 0;
for (int i = 1; i <= n; i++) {
scanf("%s", p[i]);
insert(i);
}
getfail();
scanf("%s", s);
query();
for (int i = 1; i <= n; i++)
if (cnt[i])
printf("%s: %d\n", p[i], cnt[i]);
}
return 0;
}
POJ-2778DNA Sequence
POJ-2778DNA Sequence
Description
It’s well known that DNA Sequence is a sequence only contains A, C, T and G, and it’s very useful to analyze a segment of DNA Sequence,For example, if a animal’s DNA sequence contains segment ATC then it may mean that the animal may have a genetic disease. Until now scientists have found several those segments, the problem is how many kinds of DNA sequences of a species don’t contain those segments.
Suppose that DNA sequences of a species is a sequence that consist of A, C, T and G,and the length of sequences is a given integer n.
Input
First line contains two integer m (0 <= m <= 10), n (1 <= n <=2000000000). Here, m is the number of genetic disease segment, and n is the length of sequences.
Next m lines each line contain a DNA genetic disease segment, and length of these segments is not larger than 10.
Output
An integer, the number of DNA sequences, mod 100000.
Sample Input
4 3
AT
AC
AG
AA
Sample Output
36
分析:
求不包含病毒串的長度為n的DNA串有多少種,
AC自動機+矩陣快速冪:把病毒串建字典樹,并在末尾標記;題目保證節點數不超過100,那么就可以用一個二維矩陣,
i
i
i行
j
j
j列的值表示從節點
i
i
i轉移到節點
j
j
j的方案數,然后進行
n
n
n次轉移,即該矩陣的
n
n
n次冪(離散數學結論),然后統計從根節點0到其他節點的方案數(即所有長度為n的合法串),
注意long long,
#include<cstdio>
#include<cstring>
#include<queue>
#include<map>
using namespace std;
const int maxn = 102;
const int mod = 100000;
int trie[maxn][4], fail[maxn], tail[maxn];
int n, m, pos;
char s[15];
map<char, int>idx;
void insert() {
int ls = strlen(s), u = 0;
for (int i = 0; i < ls; i++) {
int v = idx[s[i]];
if (trie[u][v] == 0)
trie[u][v] = ++pos;
u = trie[u][v];
}
tail[u] = 1;
}
void getfail() {
queue<int>q;
for (int i = 0; i < 4; i++) {
if (trie[0][i]) {
fail[trie[0][i]] = 0;
q.push(trie[0][i]);
}
}
while (!q.empty()) {
int cur = q.front();
q.pop();
for (int i = 0; i < 4; i++) {
if (trie[cur][i]) {
fail[trie[cur][i]] = trie[fail[cur]][i];
q.push(trie[cur][i]);
}
else trie[cur][i] = trie[fail[cur]][i];
tail[trie[cur][i]] |= tail[trie[fail[cur]][i]]; //注意是或,只要包含病毒就不行
}
}
}
struct matrix {
long long a[maxn][maxn];
matrix() {
memset(a, 0, sizeof(a));
}
};
matrix operator*(const matrix& x, const matrix& y) {
matrix m;
for (int i = 0; i <= pos; ++i)
for (int j = 0; j <= pos; ++j)
for (int k = 0; k <= pos; ++k)
m.a[i][j] = (m.a[i][j] + x.a[i][k] * y.a[k][j]) % mod;
return m;
}
matrix fastm(matrix a, int n) {
matrix res;
for (int i = 0; i <= pos; ++i) res.a[i][i] = 1;
while (n) {
if (n & 1) res = res * a;
a = a * a;
n >>= 1;
}
return res;
}
int main() {
idx['A'] = 0, idx['C'] = 1;
idx['T'] = 2, idx['G'] = 3;
while (~scanf("%d%d", &m, &n)) {
pos = 0;
memset(trie, 0, sizeof(trie));
memset(tail, 0, sizeof(tail));
while (m--) {
scanf("%s", s);
insert();
}
getfail();
matrix x;
for (int i = 0; i <= pos; ++i) //構建初始矩陣
if (!tail[i]) //如果本身不含病毒
for (int j = 0; j < 4; ++j)
if (!tail[trie[i][j]]) //其子節點也不含病毒
x.a[i][trie[i][j]]++; //那么節點i到該子節點是可行方案+1
x = fastm(x, n);
int ans = 0;
for (int i = 0; i <= pos; ++i) //統計
ans = (ans + x.a[0][i]) % mod;
printf("%d\n", ans);
}
return 0;
}
HDU-2296Ring
HDU-2296Ring
Problem Description
For the hope of a forever love, Steven is planning to send a ring to Jane with a romantic string engraved on. The string’s length should not exceed N. The careful Steven knows Jane so deeply that he knows her favorite words, such as “love”, “forever”. Also, he knows the value of each word. The higher value a word has the more joy Jane will get when see it.
The weight of a word is defined as its appeared times in the romantic string multiply by its value, while the weight of the romantic string is defined as the sum of all words’ weight. You should output the string making its weight maximal.
Input
The input consists of several test cases. The first line of input consists of an integer T, indicating the number of test cases. Each test case starts with a line consisting of two integers: N, M, indicating the string’s length and the number of Jane’s favorite words. Each of the following M lines consists of a favorite word Si. The last line of each test case consists of M integers, while the i-th number indicates the value of Si.
Technical Specification
- T ≤ 15
- 0 < N ≤ 50, 0 < M ≤ 100.
- The length of each word is less than 11 and bigger than 0.
- 1 ≤ Hi ≤ 100.
- All the words in the input are different.
- All the words just consist of ‘a’ - ‘z’.
Output
For each test case, output the string to engrave on a single line.
If there’s more than one possible answer, first output the shortest one. If there are still multiple solutions, output the smallest in lexicographically order.
The answer may be an empty string.
Sample Input
2
7 2
love
ever
5 5
5 1
ab
5
Sample Output
lovever
abab
Hint
Sample 1: weight(love) = 5, weight(ever) = 5, so weight(lovever) = 5 + 5 = 10
Sample 2: weight(ab) = 2 * 5 = 10, so weight(abab) = 10
分析:
AC自動機+DP:給出若干待權值的模式串,輸出長度不超過n的最大權值且字典序最小的S,先建AC自動機,定義狀態
d
p
[
s
t
e
p
,
u
]
dp[step,u]
dp[step,u]表示長度為step、在u節點上的最大權值,狀態轉移方程為
-
d
p
[
s
t
e
p
,
u
]
=
m
a
x
(
d
p
[
s
t
e
p
?
1
,
v
]
+
c
o
s
t
[
u
]
)
dp[step,u]=max(dp[step-1,v]+cost[u])
dp[step,u]=max(dp[step?1,v]+cost[u])
其中,v為能到達u的前一個節點,cost是權值,
#include<bits/stdc++.h>
using namespace std;
const int maxn = 1003;
int trie[maxn][26], fail[maxn];
int val[maxn], cost[102], dp[55][maxn];
char h[105][15];
string path[55][maxn];
int t, n, m, pos;
void insert(char* s, int idx) {
int ls = strlen(s), u = 0;
for (int i = 0; i < ls; ++i) {
int v = s[i] - 'a';
if (trie[u][v] == 0)
trie[u][v] = ++pos;
u = trie[u][v];
}
val[u] = cost[idx];
}
void getfail() {
queue<int>q;
fail[0] = 0;
for (int i = 0; i < 26; ++i) {
if (trie[0][i]) {
fail[trie[0][i]] = 0;
q.push(trie[0][i]);
}
}
while (!q.empty()) {
int cur = q.front();
q.pop();
for (int i = 0; i < 26; ++i) {
if (trie[cur][i]) {
fail[trie[cur][i]] = trie[fail[cur]][i];
q.push(trie[cur][i]);
}
else
trie[cur][i] = trie[fail[cur]][i];
}
}
}
bool cmp(string s, string t) {
if (t == "") return true;
if (s.size() < t.size()) return true;
if (s.size() > t.size()) return false;
return s < t;
}
string solve() {
for (int i = 0; i <= n; ++i)
for (int j = 0; j <= pos; ++j)
path[i][j] = "";
int mx = 0;
for (int i = 0; i <= n; ++i) {
for (int j = 0; j <= pos; ++j) {
if (dp[i][j] == -1) continue;
for (int k = 0; k < 26; ++k) {
if (dp[i + 1][trie[j][k]] < dp[i][j] + val[trie[j][k]]) {
dp[i + 1][trie[j][k]] = dp[i][j] + val[trie[j][k]];
path[i + 1][trie[j][k]] = path[i][j] + (char)('a' + k);
}
else if (dp[i + 1][trie[j][k]] == dp[i][j] + val[trie[j][k]]) {
if (cmp(path[i][j] + (char)('a' + k), path[i + 1][trie[j][k]]))
path[i + 1][trie[j][k]] = path[i][j] + (char)('a' + k);
}
}
if (i > 0) mx = max(mx, dp[i][j]);
}
}
if (mx == 0) return "";
string res = "";
for (int i = 1; i <= n; ++i) for (int j = 0; j <= pos; ++j) {
if (dp[i][j] == mx && cmp(path[i][j], res)) {
res = path[i][j];
}
}
return res;
}
int main() {
scanf("%d", &t);
while (t--) {
memset(trie, 0, sizeof(trie));
memset(val, 0, sizeof(val));
memset(dp, -1, sizeof(dp));
pos = cost[0] = dp[0][0] = 0;
scanf("%d%d", &n, &m);
for (int i = 0; i < m; ++i)
scanf("%s", h[i]);
for (int i = 1; i <= m; ++i)
scanf("%d", &cost[i]);
for (int i = 0; i < m; ++i)
insert(h[i], i + 1);
getfail();
cout << solve() << "\n";
}
return 0;
}
原創不易,請勿轉載(
本不富裕的訪問量雪上加霜)
博主首頁:https://blog.csdn.net/qq_45034708
如果文章對你有幫助,記得一鍵三連?
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/143833.html
標籤:其他
上一篇:2006-京淘Day07