文章目錄
- BP推導全程序
- 一些變數的含義
- 一些公式
- 開始推導
- 任意層BP網路代碼實作
- 運行結果如
BP推導全程序
最近老師布置了一個神經網路的作業,正好練習下LaTeX,順便寫了這個博客
BP的整個程序還是很嚴謹的、LaTeX寫公式也很好用,建議一步步跟著公式走
另外還配上了代碼供食用,代碼配公式、效果更好
一些變數的含義
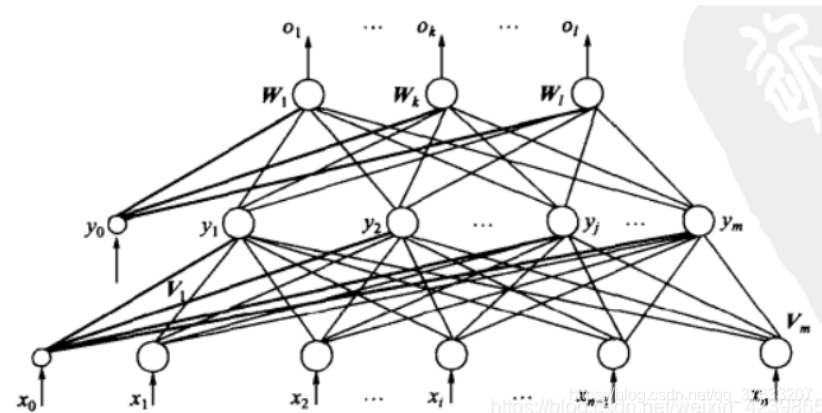
這里的的網路采用三層感知機結構
以簡單的sigmod函式如為例:
f
(
x
)
=
1
1
+
e
?
x
f
(
x
)
′
=
f
(
x
)
(
1
?
f
(
x
)
)
f (x)=\frac {1}{1+e^{-x}}\\ f(x)'=f(x)(1-f(x))
f(x)=1+e?x1?f(x)′=f(x)(1?f(x))
下面定義一些變數
輸
入
向
量
X
=
(
x
1
,
x
2
,
?
x
n
)
T
隱
層
輸
出
向
量
Y
=
(
y
1
,
y
2
,
?
y
m
)
T
輸
入
層
到
隱
層
的
權
重
V
V
=
(
V
1
,
V
2
,
?
?
,
V
m
)
這
里
的
V
j
,
j
∈
(
1
,
?
?
,
m
)
是
下
面
矩
陣
的
列
向
量
表
達
式
為
:
f
(
V
j
?
X
)
=
Y
j
V
=
[
v
11
v
12
?
v
1
m
v
21
v
22
?
v
2
m
v
31
v
32
?
v
3
m
?
?
?
?
v
n
1
v
n
2
?
v
n
m
]
輸
出
層
向
量
O
=
(
o
1
,
o
2
,
?
?
,
o
l
)
T
真
實
標
簽
D
=
(
d
1
,
d
2
,
?
?
,
d
l
)
T
隱
含
層
到
輸
出
層
的
權
重
W
W
=
(
W
1
,
W
2
,
?
?
,
W
l
)
W
k
,
k
∈
(
1
,
?
?
,
l
)
為
下
面
矩
陣
的
第
k
個
列
向
量
W
=
[
w
11
w
12
?
w
1
l
w
21
w
22
?
w
2
l
w
31
w
32
?
w
3
l
?
?
?
?
w
m
1
w
n
2
?
w
m
l
]
下
面
公
式
表
示
的
是
隱
藏
層
到
輸
出
層
的
過
程
f
(
W
k
?
Y
)
=
O
k
輸入向量X=(x_1,x_2,\cdots x_n)^T \\ 隱層輸出向量Y=(y_1,y_2,\cdots y_m)^T\\ 輸入層到隱層的權重V\\ V=(V_1,V_2,\cdots,V_m)\\ 這里的V_j,j\in (1,\cdots,m)是下面矩陣的列向量\\ 運算式為:f(V_j \cdot X)=Y_j\\ V=\left[ \begin{array}{ccc} v_{11} & v_{12} & \cdots & v_{1m}\\ v_{21} & v_{22} & \cdots & v_{2m}\\ v_{31} & v_{32} & \cdots & v_{3m}\\ \cdots & \cdots&\cdots & \cdots \\ v_{n1} & v_{n2} & \cdots & v_{nm}\\ \end{array} \right]\\ \\ 輸出層向量O=(o_1,o_2,\cdots,o_l)^{T}\\ 真實標簽D=(d_1,d_2,\cdots,d_l)^T\\ 隱含層到輸出層的權重W\\ W=(W_1,W_2,\cdots,W_l)\\ W_k,k\in(1,\cdots,l)為下面矩陣的第k個列向量\\ W=\left[ \begin{array}{ccc} w_{11} & w_{12} & \cdots & w_{1l}\\ w_{21} & w_{22} & \cdots & w_{2l}\\ w_{31} & w_{32} & \cdots & w_{3l}\\ \cdots & \cdots&\cdots & \cdots \\ w_{m1} & w_{n2} & \cdots & w_{ml}\\ \end{array} \right]\\ 下面公式表示的是隱藏層到輸出層的程序 f(W_k\cdot Y)=O_k
輸入向量X=(x1?,x2?,?xn?)T隱層輸出向量Y=(y1?,y2?,?ym?)T輸入層到隱層的權重VV=(V1?,V2?,?,Vm?)這里的Vj?,j∈(1,?,m)是下面矩陣的列向量表達式為:f(Vj??X)=Yj?V=???????v11?v21?v31??vn1??v12?v22?v32??vn2????????v1m?v2m?v3m??vnm?????????輸出層向量O=(o1?,o2?,?,ol?)T真實標簽D=(d1?,d2?,?,dl?)T隱含層到輸出層的權重WW=(W1?,W2?,?,Wl?)Wk?,k∈(1,?,l)為下面矩陣的第k個列向量W=???????w11?w21?w31??wm1??w12?w22?w32??wn2????????w1l?w2l?w3l??wml?????????下面公式表示的是隱藏層到輸出層的過程f(Wk??Y)=Ok?
一些公式
對于輸出層有(后面兩個式子不過是展開了內積而已,本質一樣):
o
k
=
f
(
n
e
t
k
)
=
f
(
∑
j
=
0
m
w
j
k
y
j
)
=
f
(
W
k
Y
)
(
1
)
o_k=f(net_k)=f(\sum_{j=0}^mw_{jk}y_j)=f(W_kY) \quad \quad \quad (1)
ok?=f(netk?)=f(j=0∑m?wjk?yj?)=f(Wk?Y)(1)
對于隱含層
y
j
=
f
(
n
e
t
j
)
=
f
(
∑
i
=
0
n
v
i
j
x
i
)
=
f
(
V
j
X
)
(
2
)
y_j=f(net_j)=f(\sum_{i=0}^nv_{ij}x_i)=f(V_jX) \quad \quad \quad (2)
yj?=f(netj?)=f(i=0∑n?vij?xi?)=f(Vj?X)(2)
對于輸出層的梯度更新公式:
輸
出
層
梯
度
更
新
量
Δ
w
j
k
=
?
η
?
E
?
w
j
k
w
j
k
=
w
j
k
+
Δ
w
j
k
=
w
j
k
?
η
?
E
?
w
j
k
(
3
)
輸出層梯度更新量\quad\quad\Delta w_{jk}=-\eta \frac{\partial E}{\partial w_{jk}} \\ w_{jk}=w_{jk}+\Delta w_{jk}=w_{jk}-\eta\frac{\partial E}{\partial w_{jk}} \quad \quad(3)
輸出層梯度更新量Δwjk?=?η?wjk??E?wjk?=wjk?+Δwjk?=wjk??η?wjk??E?(3)
對于隱藏層的更新公式
隱
藏
層
梯
度
更
新
量
Δ
v
i
j
=
?
η
?
E
?
v
i
j
v
i
j
=
v
i
j
+
Δ
v
i
j
=
v
i
j
?
η
?
E
?
v
i
j
(
4
)
隱藏層梯度更新量\quad\quad\Delta v_{ij}=-\eta \frac{\partial E}{\partial v_{ij}} \\ v_{ij}=v_{ij}+\Delta v_{ij}=v_{ij}-\eta\frac{\partial E}{\partial v_{ij}} \quad\quad\quad(4)
隱藏層梯度更新量Δvij?=?η?vij??E?vij?=vij?+Δvij?=vij??η?vij??E?(4)
最后的誤差公式的展開如下
E
=
1
2
∑
k
=
1
l
(
d
k
?
o
k
)
2
把
公
式
(
1
)
(
2
)
帶
入
=
1
2
∑
k
=
1
l
(
d
k
?
f
[
∑
j
=
0
m
w
j
k
f
(
n
e
t
j
)
]
)
2
=
1
2
∑
k
=
1
l
(
d
k
?
f
[
∑
j
=
0
m
w
j
k
f
(
∑
i
=
0
n
v
i
j
x
i
)
]
)
2
(
5
)
E=\frac{1}{2}\sum_{k=1}^l(d_k-o_k)^2 \quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\\ 把公式(1)(2)帶入\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\\ =\frac{1}{2}\sum_{k=1}^l(d_k-f[\sum_{j=0}^m w_{jk}f(net_j)])^2 \quad\quad\quad\quad\quad\quad\\ =\frac{1}{2} \sum_{k=1}^l (d_k-f[\sum_{j=0}^m w_{jk}f(\sum_{i=0}^nv_{ij}x_i)])^2\quad\quad\quad(5)
E=21?k=1∑l?(dk??ok?)2把公式(1)(2)帶入=21?k=1∑l?(dk??f[j=0∑m?wjk?f(netj?)])2=21?k=1∑l?(dk??f[j=0∑m?wjk?f(i=0∑n?vij?xi?)])2(5)
開始推導
由上面的公式(3)(4)可知我們只要求出那兩個梯度更新量就行了
- 對于輸出層的梯度更新量,我們利用鏈式求導可以得到下面的公式
Δ w j k = ? η ? E ? w j k = ? η ? E ? n e t k ? n e t k ? w j k 由 公 式 ( 1 ) 可 知 ? n e t k ? w j k = y j 即 Δ w j k = ? η ? E ? n e t k y j ( 6 ) \Delta w_{jk}=-\eta \frac{\partial E}{\partial w_{jk}}=-\eta\frac{\partial E}{\partial net_k}\frac{\partial net_k}{\partial w_{jk}}\\ 由公式(1)可知 \frac{\partial net_k}{\partial w_{jk}}=y_j\\ 即\Delta w_{jk}=-\eta\frac{\partial E}{\partial net_k}y_j \quad\quad\quad(6)\\ Δwjk?=?η?wjk??E?=?η?netk??E??wjk??netk??由公式(1)可知?wjk??netk??=yj?即Δwjk?=?η?netk??E?yj?(6) - 對于隱藏層的梯度更新量,也是如此
- Δ v i j = ? η ? E ? v i j = ? η ? E ? n e t j ? n e t j ? v i j 由 公 式 ( 2 ) 可 知 ? n e t j ? v i j = x i 即 Δ v i j = ? η ? E ? n e t j x i ( 7 ) 實 際 代 碼 中 我 們 求 x i 和 y j 輕 輕 松 松 , 只 要 保 存 網 絡 每 層 的 輸 出 即 可 而 且 我 們 都 是 批 量 更 新 , 批 量 更 新 效 率 更 高 \Delta v_{ij}=-\eta \frac{\partial E}{\partial v_{ij}}=-\eta\frac{\partial E}{\partial net_j}\frac{\partial net_j}{\partial v_{ij}}\\ 由公式(2)可知 \frac{\partial net_j}{\partial v_{ij}}=x_i\\ 即\Delta v_{ij}=-\eta\frac{\partial E}{\partial net_j}x_i\quad\quad\quad(7)\\ 實際代碼中我們求x_i 和y_j輕輕松松,只要保存網路每層的輸出即可\\ 而且我們都是批量更新,批量更新效率更高 Δvij?=?η?vij??E?=?η?netj??E??vij??netj??由公式(2)可知?vij??netj??=xi?即Δvij?=?η?netj??E?xi?(7)實際代碼中我們求xi?和yj?輕輕松松,只要保存網絡每層的輸出即可而且我們都是批量更新,批量更新效率更高
- 所以我們只要求出下面兩個公式即可求出對于每一層的梯度更新量
我 們 把 ? ? E ? n e t k 設 為 e r r o 意 思 為 輸 出 層 的 誤 差 信 號 再 把 ? ? E ? n e t j 設 為 e r r y 意 思 為 隱 含 層 層 的 誤 差 信 號 e r r o 和 e r r y 展 開 可 得 : e r r o = ? ? E ? n e t k = ? ? E ? o k ? o k ? n e t k 把 公 式 ( 1 ) ( 5 ) 代 入 上 公 式 可 得 e r r o = ? ? E ? o k f ( n e t k ) ′ = ∑ k = 1 l ( d k ? o k ) o k ( 1 ? o k ) ( 8 ) 可 以 看 出 來 輸 出 層 的 誤 差 信 號 還 是 非 常 好 求 的 e r r y 稍 微 復 雜 點 , 我 們 還 是 先 把 他 展 開 e r r y = ? ? E ? n e t j = ? ? E ? y j ? y j ? n e t j = ? ? E ? o k ? o k ? y j ? y j ? n e t j = ? ? E ? o k ? o k ? n e t k ? n e t k ? y j ? y j ? n e t j 上 面 這 幾 個 求 偏 導 的 公 式 都 有 我 們 只 需 要 帶 入 公 式 ( 1 ) ( 2 ) ( 5 ) 可 得 e r r y = ∑ k = 0 l ( d k ? o k ) ? o k ( 1 ? o k ) ? w j k ? y j ( 1 ? y j ) ( 9 ) 我 們 觀 察 可 以 發 現 e r r y 的 一 部 分 和 e r r o 一 模 一 樣 , 所 以 把 公 式 ( 8 ) 帶 入 ( 9 ) 得 e r r y = e r r o w j k y j ( 1 ? y j ) ( 10 ) 對 于 寫 代 碼 來 說 , 我 們 只 要 求 出 e r r o 后 , 后 面 一 系 列 的 隱 藏 層 都 非 常 好 求 只 要 用 從 后 向 前 計 算 每 一 層 的 誤 差 信 號 即 可 我們把-\frac{\partial E}{\partial net_k}設為err_o\quad意思為輸出層的誤差信號\\ 再把-\frac{\partial E}{\partial net_j}設為err_y\quad意思為隱含層層的誤差信號\\ err_o和err_y展開可得:\\ err_o=-\frac{\partial E}{\partial net_k}=-\frac{\partial E}{\partial o_k}\frac{\partial o_k}{\partial net_k}\\把公式(1)(5)代入上公式可得 \\ err_o=-\frac{\partial E}{\partial o_k}f(net_k)'=\sum_{k=1}^l(d_k-o_k)o_k(1-o_k)\quad\quad(8)\\ 可以看出來輸出層的誤差信號還是非常好求的\\ err_y稍微復雜點,我們還是先把他展開\\ err_y=-\frac{\partial E}{\partial net_j}\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\\ =-\frac{\partial E}{\partial y_j}\frac{\partial y_j}{\partial net_j}\quad\quad\quad\quad\quad\quad\\ =-\frac{\partial E}{\partial o_k}\frac{\partial o_k}{\partial y_j}\frac{\partial y_j}{\partial net_j}\quad\quad\quad\quad\\ =-\frac{\partial E}{\partial o_k}\frac{\partial o_k}{\partial net_k}\frac{\partial net_k}{\partial y_j}\frac{\partial y_j}{\partial net_j}\quad\\ 上面這幾個求偏導的公式都有我們只需要帶入公式(1)(2)(5)可得\\ err_y=\sum_{k=0}^l(d_k-o_k)\cdot o_k(1-o_k)\cdot w_{jk} \cdot y_j(1-y_j)\quad(9)\\ 我們觀察可以發現err_y的一部分和err_o一模一樣,所以把公式(8)帶入(9)\\ 得err_y=err_ow_{jk}y_j(1-y_j)\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad(10)\\ 對于寫代碼來說,我們只要求出err_o后,后面一系列的隱藏層都非常好求\\ 只要用從后向前計算每一層的誤差信號即可\\ 我們把??netk??E?設為erro?意思為輸出層的誤差信號再把??netj??E?設為erry?意思為隱含層層的誤差信號erro?和erry?展開可得:erro?=??netk??E?=??ok??E??netk??ok??把公式(1)(5)代入上公式可得erro?=??ok??E?f(netk?)′=k=1∑l?(dk??ok?)ok?(1?ok?)(8)可以看出來輸出層的誤差信號還是非常好求的erry?稍微復雜點,我們還是先把他展開erry?=??netj??E?=??yj??E??netj??yj??=??ok??E??yj??ok???netj??yj??=??ok??E??netk??ok???yj??netk???netj??yj??上面這幾個求偏導的公式都有我們只需要帶入公式(1)(2)(5)可得erry?=k=0∑l?(dk??ok?)?ok?(1?ok?)?wjk??yj?(1?yj?)(9)我們觀察可以發現erry?的一部分和erro?一模一樣,所以把公式(8)帶入(9)得erry?=erro?wjk?yj?(1?yj?)(10)對于寫代碼來說,我們只要求出erro?后,后面一系列的隱藏層都非常好求只要用從后向前計算每一層的誤差信號即可 - 那么我們最終的結果就是如下公式
Δ w j k = η ? e r r o ? y j Δ v i j = η ? e r r o w j k y j ( 1 ? y j ) ? x i 寫 成 代 碼 用 向 量 批 量 計 算 的 話 就 是 如 下 所 示 Δ w = η ? ( s u m ( D ? O ) ? O ( 1 ? O ) ) ? Y Δ v = η ? ( s u m ( D ? O ) ? O ( 1 ? O ) ) W ? Y ? X \Delta w_{jk}=\eta\cdot err_o \cdot y_j\\ \Delta v_{ij}=\eta\cdot err_o w_{jk} y_j (1-y_j)\cdot x_i \\ 寫成代碼用向量批量計算的話就是如下所示\\ \Delta w=\eta\cdot (sum(D-O)\cdot O(1-O)) \cdot Y\\ \Delta v=\eta\cdot (sum(D-O)\cdot O(1-O)) W\cdot Y\cdot X \\ Δwjk?=η?erro??yj?Δvij?=η?erro?wjk?yj?(1?yj?)?xi?寫成代碼用向量批量計算的話就是如下所示Δw=η?(sum(D?O)?O(1?O))?YΔv=η?(sum(D?O)?O(1?O))W?Y?X
任意層BP網路代碼實作
參考這位老哥的代碼: https://www.k2zone.cn/?p=1047
import numpy as np
def logistic(x):
return 1/(1+np.exp(-x))
def logistic_derivative(x):
return logistic(x) * (1 - logistic(x))
def tanh(x):
return np.tanh(x)
def tanh_deriv(x):
return 1.0 - np.tanh(x) * np.tanh(x)
class NeuralNetwork:
#建構式
def __init__(self, layers, activation='tanh'):
'''
:param layers: list型別,比如[2,2.1]代表輸入層有兩個神經元,隱藏層有兩個,輸出層有一個
:param activation: 激活函式
'''
self.layers = layers
#選擇后面用到的激活函式
if activation == 'logistic':
self.activation = logistic
self.activation_deriv = logistic_derivative
elif activation == 'tanh':
self.activation = tanh
self.activation_deriv = tanh_deriv
#定義網路的層數
self.num_layers = len(layers)
'''
生成除輸入層外的每層中神經元的biase值,在(-1,1)之間,每一層都是一行一維陣列資料
randn函式執行一次生成x行y列的資料
'''
self.biases = [np.random.randn(x) for x in layers[1:]]
print("初始偏向:",self.biases)
'''
隨機生成每條連接線的權重,在(-1,1)之間
weights[i-1]代表第i層和第i-1層之間的權重,元素個數等于i層神經元個數
weights[i-1][0]表示第i層中第一個神經單元和第i-1層每個神經元的權重,元素個數等于i-1層神經元個數
'''
self.weights = [np.random.randn(y, x)
for x, y in zip(layers[:-1], layers[1:])]
print("初始權重:",self.weights)
#訓練模型,進行建模
def fit(self, X, y, learning_rate=0.2, epochs=1):
'''
:param self: 當前物件指標
:param X: 訓練集
:param y: 訓練標記
:param learning_rate: 學習率
:param epochs: 訓練次數
:return: void
'''
for k in range(epochs):
#每次迭代都回圈一次訓練集
for i in range(len(X)):
#存盤本次的輸入和后幾層的輸出
activations = [X[i]]
#向前一層一層的走
for b, w in zip(self.biases, self.weights):
# print "w:",w
# print "activations[-1]:",activations[-1]
# print "b:", b
#計算激活函式的引數,計算公式:權重.dot(輸入)+偏向
z = np.dot(w, activations[-1])+b
#計算輸出值
output = self.activation(z)
#將本次輸出放進輸入串列,后面更新權重的時候備用
activations.append(output)
# print "計算結果",activations
#計算誤差值
"""
下面這行代碼參考公式8
"""
error = y[i]-activations[-1]
"""
計算輸出層誤差率
參考公式9
"""
deltas = [error * self.activation_deriv(activations[-1])]
#回圈計算隱藏層的誤差率,從倒數第2層開始
for l in range(self.num_layers-2, 0, -1):
# print "第l層的權重",self.weights[l]
# print "l+1層的誤差率",deltas[-1]
deltas.append(self.activation_deriv(activations[l]) * np.dot( deltas[-1],self.weights[l]))
#將各層誤差率順序顛倒,準備逐層更新權重和偏向
deltas.reverse()
"""
更新權重和偏向
參考公式3、4
"""
for j in range(self.num_layers-1):
#本層結點的輸出值
layers = np.array(activations[j])
# print "本層輸出:",layers
# print "錯誤率:",deltas[j]
# 權重的增長量,計算公式,增長量 = 學習率 * (錯誤率.dot(輸出值))
delta = learning_rate * ((np.atleast_2d(deltas[j]).T).dot(np.atleast_2d(layers)))
#更新權重
self.weights[j] += delta
#print "本層偏向:",self.biases[j]
#偏向增加量,計算公式:學習率 * 錯誤率
delta = learning_rate * deltas[j]
#print np.atleast_2d(delta).T
#更新偏向
self.biases[j] += delta
#print self.weights
def predict(self, x):
'''
:param x: 測驗集
:return: 各型別的預測值
'''
for b, w in zip(self.biases, self.weights):
# 計算權重相加再加上偏向的結果
z = np.dot(w, x) + b
# 計算輸出值
x = self.activation(z)
return x
nn = NeuralNetwork([2,4,3,1], 'tanh')
#訓練集
X = np.array([[0, 0], [0, 1], [1, 0],[1, 1]])
#lanbel標記
y = np.array([0, 1, 1, 0])
#建模
nn.fit(X, y, epochs=2000)
#預測
for i in [[0, 0], [0, 1], [1, 0], [1,1]]:
print(i, nn.predict(i))
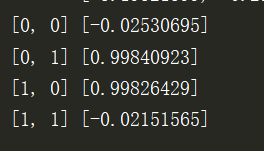
運行結果如
轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/149224.html
標籤:其他