在稀疏的、獨熱編碼編碼資料上構建自動編碼器

自1986年[1]問世以來,在過去的30年里,通用自動編碼器神經網路已經滲透到現代機器學習的大多數主要領域的研究中,在嵌入復雜資料方面,自動編碼器已經被證明是非常有效的,它提供了簡單的方法來將復雜的非線性依賴編碼為平凡的向量表示,但是,盡管它們的有效性已經在許多方面得到了證明,但它們在重現稀疏資料方面常常存在不足,特別是當列像一個熱編碼那樣相互關聯時,
在本文中,我將簡要地討論一種熱編碼(OHE)資料和一般的自動編碼器,然后,我將介紹使用在一個熱門編碼資料上受過訓練的自動編碼器所帶來的問題的用例,最后,我將深入討論稀疏OHE資料重構的問題,然后介紹我發現在這些條件下運行良好的3個損失函式:
- CosineEmbeddingLoss
- Sorenson-Dice Coefficient Loss
- Multi-Task Learning Losses of Individual OHE Components
-解決了上述挑戰,包括在PyTorch中實作它們的代碼,
熱編碼資料
熱編碼資料是一種最簡單的,但在一般機器學習場景中經常被誤解的資料預處理技術,該程序將具有“N”不同類別的分類資料二值化為二進制0和1的N列,第N個類別中出現1表示該觀察屬于該類別,這個程序在Python中很簡單,使用Scikit-Learn OneHotEncoder模塊:
from sklearn.preprocessing import OneHotEncoder
import numpy as np# Instantiate a column of 10 random integers from 5 classes
x = np.random.randint(5, size=10).reshape(-1,1)print(x)
>>> [[2][3][2][2][1][1][4][1][0][4]]# Instantiate OHE() + Fit/Transform the data
ohe_encoder = OneHotEncoder(categories="auto")
encoded = ohe_encoder.fit_transform(x).todense()print(encoded)
>>> matrix([[0., 1., 0., 0., 0.],
[0., 0., 0., 1., 0.],
[0., 0., 1., 0., 0.],
[0., 0., 0., 1., 0.],
[0., 0., 1., 0., 0.],
[1., 0., 0., 0., 0.],
[0., 0., 1., 0., 0.],
[0., 0., 1., 0., 0.],
[0., 0., 0., 1., 0.],
[0., 0., 0., 0., 1.]])print(list(ohe_encoder.get_feature_names()))
>>> ["x0_0", "x0_1", "x0_2", "x0_3", "x0_4"]
但是,盡管這個技巧很簡單,但如果不小心,它可能很快就會失效,它可以很容易地為資料添加多余的復雜性,并改變資料上某些分類方法的有效性,例如,轉換成OHE向量的列現在是相互依賴的,這種互動使得在某些型別的分類器中有效地表示資料方面變得困難,例如,如果您有一個包含15個不同類別的列,那么就需要一個深度為15的決策樹來處理該熱編碼列中的if-then模式(當然樹形模型的資料處理是不需要進行獨熱編碼的,這里只是舉例),類似地,由于列是相互依賴的,如果使用bagging (Bootstrap聚合)的分類策略并執行特性采樣,則可能會完全錯過單次編碼的列,或者只考慮它的部分組件類,
Autoencoders
自動編碼器是一種無監督的神經網路,其作業是將資料嵌入到一種有效的壓縮格式,它利用編碼和解碼程序將資料編碼為更小的格式,然后再將更小的格式解碼為原始的輸入表示,利用模型重構(譯碼)與原始資料之間的損失對模型進行訓練,
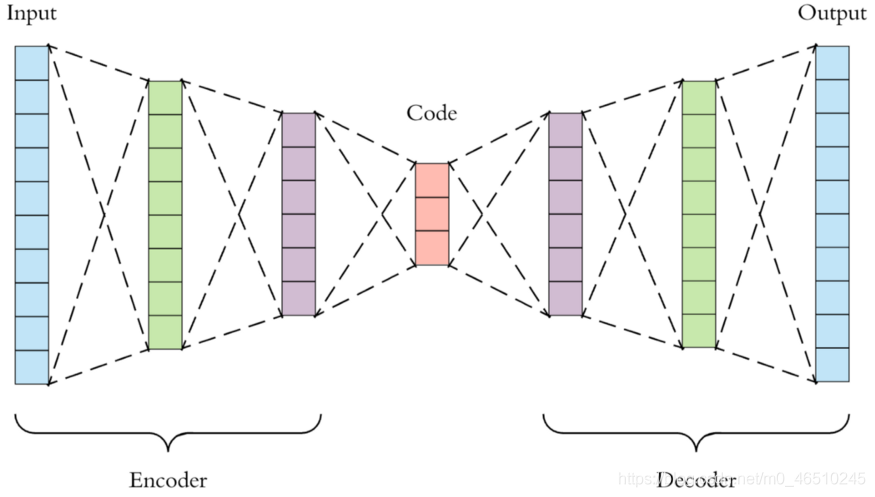
實際上,用代碼表示這個網路也很容易,我們從兩個函式開始:編碼器模型和解碼器模型,這兩個“模型”都被封裝在一個叫做Network的類中,它將包含我們的培訓和評估的整個系統,最后,我們定義了一個Forward函式,PyTorch將它用作進入網路的入口,用于包裝資料的編碼和解碼,
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optimclass Network(nn.Module):
def __init__(self, input_shape: int):
super().__init__()
self.encode1 = nn.Linear(input_shape, 500)
self.encode2 = nn.Linear(500, 250)
self.encode3 = nn.Linear(250, 50)
self.decode1 = nn.Linear(50, 250)
self.decode2 = nn.Linear(250, 500)
self.decode3 = nn.Linear(500, input_shape) def encode(self, x: torch.Tensor):
x = F.relu(self.encode1(x))
x = F.relu(self.encode2(x))
x = F.relu(self.encode3(x))
return x def decode(self, x: torch.Tensor):
x = F.relu(self.decode1(x))
x = F.relu(self.decode2(x))
x = F.relu(self.decode3(x))
return x def forward(self, x: torch.Tensor):
x = encode(x)
x = decode(x)
return x
def train_model(data: pd.DataFrame):
net = Network()
optimizer = optim.Adagrad(net.parameters(), lr=1e-3, weight_decay=1e-4)
losses = [] for epoch in range(250):
for batch in get_batches(data)
net.zero_grad()
# Pass batch through
output = net(batch)
# Get Loss + Backprop
loss = loss_fn(output, batch).sum() #
losses.append(loss)
loss.backward()
optimizer.step()
return net, losses
正如我們在上面看到的,我們有一個編碼函式,它從輸入資料的形狀開始,然后隨著它向下傳播到形狀為50而降低它的維數,從那里,解碼層接受嵌入,然后將其擴展回原來的形狀,在訓練中,我們從譯碼器中取出重構的結果,并取出重構與原始輸入的損失,
損失函式的問題
所以現在我們已經討論了自動編碼器的結構和一個熱編碼程序,我們終于可以討論與使用一個熱編碼在自動編碼器相關的問題,以及如何解決這個問題,當一個自動編碼器比較重建到原始輸入資料,必須有一些估值之間的距離提出重建和真實的價值,通常,在輸出值被認為互不相干的情況下,將使用交叉熵損失或MSE損失,但在我們的一個熱編碼的情況下,有幾個問題,使系統更復雜:
- 一列出現1意味著對應的OHE列必須有一個0,即列不是不相交的
- OHE向量輸入的稀疏性會導致系統選擇簡單地將大多數列回傳0以減少誤差
這些問題結合起來導致上述兩個損失(MSE,交叉熵)在重構稀疏OHE資料時無效,下面我將介紹三種損失,它們提供了一個解決方案,或上述問題,并在PyTorch實作它們的代碼:
余弦嵌入損失
余弦距離是一種經典的向量距離度量,常用于NLP問題中比較字包表示,通過求兩個向量之間的余弦來計算距離,計算方法為:

由于該方法能夠考慮到各列中二進制值的偏差來評估兩個向量之間的距離,因此在稀疏嵌入重構中,該方法能夠很好地量化誤差,這種損失是迄今為止在PyTorch中最容易實作的,因為它在 Torch.nn.CosineEmbeddingLoss中有一個預先構建的解決方案
loss_function = torch.nn.CosineEmbeddingLoss(reduction='none')# . . . Then during training . . . loss = loss_function(reconstructed, input_data).sum()
loss.backward()
Dice Loss
Dice Loss是一個實作S?rensen-Dice系數[2],這是非常受歡迎的計算機視覺領域的分割任務,簡單地說,它是兩個集合之間重疊的度量,并且與兩個向量之間的Jaccard距離有關,骰子系數對向量中列值的差異高度敏感,利用這種敏感性有效地區分影像中像素的邊緣,因此在影像分割中非常流行,Dice Loss為:
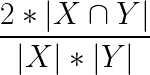
PyTorch沒有內部實作的Dice Loss,但是在Kaggle上可以在其丟失函式庫- Keras & PyTorch[3]中找到一個很好的實作:
class DiceLoss(nn.Module):
def __init__(self, weight=None, size_average=True):
super(DiceLoss, self).__init__()
def forward(self, inputs, targets, smooth=1):
#comment out if your model contains a sigmoid acitvation
inputs = F.sigmoid(inputs)
#flatten label and prediction tensors
inputs = inputs.view(-1)
targets = targets.view(-1)
intersection = (inputs * targets).sum()
dice = (2.*intersection + smooth)/
(inputs.sum() + targets.sum() + smooth)
return 1 - dice
不同OHE列的單個損失函式
最后,您可以將每個熱編碼列視為其自身的分類問題,并承擔每個分類的損失,這是一個多任務學習問題的用例,其中autoencoder正在解決重構輸入向量的各個分量的問題,當你有幾個/所有的列在你的輸入資料時,這個作業最好,例如,如果您有一個編碼列,前7列是7個類別:您可以將其視為一個多類分類問題,并將損失作為子問題的交叉熵損失,然后,您可以將子問題的損失合并在一起,并將其作為整個批的損失向后傳遞,
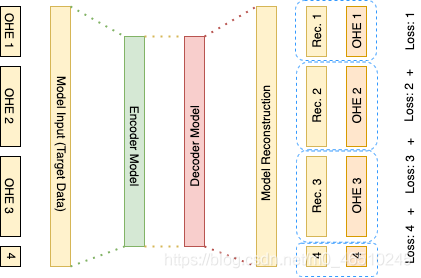
下面您將看到這個程序的示例,其中示例有三個熱編碼的列,每個列有50個類別,
from torch.nn.modules import _Loss
from torch import argmaxclass CustomLoss(_Loss):
def __init__(self):
super(CustomLoss, self).__init__() def forward(self, input, target):
""" loss function called at runtime """
# Class 1 - Indices [0:50]
class_1_loss = F.nll_loss(
F.log_softmax(input[:, 0:50], dim=1),
argmax(target[:, 0:50])
) # Class 2 - Indices [50:100]
class_2_loss = F.nll_loss(
F.log_softmax(input[:, 50:100], dim=1),
argmax(target[:, 50:100])
) # Class 3 - Indices [100:150]
class_3_loss = F.nll_loss(
F.log_softmax(input[:, 100:150], dim=1),
argmax(target[:, 100:150])
) return class_1_loss + class_2_loss + class_3_loss
在上面的代碼中,您可以看到重構輸出的子集是如何承受個體損失的,然后在最后將其合并為一個總和,這里我們使用了一個負對數似然損失(nll_loss),它是一個很好的損失函式用于多類分類方案,并與交叉熵損失有關,
總結
在本文中,我們瀏覽了一個獨熱編碼分類變數的概念,以及自動編碼器的一般結構和目標,我們討論了一個熱編碼向量的缺點,以及在嘗試訓練稀疏的、一個獨熱編碼資料的自編碼器模型時的主要問題,最后,我們討論了解決稀疏一熱編碼問題的3個損失函式,訓練這些網路并沒有更好或更壞的損失,在我所介紹的功能中,沒有辦法知道哪個是適合您的用例的,除非您嘗試它們!
下面我提供了一些深入討論上述主題的資源,以及一些我提供的關于丟失函式的資源,
資源
- D.E. Rumelhart, G.E. Hinton, and R.J. Williams, “Learning internal representations by error propagation.” Parallel Distributed Processing. Vol 1: Foundations. MIT Press, Cambridge, MA, 1986.
- S?rensen, T. (1948). “A method of establishing groups of equal amplitude in plant sociology based on similarity of species and its application to analyses of the vegetation on Danish commons”. Kongelige Danske Videnskabernes Selskab. 5 (4): 1–34. *AND* Dice, Lee R. (1945). “Measures of the Amount of Ecologic Association Between Species”. Ecology. 26 (3): 297–302.
- Kaggle’s Loss Function Library: https://www.kaggle.com/bigironsphere/loss-function-library-keras-pytorch
作者:Nick Hespe
deephub翻譯組
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/144727.html
標籤:其他
上一篇:玩轉華為云,ModelArts深度學習建模最全搭建手冊
下一篇:NLP頂會論文寫作技巧個人總結!